GALAXY: A Generative Pre-trained Model for Task-Oriented Dialog with Semi-Supervised Learning and Explicit Policy Injection
简介:
本文发表于AAAI 2022,如何将人类先验知识低成本融入到预训练模型中一直是个难题。达摩院对话智能团队提出了一种基于半监督预训练的新训练范式,通过半监督的方式将对话领域的少量有标数据和海量无标数据一起进行预训练,将标注数据中蕴含的知识注入到预训练模型中去,新提出的半监督预训练对话模型(Semi-Supervised Pre-trAined Conversation ModEl)SPACE 1.0 版本在剑桥 MultiWOZ2.0,亚马逊 MultiWOZ2.1 等经典对话数据集上取得了 5%+ 显著效果提升。
0. 引言
随着深度学习的迅猛发展,学术界每年都会有许多高质量标注数据集被公开,如文本分类、情感分析等等,同时工业界也会积累沉淀面向任务的各类标注数据,怎样将储存在标注数据中的特定任务知识注入到预训练模型中,从而带来该类任务的普遍效果提升,就成为一个重要的研究方向。
本文从将预训练模型的两大经典范式简介开始,围绕预训练语言模型学到哪些知识、如何向预训练模型注入知识展开,然后重点介绍预训练对话模型及达摩院对话智能团队在半监督预训练对话模型方面的进展,最后对未来研究方向作出展望。
1 预训练模型的两大范式
1.1有监督预训练
神经网络模型的预训练一直是深度学习中备受关注的问题。最早的研究可追溯到 Hinton 教授在 2006 年提出的一种基于受限玻尔兹曼机优化的贪心算法 [2],该方法利用无标数据针对深度信度网络(Deep Belief Nets, DBN)进行一层层地初始化,从而能够保证较深的网络在下游任务上也能快速收敛。随着大数据的兴起和算力的提升,人们逐渐发现直接在具有高度相关性的大型有标数据集上进行有监督预训练,然后再某个特定下游任务进行迁移学习能够带来更强的表现,比较常见的工作是利用 VGG,ResNet 等超深模型在 ImageNet 上进行预训练,将有关图像分类的专家标注的大量经验知识注入到模型的参数中,从而在目标追踪、图片分割等其他相关任务上进行更好地适应学习。
1.2无监督预训练
