1. 引言
机器阅读理解(MRC)任务通过问答的形式来衡量模型是否理解了自然语言文本,自BERT出现以来,许多基于预训练的MRC模型在一些benchmark数据集上接近甚至超越了human performance,以至于不少论文通常会在结论中表述模型“理解(comprehend)”了文本的“含义(meaning)”。
然而深度学习模型终究只是统计模型,当前的MRC模型本质上仅仅是通过复杂的函数来拟合文本中的统计线索,从而预测答案而已,作者指出仅仅在文本世界中构建模型而不与真实世界建立联系的话,模型永远只能学到”form",学不到"meaning"。
因此近两年也出现了不少分析、批判与反思当前MRC模型存在的问题的论文,其中What Makes Reading Comprehension Questions Easier?指出当前的MRC模型其实并没有以我们预想的方式来推理答案,MRC模型会学到很多捷径(shortcuts),或者说是一些显而易见的规律。
比如通过位置信息来寻找答案,因为SQuAD的答案大多集中于整篇文章的第一句话,所以MRC模型会倾向于预测答案大概率在第一句话中,当我们把第一句话移到文末时,模型的表现就会急剧下降。曾经有一些论文会将答案的位置信息当作MRC模型的输入特征,虽然人类在进行阅读理解时,推导答案的位置并不构成“理解”。
图1是一个简单的例子,我们希望MRC模型可以理解come out和begun之间的语义一致性,并通过建立Scholastic journal,Scholastic magazine以及one-page journal之间的共指关系(co-reference)来推导出正确答案是September 1876。
但实际上,模型可以直接识别出September 1876是整个片段中唯一可以回答When类问题的时间实体,也就是仅通过简单的疑问词匹配就可以正确回答问题,而不需要共指消解之类的复杂推导。

图1数据示例
利用这种简单的线索推导出的答案当然是不可靠的,如果文本中出现了两个时间实体,MRC模型很可能就不知道哪个时间实体是答案了。
由于捷径的存在,模型可以不用真正理解问题和片段的含义就推断出答案,比如把问题或片段的重要部分去掉以至于问题变得不可回答之后,MRC模型仍旧能够给出正确答案,这表明当前的MRC模型是非常脆弱的,并没有真正衡量所谓的“阅读理解”能力。
