Incorporating Explicit Knowledge in Pre-trained LanguageModels for Passage Re-ranking
1. 引言
任务:
段落重新排序是现代信息检索系统中的一个关键阶段,旨在重新排序一小部分候选段落以呈现给用户
现状:
大规模的预训练语言模型(PLM),例如BERT 、ERNIE 和 RoBERTa 主导了许多自然语言处理任务,并且在段落重新排序方面也取得了显着的成功。
优势:
transformer结构和预训练模型+微调范式,这允许模型从大量文本语料库中学习有用的隐式知识
问题:
查询和段落通常由不同的人创建,并且具有不同的表达方式
搜索查询和网络内容的数据分布是高度异构的 ,其中各种专业领域(例如,生物医学)在一般语料库中可能只有很少的训练示例。
特定领域的知识很难被模型揭示和捕获,因此特定领域查询的处理往往是不准确的。
KERM:
为了克服这些限制,必须将知识图谱作为显式知识合并到基于 PLM 的重新排序器中。因此,我们提出了知识增强重新排序模型 (KERM),它利用外部知识显式增强基于 PLM 的重新排序器中的语义匹配过程。

Challenges:
Challenge1. 现有的知识图谱不是为重新排序任务而构建的。它们通常包含琐碎的事实三元组,很难带来信息增益。不适当的外部知识选择甚至可能危害重新级别的性能。如何利用现有的知识图谱对任务进行重新排序仍然是一个挑战。
Challenge2. 显性知识和隐性知识由于来源不同而具有高度异质性,这使得两者难以聚合。如何相互提炼,有效地将显性知识聚合为隐性知识,以缓解查询和段落之间的语义鸿沟,仍然是一个挑战。
Contributions:
这是第一次尝试解决知识增强PLMs问题的段落重新排序。关键动机在于在两种知识的帮助下弥合查询和段落之间的语义鸿沟
我们设计了一种新颖的知识图谱蒸馏方法。它在全局范围内从现有的知识图谱中提炼出一个可靠的知识图谱,并在本地基于精炼图谱构建一个知识元图谱。
我们提出了一种新的PLM 聚合和图神经网络框架来模拟显性知识和隐性知识之间的交互。
实验结果表明 KERM 在一般数据和特定领域数据上的有效性,在段落重新排序方面实现了最先进的性能。我们还对我们方法中每个模块的影响进行了全面研究。
2. 问题定义

3. 算法
3.1 Knowledge Graph Distillation
Step1:Global Graph Pruning
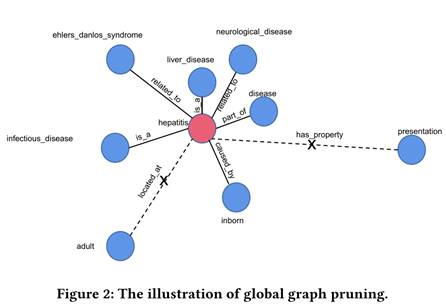
整体来说就是使用TransE衡量给定三元组的可靠性,使用 TransE 预训练的实体嵌入来计算两个链接实体之间的距离度量:
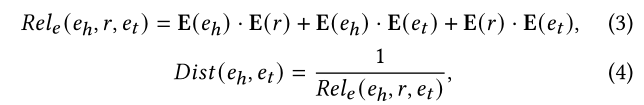
保留离得最近的k个节点,使用如下公式:
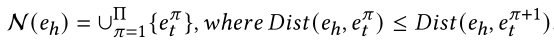
整体概括为:
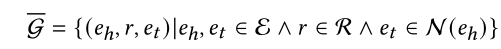
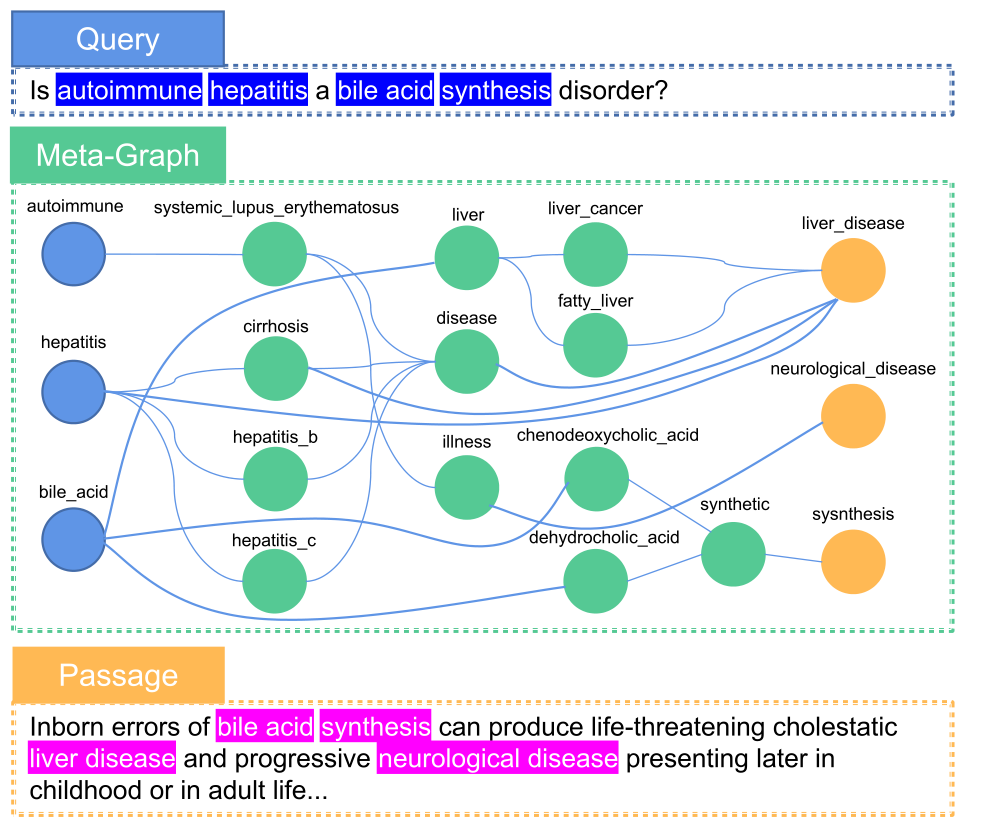
Step2: Meta-Graph Construction
进一步利用全局图 G 中的知识来构建查询和段落之间的“桥梁”,先使用如下公式进行关键句选择:
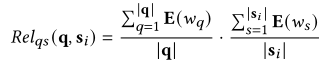
然后进行目标实体识别,再使用BFS进行路径发现。
3.2 Knowledge Aggregation
1.Text Encoder
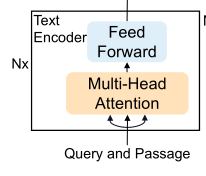
输入层:
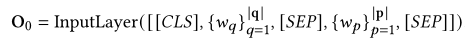
中间层:
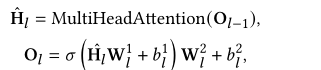
2. Knowledge Injector.