近一两年里,随着预训练语言模型的兴起,利用自监督的方式在无标数据上针对鉴别式模型构造有监督损失函数进行超大规模的自监督预训练成为了新的主流,例如在自然语言处理领域中,BERT 使用基于上下文的词 token 预测可以训练出很好的自然语言表征,在大量 NLP 任务上都得到了效果验证 [3];而在计算机视觉领域中,近期以 ViT [4] 为基础的一系列工作,也利用了类似 BERT 的 transformer 结构进行图片 patch 重建的预训练,从而习得良好的图片表征,并在 imagenet-1K 等图片分类数据集上取得显著提升。
清华研究者们在综述 [5] 中从迁移学习的角度来统一审视了目前已有的两大预训练范式,如下图 1 所示,无论是有监督预训练还是自监督预训练,归根结底都是直接从数据中学出更加合理的分布式表示,从而能够更好地迁移适配到具体的下游任务。
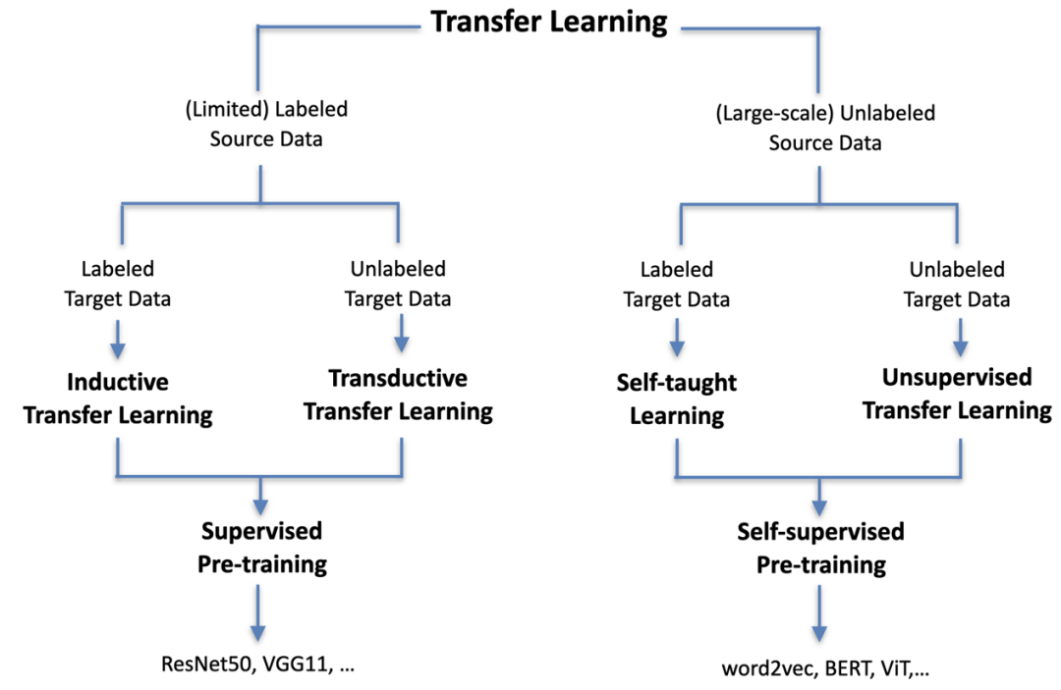
图1 神经网络预训练两大范式
2预训练语言模型学会了什么
2.1模型的知识探测
依目前发展来看,以 BERT 为代表的自监督预训练已经成为了研究主流。论文 [6] 曾对 BERT 模型 “庖丁解牛”,通过知识探测的手段,深入地探究了每一层的注意力权重的关系(如图 2 所示),发现不同层的不同注意力头(attention head)都对不同的语言特征敏感,例如有的注意力头对于定冠词修饰的名词敏感,有的注意力头对于被动语态关注度更高,有的则在一定程度上实现了长距离指代消解。
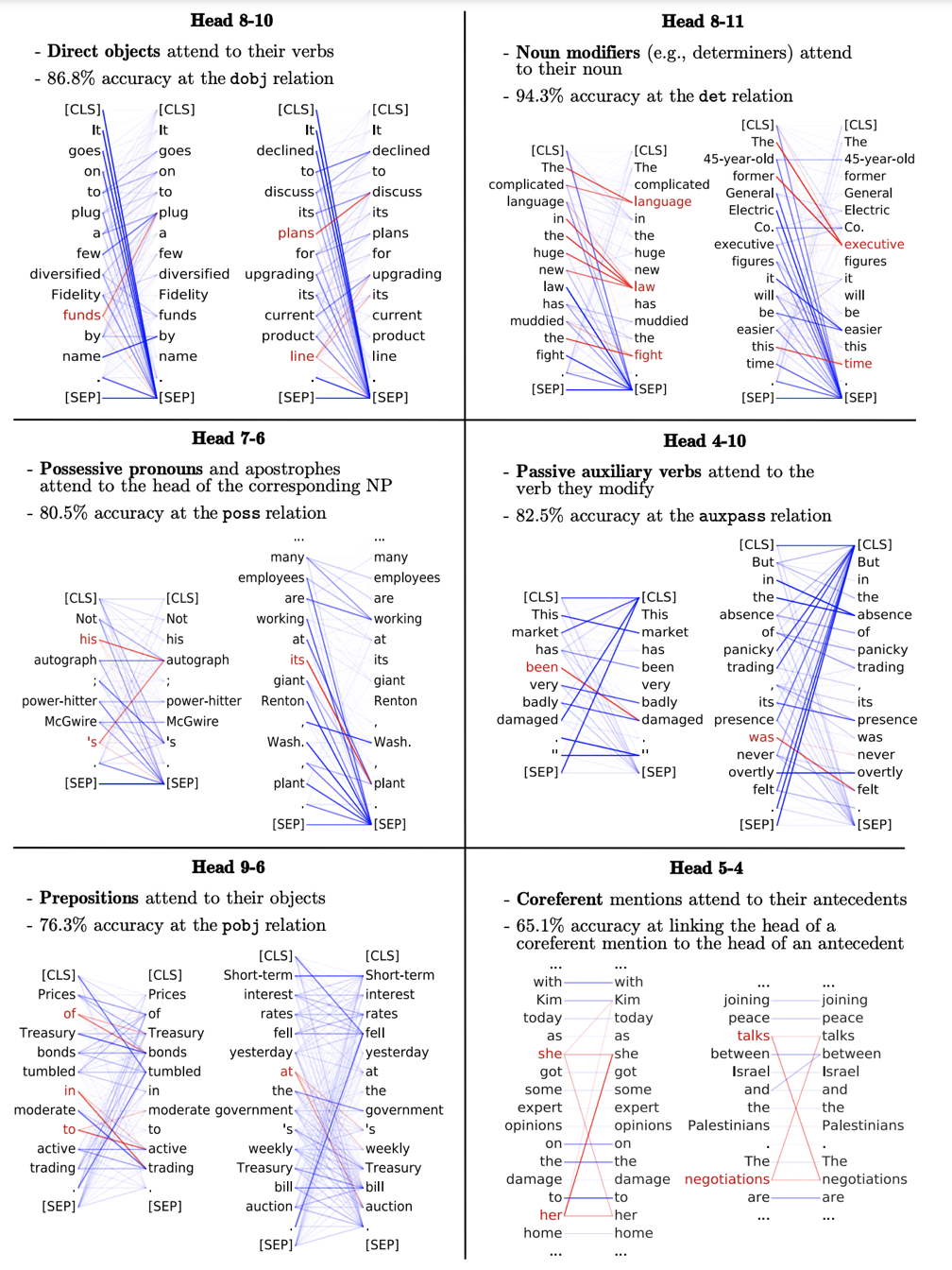
图 2:解析 BERT 不同注意力头的权重图 (引自 [6])
预训练的本质是将训练数据中蕴含的信息以模型可理解的方式隐含地存储到参数中 [5],不少研究工作已经表明 [7][8][9],预训练模型如 BERT 能够学习到较好的语言学知识(句法、语法),甚至一定程度上的世界知识和常识知识。但是预训练模型在如何更好地学习利用人类经验知识上依旧存在不少问题,需要更多的研究与探索,例如如何对其进行更好的建模,如何更有效地进行预训练,如何评价知识融入的程度等等。
2.2人类经验知识
这里,我们将人类经验知识粗略分为三类:
第一类是事实型知识,例如人工构建的知识表格、知识图谱和结构化文档(包含篇章结构、图文信息)。目前已经有一些预训练的工作针对这类知识进行更好地利用,例如达摩院不久前开源的最大中文预训练表格模型(详见《达摩院开源中文社区首个表格预训练模型,取得多个基准 SOTA》一文);清华的 KEPLER [12] 和北大的 K-BERT [11] 是通过将三元组融合到神经网络输入并引入新的损失函数或结构来实现图谱知识的有效融入;微软的 LayoutLM 系列模型 [13] 和 Adobe 的 UDoc [14] 则研究了如何针对结构化文档进行预训练。
第二类是数理逻辑知识,包括数理公式、公理定理、符号计算等,这一类知识不作为本文讨论内容。
第三类是标注知识,即标注数据中蕴含的知识。这类知识十分普遍,属于任务相关的,例如文本分类、情感分析等。人类在标注过程中需要根据该特定的任务进行归纳总结,在预先定义的高层语义分类空间中对无标数据进行推断并赋值相应的标签。因此,利用标注知识来增强预训练模型理应会对相关下游任务带来明显效果提升。
3如何注入人类标注知识
尽管现在各类预训练模型包打天下,但是如何向模型中注入标注知识依旧是一个尚未充分探索的方向。早期工作中,谷歌的 T5 [16] 就已经尝试了将有标和无标数据统一成语言生成任务进行学习,但是实验却表明简单地混合有标无标数据训练反而会带来负面影响。
经过大量的实验探索,我们发现如果还是基于原先的两大预训练范式,是难以很好地进行预训练的。首先,单利用自监督预训练或者有监督预训练是无法同时利用好有标和无标的预训练数据,因为仅仅自监督损失函数是无法学习出标注知识中的高层语义的,有监督损失函数亦不能学出无标语料中的通用底层语义;其次,在大规模预训练中,由于所使用的预训练数据往往存在着少量有标数据和海量无标数据之间的数量鸿沟,如果简单混合两种预训练,会使得标注知识的信息要么淹没在无标数据中,要么就会出现严重的过拟合,因此我们需要全新的预训练范式来解决该问题。
这里,我们提出半监督预训练。如图 3 所示,半监督预训练从迁移学习的角度来看,可以认为是一个前两种范式的自然延伸,通过构造半监督学习的损失函数来充分综合利用有限的标注知识和大量的无标数据。在半监督学习理论里 [17],模型既需要在无标数据上进行自我推断,根据结果进一步约束优化,也需要利用有标数据进行一定程度的有监督,指导自监督预训练的过程,同时避免模型参数陷入平凡解。
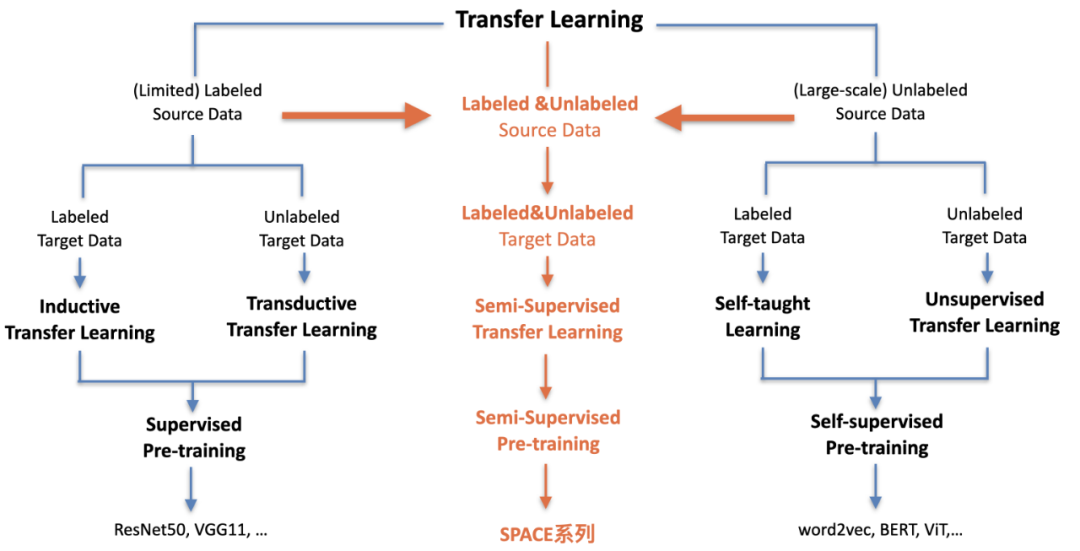
图 3:半监督预训练新范式