MRC模型走捷径的行为其实和人类有几分相似,我们在考试的时候遇到一个不会的题,总会去寻找一些无关线索来推导答案,比如三短一长选最长,参差不齐就选C,以及数学考试中常见的排除法、特值法、估算法等。但我们在学习知识的过程中并不会采用这些技巧,因为这些技巧并不是真正的知识。
虽然已经有许多论文证实了捷径现象的存在,同时也提出了一些办法来缓解这个问题,但还没有论文尝试探讨MRC模型是如何学到这些捷径技巧的,本文希望可以找到一个定量的方式来分析模型学习捷径问题和非捷径问题的内在机制。
2. 数据集构建
为了更好地研究这个问题,我们遇到的第一个障碍就是目前还没有一个数据集包含训练样本是否存在捷径的标签,因此很难分析模型到底在多大程度上受到了捷径样本的影响,也很难分析MRC模型在回答问题时是否真的走了捷径。
本文以SQuAD数据集为基础,通过分别设计两个合成的MRC数据集来解决上述问题,在这两个数据集中,每个样本包含一个原样本(passage,question)的捷径版本(shortcut version) 和挑战版本(challenging version),在构建数据集的时候,我们需要保证两个版本在长短、风格、主题、词表、答案类型等方面保持一致,从而保证捷径的存在与否是唯一的独立变量,最后,作者在这两个数据集上进行个实验来分析了捷径问题对MRC模型性能和学习过程的影响。
在数据集的捷径版本中,本文考虑两种捷径:疑问词匹配(question word matching, QWM)和简单匹配(simple matching, SpM),QWM是指模型可以通过识别疑问词类型来匹配答案,SpM是指模型可以通过答案所在的句子和问题的词汇重叠来匹配答案。
本文在SQuAD数据集的基础上构造上述两个数据集,通过back-translation来获取释义句,最后得到的QWM-Para数据集和SpM-Para数据集的训练/测试集的大小分别为6306/766和7562/952,下面简单讲解数据集的构建流程,更详细的构建细节可参考原文。