使用如下公式进行知识嵌入聚合:
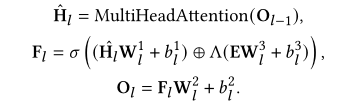
其中,⊕表示元素相加,Λ(·)表示对齐函数将实体映射到标记的相应位置。
GMN 的输入用融合特征 F_l 表示:
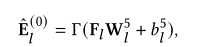
中间层:
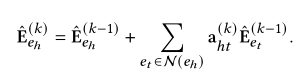
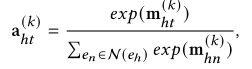
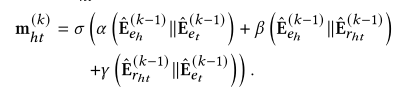
q 和 p 之间的 Gq,p 的所有路径都在 hops 内,GMN 模块可以沿着从 p 中的实体到 q 中的实体的路径专注地传播知识,反之亦然,这可以丰富有利于相关性建模的实体的语义。
3.2 优化
对 MSMARCO 语料库进行持续的预训练,以预热 GMN 模块的参数。将掩蔽语言模型 (MLM) 和句子关系预测 (SRP) 作为 KERM 中的预训练任务。与传统的下一句预测 (NSP) 相比,SRP 的任务是预测给定句子是下一句、前一句关系还是与另一个句子没有关系。为了在预训练阶段整合知识,为每个句子对构建一个元图,并应用上面介绍的知识聚合过程。预训练损失定义为 :
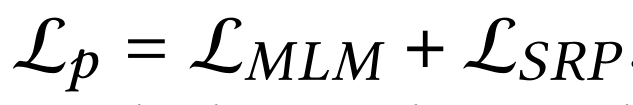
采用交叉熵损失来微调 KERM:

4 Result
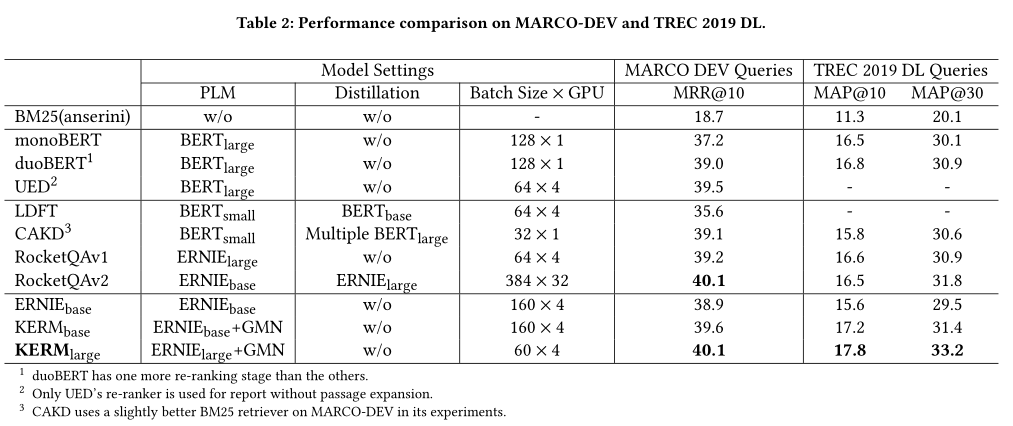

5总结
本文的主要目的是将外部知识图合理地引入到PLM中,用于文章的重新排序。我们首先设计了一种新的知识元图构造方法,从一般的、有噪声的知识图中提取可靠的相关知识并进行查询。知识元图弥合了每个查询和段落之间的语义鸿沟。然后,我们提出了一种用于文本和知识表示相互更新的知识注入器层,该层将文字表示转换为图元网络中的实体表示,反之亦然。知识增强排序模型通过掩蔽语言模型(MLM)句子关系预测(SRP)[38]任务进行预训练,并使用交叉熵损失函数对段落重新排序任务进行微调。在公共基准数据集上的实验结果表明,由于该方法是第一次尝试,因此与没有外部知识的最新基线相比,该方法是有效的。并对各个模块在KERM中的作用进行了全面分析。由于这项工作仅限于在线建立的查询-通道对的一对一元图,因此需要继续努力使知识增强在检索和重新排序阶段都更有效。