本工作率先将半监督预训练的思路应用在了对话领域,提出了半监督预训练对话模型,在 MultiWoz 等国际经典对话数据集上取得了显著提升,论文已经被 AAAI2022 录用 [1]。接下来我们先简单介绍一下什么是预训练对话模型,然后重点介绍半监督预训练对话模型。
4预训练对话模型
预训练语言模型(Pre-trained Language Model, PLM)需要回答的什么样的句子更像自然语言,而预训练对话模型(Pre-trained Conversation Model, PCM)需要回答的是给定对话历史什么样的回复更合理。因此,预训练对话模型相比预训练语言模型任务更加特定化,需综合考虑对话轮次、对话角色、对话策略、任务目标等预训练语言模型不太关注的特征,图 4 给出了一个对话特有属性的总结。

图 4:对话特有的属性总结
目前预训练对话模型的建模,基本按照对话理解和对话生成两大任务类进行建模,利用类似于 BERT 或者 GPT-2 的 loss 在对话语料上进行预训练。例如,针对话理解,常见模型有 PolyAI 的 ConvRT [20],Salesforce 的 TOD-BERT [21] 和亚马逊的 ConvBERT [31],针对对话生成,常见模型有微软的 DialoGPT [18],谷歌的 Meena [19] 和 Facebook 的 Blender [30]。但是,这些模型都没有融入标注知识。
5 半监督预训练建模方案
我们的目标评测基准是剑桥 MultiWOZ2.0,亚马逊 MultiWOZ2.1 等经典对话数据集,该任务需要通过构建对话模型来进行用户意图识别、对话策略选择和回复生成。针对下游任务模型,我们直接沿用已有的端到端对话模型 UBAR [24],将其通用的 GPT-2 模型底座换成我们的 SPACE 模型底座,再进行相同设置下的评测。
5.1. 对话策略知识
对话策略是对话过程中的一个重要模块,一般用对话动作标签(dialog act, DA)来进行刻画,即给定双方的对话历史,对话策略需要选择出正确的对话动作用于指导对话生成(图 5)。当前各种常见预训练对话模型,如 Meena,DialoGPT 等往往都直接将对话动作的选择过程隐含建模到模型参数里,存在着不可解释和不可控等问题。由于策略是一种高层语义,难以仅仅利用自监督的方式就能很好地学习出来。因此,接下来我们将从对话策略建模出发,提出利用半监督的方式实现更好的预训练,将标注数据中的对话策略知识融入到预训练对话模型中来。