图2是QWM-Para数据集的构建流程,以下图为例,在捷径版本中,模型可以直接通过疑问词Who与唯一的人物实体Beyonce的匹配来推断出答案是Beyonce。而在挑战版本中,另一个人物实体Lisa构成了干扰项,这可以避免模型通过简单的疑问词匹配的捷径来推断答案,从而期望模型可以识别出named the most influential music girl和rated as the most powerful female musician之间的释义关系。
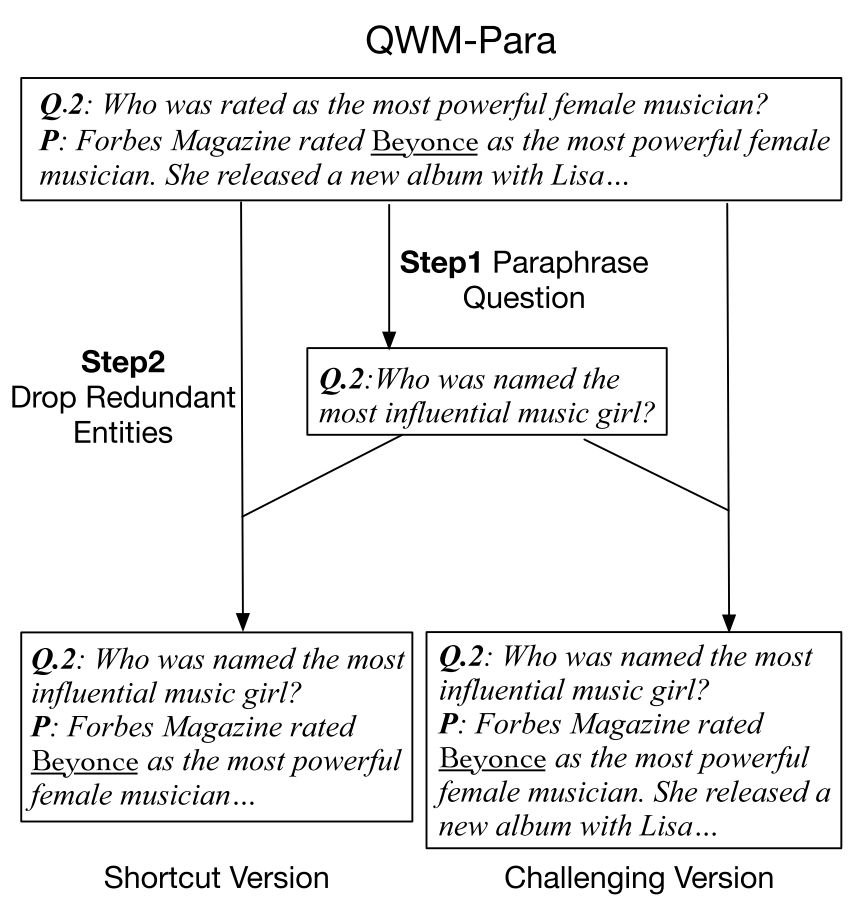
图2 QWM-Para数据集的构建流程
图3是SpM-Para数据集的构建流程,在下例的捷径版本中,模型可以通过简单的词汇匹配rated as the most powerful female musician来获取答案Beyonce。在挑战版本中,我们只提供了原文的释义版本,从而避免了模型通过简单的词汇匹配获取答案,这对模型的释义能力提出了要求。
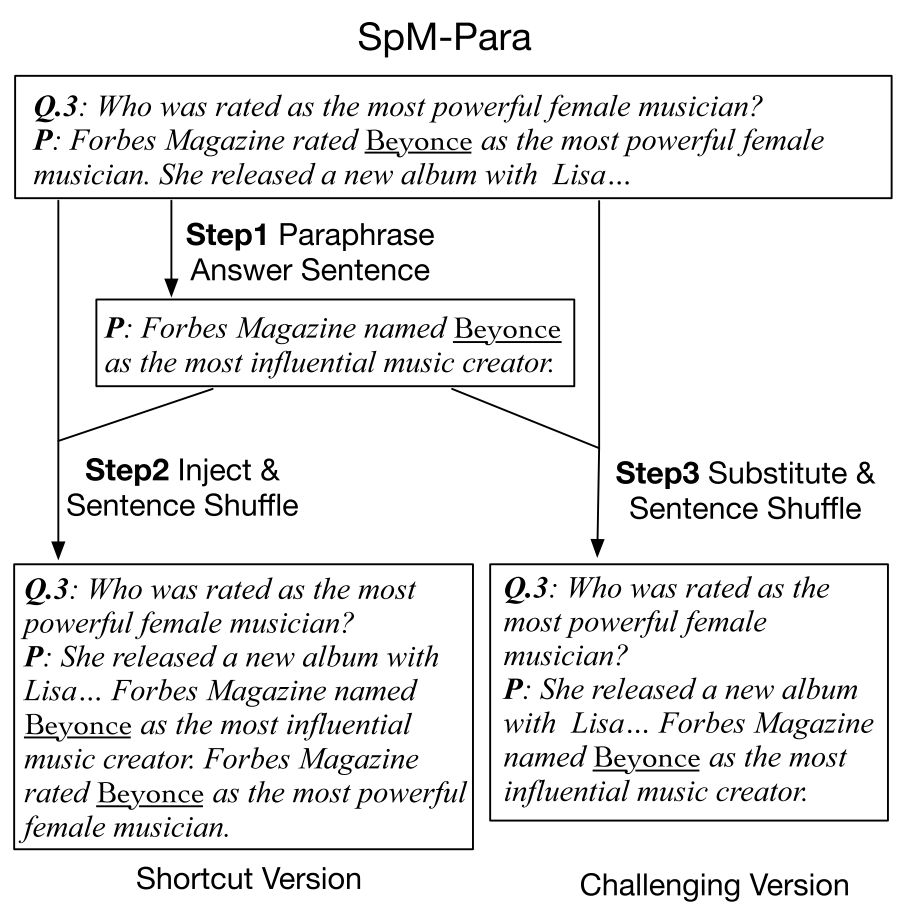
图3 SpM-Para数据集的构建流程
3. 捷径问题如何影响模型表现?
模型是如何学习到捷径技巧的?猜测:因为数据集中的大部分问题都是捷径样本,因此模型会优先学习捷径技巧。验证:通过观察使用不同比例的捷径样本训练出的模型分别在捷径测试集和挑战测试集上的表现,来确定模型在多大程度上受到了捷径样本的影响。
作者训练了两个经典的MRC模型:BiDAF和BERT,如下表1所示,当我们将数据集中的捷径问题的比例从0%增加到90%时,增加捷径样本仅能带来很小的提升,但却会让模型在挑战样本上的表现大幅下降,这表明捷径问题的存在阻碍了模型对文章内容的学习。

表1 实验结果
我们可以注意到,当训练集的捷径样本和挑战样本的比例为1:1时,MRC模型还是会在捷径问题上取得更好的表现,这表明模型倾向于优先拟合捷径样本,这表明学习词汇匹配比学习释义要简单得多。为了验证这个想法,作者分别在捷径数据集和挑战数据集上训练MRC模型,然后比较在训练集上达到同等水平所需要的迭代次数和参数量。我们可以发现MRC模型在捷径数据集上训练的迭代次数要更少,同时所需要的参数量也更少,这表明释义能力的确是更难学到的。
4. 模型如何学习捷径?