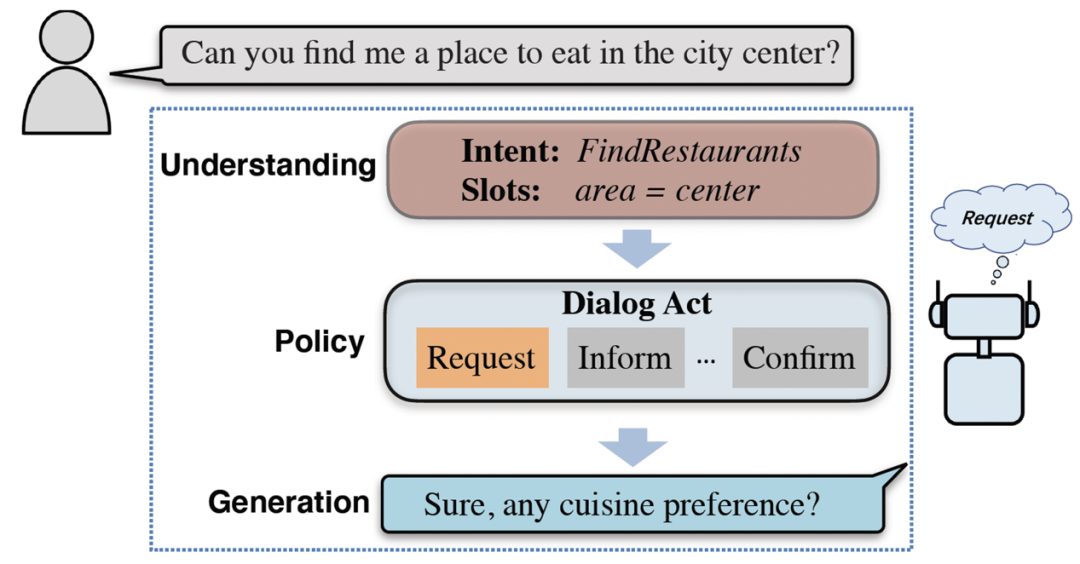
图 5:一轮完整对话过程
经过总结分析,我们从 ISO 国际对话动作标准 [25] 中归纳出了 20 个对于任务型对话最高频的对话动作集合(见图 6),并整理合并了现有的多个对话数据集,经过人工对齐删改后我们给出了目前最大的英文任务对话动作标注数据集 UniDA(一共 97 万轮次),同时我们也从各种公开论坛,开源 benchmark 等渠道收集处理得到了高质量的英文无标对话语料 UnDial (一共 3.5 千万轮次)。具体细节可参考论文 [1]。
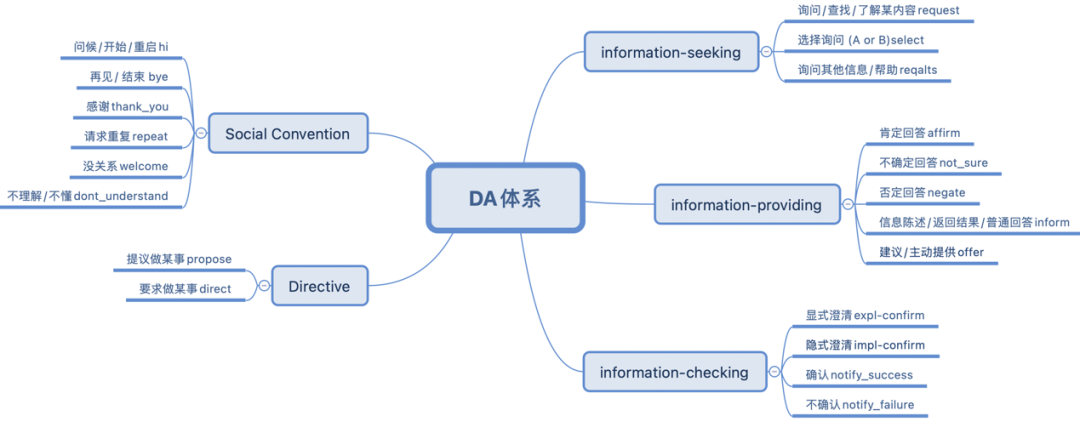
图 6:英文对话 UniDA 体系
5.2. 策略知识注入
在本文中,我们提出利用半监督预训练的方式来解决对话策略的建模难题,将对话动作预测任务改造成半监督学习任务,并设计出 SPACE 系列的第一款预训练模型 SPACE 1.0 (亦即我们 AAAI 论文 [1] 中 GALAXY 模型)。
具体来看,SPACE1.0 采用了 encoder+decoder 架构,预训练的目标既包含了传统的建模对话理解和对话生成的自监督 loss,也包含了建模对话策略的半监督 loss,完整框架见图 7。
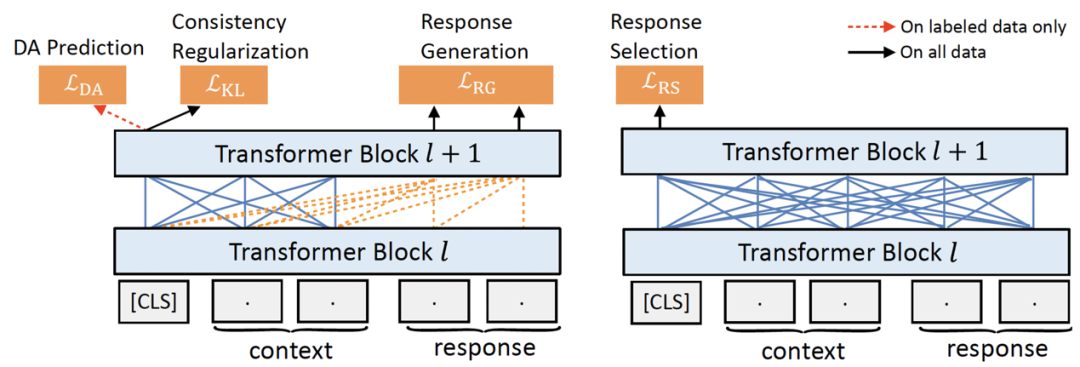
图 7:半监督对话预训练框架
首先,对于对话理解,我们采用了回复选择(response selection)作为预训练目标(如图 7 右侧所示),即给定对话上下文(context)和候选回复(response)在 [CLS] 处进行二分类判决是否是正确的回复。在诸多 PCM 工作中 [20][21] 中都已经证明了回复选择的训练对于对话理解至关重要,因此我们保留该目标。
对于对话生成,我们则使用了常见的回复生成(response generation)目标,即给定对话上下文生成正确回复语句(如图 7 左侧所示)。
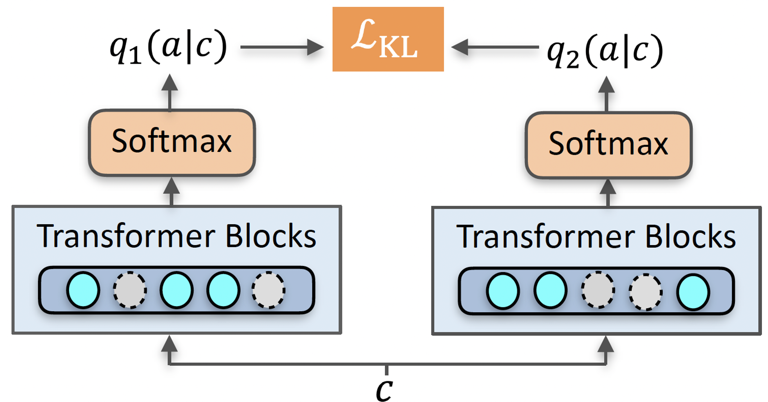
图 8:基于 R-drop 的一致性正则损失