前面本文通过实验证明捷径样本确实更容易被拟合,模型更倾向于优先学习捷径技巧。猜想:在训练的早期阶段,捷径样本所给出的梯度是更明确的(方差更小),因此模型更倾向于向拟合捷径样本的方向做梯度下降,然而在训练后期,模型将受困于捷径技巧的局部最优解,无法进一步学习更难的释义能力。验证:同一个MRC模型在捷径数据集和挑战数据集上的表现差距越大,我们就可以认为该模型学到了更多的捷径技巧,基于此,作者尝试分别在包含10%捷径样本和90%捷径样本的训练集上训练MRC模型。
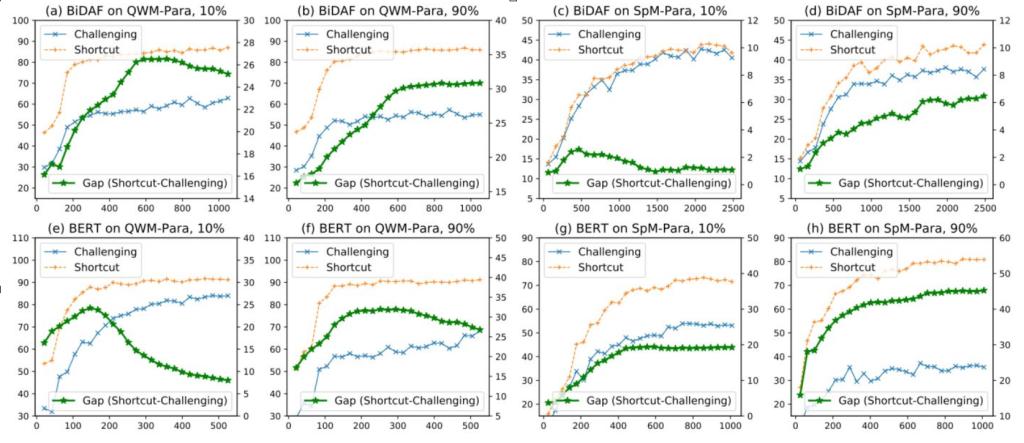
表2 实验结果
到了训练的中后期阶段,当训练集只包含10%的捷径样本时,这一差异转而会逐渐下降,这表明模型开始更多地学习更难的释义技巧,此时挑战样本对梯度的贡献变得更为明显。但如果训练集包含了90%的捷径样本,这一差异会趋于平稳,这说明模型的学习路线依旧被捷径样本所主导,模型无法通过仅有的10%的挑战样本学习释义技巧。
即少数未解决的挑战性样本无法激发模型去学习更复杂的释义技巧。
5. 结论
本文回答了为什么许多MRC模型学习shortcuts技巧,而忽视comprehension challenges。首先设计了两个数据集,其中每个实例都有一个简单的版本,另一个具有挑战性的版本需要较为复杂的推理技能来回答,而不是按问题进行单词匹配或简单匹配。
本文发现learning shortcut questions通常需要较少的计算资源,而MRC模型通常在训练的早期阶段学习shortcut questions。随着训练中shortcut问题的比例越来越大,MRC模型将在忽略challenge questions的同时快速学习shortcut questions。
参考文献
[1] Max Bartolo, A. Roberts, Johannes Welbl, Sebastian Riedel, and Pontus Stenetorp. 2020. Beat the ai: Investigating adversarial human annotation for reading comprehension. Transactions of the Association for Computational Linguistics, 8:662–678.
[2] Danqi Chen, Jason Bolton, and Christopher D Manning. 2016. A thorough examination of the cnn/daily mail reading comprehension task. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers),pages 2358–2367.
[3] Christopher Clark, Kenton Lee, Ming-Wei Chang,Tom Kwiatkowski, Michael Collins, and KristinaToutanova. 2019. BoolQ: Exploring the surprising difficulty of natural yes/no questions. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1(Long and Short Papers), pages 2924–2936, Minneapolis, Minnesota. Association for Computational Linguistics.
[4] Pradeep Dasigi, Nelson F. Liu, Ana Marasovic,´Noah A. Smith, and Matt Gardner. 2019. Quoref: A reading comprehension dataset with questions requiring coreferential reasoning. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pages 5925–5932, Hong Kong,China. Association for Computational Linguistics.
[5] Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. Bert: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pages 4171–4186.
[6] Li Dong, Jonathan Mallinson, Siva Reddy, and Mirella Lapata. 2017. Learning to paraphrase for question answering. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pages 875–886.
[7] Dheeru Dua, Yizhong Wang, Pradeep Dasigi, Gabriel Stanovsky, Sameer Singh, and Matt Gardner. 2019. Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pages 2368–2378.
[8] Michael Glass, Alfio Gliozzo, Rishav Chakravarti, Anthony Ferritto, Lin Pan, G P Shrivatsa Bhargav, Dinesh Garg, and Avi Sil. 2020. Span selection pretraining for question answering. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 2773–2782, Online. Association for Computational Linguistics.
[9] Xanh Ho, Anh-Khoa Duong Nguyen, Saku Sugawara, and Akiko Aizawa. 2020. Constructing a multihop QA dataset for comprehensive evaluation of reasoning steps. In Proceedings of the 28th International Conference on Computational Linguistics, pages 6609–6625, Barcelona, Spain (Online). International Committee on Computational Linguistics.
[10] Harsh Jhamtani and Peter Clark. 2020. Learning to explain: Datasets and models for identifying valid reasoning chains in multihop question-answering. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP),pages 137–150, Online. Association for Computational Linguistics.
[11] Robin Jia and Percy Liang. 2017. Adversarial examples for evaluating reading comprehension systems. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pages 2021–2031.
[12] Yichen Jiang and Mohit Bansal. 2019. Avoiding reasoning shortcuts: Adversarial evaluation, training, and model development for multi-hop QA. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 2726–2736, Florence, Italy. Association for Computational Linguistics.
[13] Dimitris Kalimeris, Gal Kaplun, Preetum Nakkiran, Benjamin L Edelman, Tristan Yang, Boaz Barak, and Haofeng Zhang. 2019. SGD on neural networks learns functions of increasing complexity. In Advances in Neural Information Processing Systems32: Annual Conference on Neural Information Processing Systems 2019.
[14] Divyansh Kaushik and Zachary C Lipton. 2018. How much reading does reading comprehension require? a critical investigation of popular benchmarks. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pages 5010–5015.
[15] Tom Kwiatkowski, Jennimaria Palomaki, Olivia Redfield, Michael Collins, Ankur Parikh, Chris Alberti, Danielle Epstein, Illia Polosukhin, Jacob Devlin, Kenton Lee, Kristina Toutanova, Llion Jones, Matthew Kelcey, Ming-Wei Chang, Andrew M. Dai, Jakob Uszkoreit, Quoc Le, and Slav Petrov. 2019.Natural questions: A benchmark for question answering research. Transactions of the Association for Computational Linguistics, 7:453–466.
[16] Yuxuan Lai, Yansong Feng, Xiaohan Yu, Zheng Wang, Kun Xu, and Dongyan Zhao. 2019. Lattice cnns for matching based chinese question answering. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 33, pages 6634–6641.
[17] Christopher D. Manning, Mihai Surdeanu, John Bauer,Jenny Finkel, Steven J. Bethard, and David McClosky. 2014. The Stanford CoreNLP natural language processing toolkit. In Association for Computational Linguistics (ACL) System Demonstrations, pages 55–60.