对于对话策略,我们采用了半监督学习中十分高效的一致性正则 (consistency regularization) 方法来建模对话动作。理论可以证明,在满足低密度假设下(即分类边界处于低密度分布),通过对同一个样本进行扰动后分类结果仍然具备一定程度上的一致性(即分布接近或预测结果接近),那么最终基于一致性正则的半监督学习可以保证找到正确的分类面 [23]。针对对话策略的具体损失函数组成如下:
针对无标对话数据,我们采用了 R-drop [22] 的思路,如图 7 所示,给定同样的对话输入 c,经过两次带有 dropout 的 forward 得到了两次经过随机扰动后在对话动作空间上预测的不同分布,然后通过双向 KL 正则损失函数来约束两个分布;
针对有标对话数据,我们则直接利用基础的有监督交叉熵 loss 来优化对话动作预测。
最终对于模型的预训练,我们将整个模型的理解、策略、生成目标加在一起进行优化。更多具体细节可参考论文 [1]。
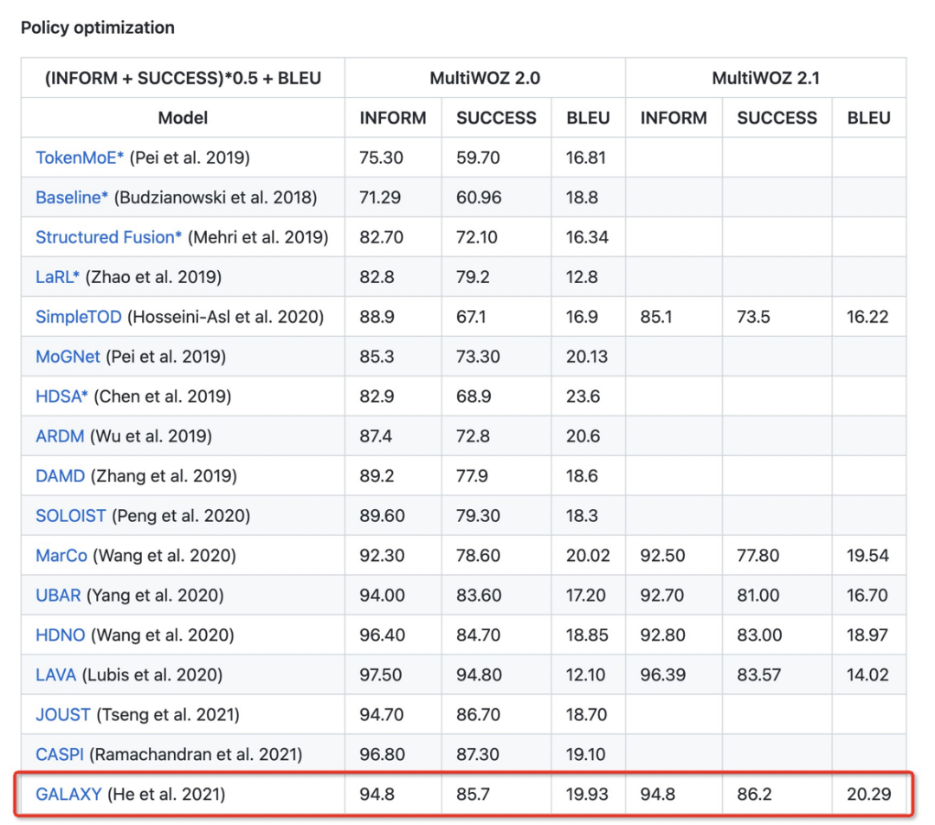
6. 半监督预训练效果显著
我们在斯坦福的 In-Car [28],剑桥的 MultiWOZ2.0 [26] 和亚马逊的 MultiWOZ2.1 [27] 这三个国际对话数据集上进行效果验证。In-Car 数据集提出时间最早,是车载语音对话数据,一共有约 3k 个完整对话,难度较为简单;MultiWOZ2.0 是目前最大最难使用最广泛的任务型对话数据集,包含 1w 个完整对话,横跨 7 个场景,如订餐馆、订酒店等。MultiWOZ2.1 是在 MultiWOZ2.0 基础上进行人工标注校正后数据集。
如图 9 所示,经过半监督预训练融入策略知识后,可以看到我们的 SPACE1.0 模型在这些对话榜单上均大幅超过了之前的 SOTA 模型,端到端混合分数在 In-Car,MultiWOZ2.0 和 MultiWOZ2.1 分别提升 2.5,5.3 和 5.5 个点:
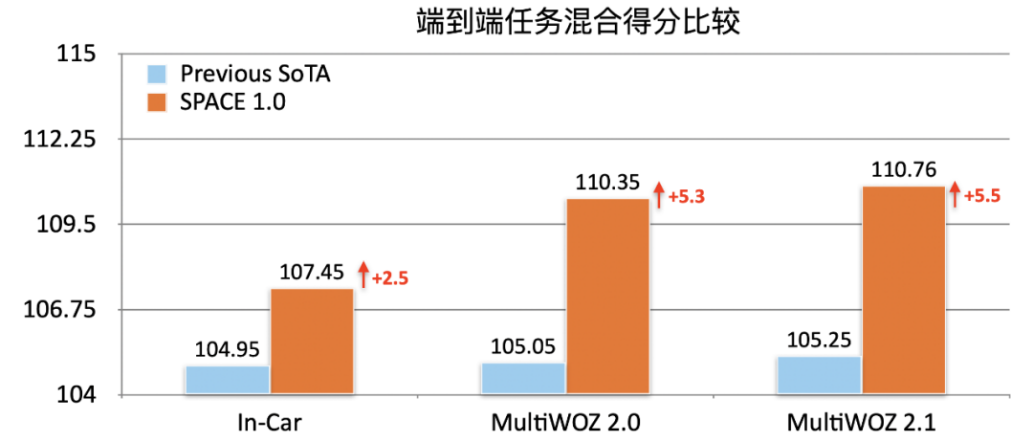
图 9:各数据集端到端得分总体结果比较
以上的结果充分证明了半监督预训练的效果。同时我们也做了低训练资源下实验,发现在利用不同训练数据比例下,我们的模型都保持着显著的效果提升。如图 10 所示,SPACE1.0 模型在仅利用 5% 训练数据量下就能够和利用全量 100% 训练数据的基于 GPT-2 的对话模型 SimpleTOD 可比,仅利用 10% 训练数据量就直接超过了利用全量训练数据量的基于 T5 的对话模型 MinTL。