[18] Sewon Min, Eric Wallace, Sameer Singh, Matt Gardner, Hannaneh Hajishirzi, and Luke Zettlemoyer. 2019. Compositional questions do not necessitate multi-hop reasoning. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 4249–4257, Florence, Italy. Association for Computational Linguistics.
[19] Seo Minjoon, Kembhavi Aniruddha, Farhadi Ali, and Hajishirzi Hannaneh. 2017. Bidirectional attention flow for machine comprehension. In International Conference on Learning Representations
[20] Pramod Kaushik Mudrakarta, Ankur Taly, Mukund Sundararajan, and Kedar Dhamdhere. 2018. Did the model understand the question? In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 1896–1906.
[21] Liang Pang, Yanyan Lan, Jiafeng Guo, Jun Xu, Lixin Su, and Xueqi Cheng. 2019. Has-qa: Hierarchical answer spans model for open-domain question answering. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 33, pages 6875–6882.
[22] Jeffrey Pennington, Richard Socher, and Christopher D. Manning. 2014. Glove: Global vectors for word representation. In Empirical Methods in Natural Language Processing (EMNLP), pages 1532–1543.
[23] Pranav Rajpurkar, Jian Zhang, Konstantin Lopyrev, and Percy Liang. 2016. Squad: 100,000+ questions for machine comprehension of text. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, pages 2383–2392.
[24] Siva Reddy, Danqi Chen, and Christopher D Manning. 2019. Coqa: A conversational question answering challenge. Transactions of the Association for Computational Linguistics, 7:249–266.
[25] Chenglei Si, Shuohang Wang, Min-Yen Kan, and Jing Jiang. 2019. What does bert learn from multiplechoice reading comprehension datasets? ArXiv, abs/1910.12391.
[26] Saku Sugawara, Kentaro Inui, Satoshi Sekine, and Akiko Aizawa. 2018. What makes reading comprehension questions easier? In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pages 4208–4219.
[27] Saku Sugawara, Pontus Stenetorp, Kentaro Inui, and Akiko Aizawa. 2020. Assessing the benchmarking capacity of machine reading comprehension datasets. In Thirty-Fourth AAAI Conference on Artificial Intelligence.
[28] Adam Trischler, Tong Wang, Xingdi Yuan, Justin Harris, Alessandro Sordoni, Philip Bachman, and Kaheer Suleman. 2017. Newsqa: A machine comprehension dataset. In Proceedings of the 2nd Workshop on Representation Learning for NLP, pages191–200.
[29] Eric Wallace, Shi Feng, Nikhil Kandpal, Matt Gardner, and Sameer Singh. 2019. Universal adversarial triggers for attacking and analyzing NLP. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pages 2153–2162, Hong Kong, China. Association for Computational Linguistics.
[30] Dirk Weissenborn, Georg Wiese, and Laura Seiffe. 2017. Making neural QA as simple as possiblebut not simpler. In Proceedings of the 21st Conference on Computational Natural Language Learning (CoNLL 2017), pages 271–280, Vancouver, Canada. Association for Computational Linguistics.
[31] Jindou Wu, Yunlun Yang, Chao Deng, Hongyi Tang, Bingning Wang, Haoze Sun, Ting Yao, and
[32] Qi Zhang. 2019. Sogou machine reading comprehension toolkit. arXiv preprint arXiv:1903.11848.
[33] Kun Xu, Yansong Feng, Songfang Huang, and Dongyan Zhao. 2016. Hybrid question answering
over knowledge base and free text. In Proceedings of COLING 2016, the 26th International Conference on Computational Linguistics: Technical Papers, pages 2397–2407, Osaka, Japan. The COLING 2016 Organizing Committee.
[34] Zhilin Yang, Peng Qi, Saizheng Zhang, Yoshua Bengio, William Cohen, Ruslan Salakhutdinov, and Christopher D Manning. 2018. Hotpotqa: A dataset for diverse, explainable multi-hop question answering. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pages 2369–2380