图 10:低资源训练下端到端得分结果比较
我们也进行了案例分析,从图 11 中可以发现,相比之前的 SOTA 模型,SPACE1.0 模型能够预测出更加正确的对话动作,因此,合理的对话策略能够提升整体的端到端任务完成效果。
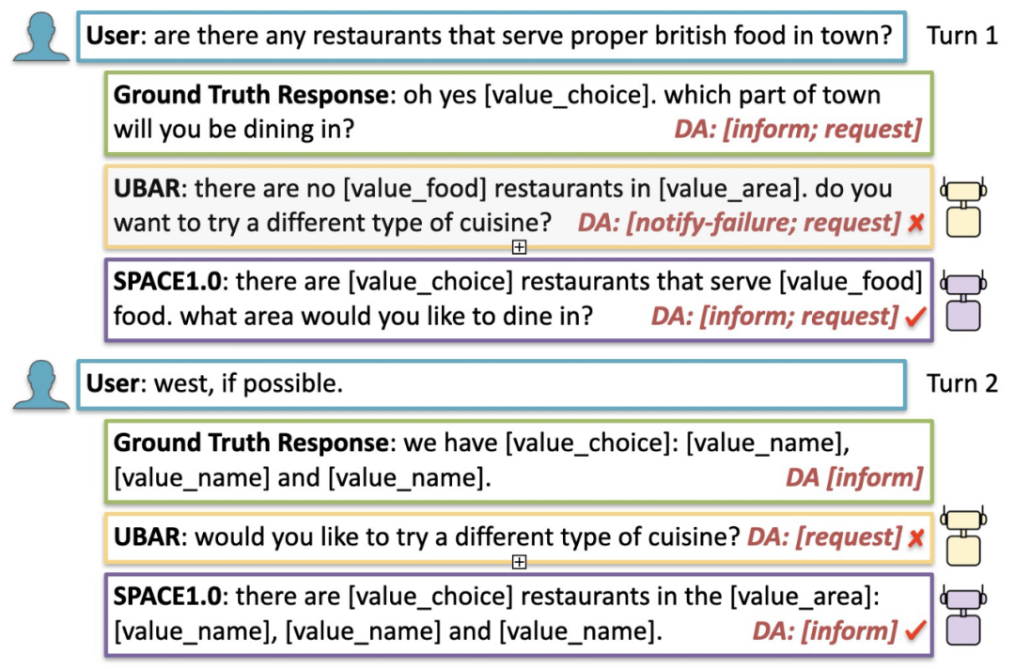
图 11:案例分析 Case Study
SPACE1.0 模型(即 GALAXY)目前在 MultiWOZ 官网上仍然排名第一,成绩截图如下所示:

7. 总结展望
本工作主要介绍了如何通过半监督预训练向大模型中注入特定的人类标注知识,从而使得模型在下游任务上有更加卓越的效果。和过往的半监督学习相比,我们关注的不再是如何降低对标注数据量的依赖,而是如何更加高效地融入特定标注知识,如下图 12 所示:
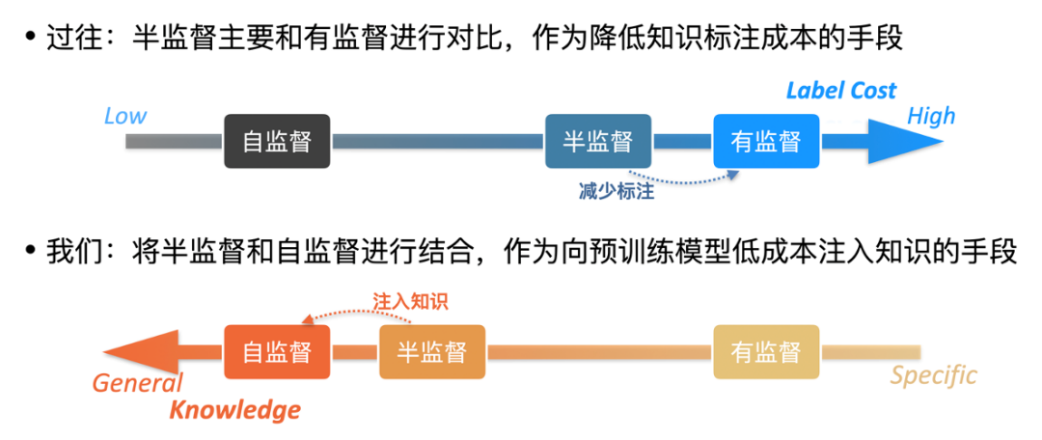
图 12:将半监督学习从下游训练推广到预训练过程
在后续的工作里,怎样将该范式进一步推广到各类 NLP 的任务中去,打造出一套有实用价值的半监督预训练 SPACE 模型体系,是需要持续探索的方向,具体包括:
知识自动选择:如何利用算法模型自动选择出合适的任务知识,从大量标注数据集中找出对目标下游任务最有用的数据集集合来进行半监督预训练是使得该范式成为通用范式的亟需研究问题。
半监督算法:目前我们尝试的是基于一致性正则化的半监督预训练方案,但整个半监督领域还有 self-taught, co-training, deep generative modeling 等诸多方法,如何综合利用他们是一个重要研究课题。
异构知识统一:本文中我们仅关注了分类标注知识,针对其他类型的标注知识,序列标注知识、层次化分类知识、回归标注等,如何进行更好的形式化表示,统一地融入到一个预训练模型中也是一个开放问题。
知识注入评价:如何更加定量且显式地度量出特定任务知识注入的程度,利用 probing 等方法对知识融入有个合理的评价也值得进一步的研究探索。
参考文献
[1].GALAXY: A Generative Pre-trained Model for Task-Oriented Dialog with Semi-Supervised Learning and Explicit Policy Injection. AAAI 2022.
[2].Hinton G E, Osindero S, Teh Y W. A fast learning algorithm for deep belief nets [J]. Neural computation, 2006, 18 (7): 1527-1554.
[3].Devin J, Chang M W, Lee K, et al. Bert: Pre-training of deep bidirectional transformers for language understanding. NAACL 2019.
[4].C Dosovitskiy A, Beyer L, Kolesnikov A, et al. An image is worth 16x16 words: Transformers for image recognition at scale. ICLR 2021.
[5].Xu H, Zhengyan Z, Ning D, et al. Pre-Trained Models: Past, Present and Future [J]. arXiv preprint arXiv:2106.07139, 2021.
[6].Clark K, Khandelwal U, Levy O, et al. What does bert look at? an analysis of bert's attention. BlackBoxNLP 2019.
[7].Tenney I, Das D, Pavlick E. BERT rediscovers the classical NLP pipeline. ACL 2019.
[8].Warstadt A, Cao Y, Grosu I, et al. Investigating BERT's Knowledge of Language: Five Analysis Methods with NPIs. ACL 20.
[9].Leyang Cui, Sijie Cheng, Yu Wu, Yue Zhang. On Commonsense Cues in BERT for Solving Commonsense Tasks. ACL-findings 2021.
[10].Zhengyan Zhang, Xu Han, Zhiyuan Liu, Xin Jiang, Maosong Sun, Qun Liu. ERNIE: Enhanced Language Representation with Informative Entities. ACL 2019.
[11].Weijie Liu, Peng Zhou, Zhe Zhao, Zhiruo Wang, Qi Ju, Haotang Deng, Ping Wang. K-BERT: Enabling Language Representation with Knowledge Graph. AAAI 2020.
[12].Xiaozhi Wang, Tianyu Gao, Zhaocheng Zhu, Zhengyan Zhang, Zhiyuan Liu, Juanzi Li, Jian Tang. KEPLER: A Unified Model for Knowledge Embedding and Pre-trained Language Representation. To appear at TACL.
[13].Xu Y, Li M, Cui L, et al. Layoutlm: Pre-training of text and layout for document image understanding [C]//Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. 2020: 1192-1200.
[14].Jiuxiang Gu, et al. Unified Pretraining Framework for Document Understanding. NeurIPS 2021.
[15].Liu P, Yuan W, Fu J, et al. Pre-train, prompt, and predict: A systematic survey of prompting methods in natural language processing [J]. arXiv preprint arXiv:2107.13586, 2021.
[16].Raffel C, Shazeer N, Roberts A, et al. Exploring the limits of transfer learning with a unified text-to-text transformer [J]. arXiv preprint arXiv:1910.10683, 2019.
[17].Xiaojin Jerry Zhu. Semi-supervised learning literature survey. 2005.
[18].Zhang Y, Sun S, Galley M, et al. Dialogpt: Large-scale generative pre-training for conversational response generation. ACL 2020 demostration.
[19].Adiwardana D, Luong M T, So D R, et al. Towards a human-like open-domain chatbot [J]. arXiv preprint arXiv:2001.09977, 2020.
[20].Henderson M, Casanueva I, Mrkšić N, et al. Convert: Efficient and accurate conversational representations from transformers. EMNLP-findings 2019.
[21].Wu C S, Hoi S, Socher R, et al. TOD-BERT: pre-trained natural language understanding for task-oriented dialogue. EMNLP 2020.
[22].Liang X, Wu L, Li J, et al. R-drop: regularized dropout for neural networks. NeurlPS 2021.
[23].Verma V, Kawaguchi K, Lamb A, et al. Interpolation consistency training for semi-supervised learning. IJCAI 2019.
[24].Yang Y, Li Y, Quan X. UBAR: Towards Fully End-to-End Task-Oriented Dialog Systems with GPT-2 [J]. arXiv preprint arXiv:2012.03539, 2020.
[25].Bunt H, Alexandersson J, Carletta J, et al. Towards an ISO standard for dialogue act annotation [C]//Seventh conference on International Language Resources and Evaluation (LREC'10). 2010.
[26].Budzianowski P, Wen T H, Tseng B H, et al. MultiWOZ--A Large-Scale Multi-Domain Wizard-of-Oz Dataset for Task-Oriented Dialogue Modelling. EMNLP 2018.
[27].Eric M, Goel R, Paul S, et al. Multiwoz 2.1: Multi-domain dialogue state corrections and state tracking baselines. LREC 2020.
[28].Eric M, Manning C D. Key-value retrieval networks for task-oriented dialogue. SIGDIAL 2017.
[29].Wang W, Bi B, Yan M, et al.Structbert: incorporating language structures into pre-training for deep language understanding. ICLR 2019.
[30].Roller S, Dinan E, Goyal N, et al. Recipes for building an open-domain chatbot [J]. arXiv preprint arXiv:2004.13637, 2020.
[31].Mehri S, Eric M, Hakkani-Tur D. Dialoglue: A natural language understanding benchmark for task-oriented dialogue [J]. arXiv preprint arXiv:2009.13570, 2020