识别事实是做出判断的最基本步骤,因此检测法律文件中的事件对法律案件分析任务非常重要。然而,现有的法律事件检测(LED)数据集只涉及不全面的事件类型,而且注释的数据有限,这限制了LED方法的发展及其下游应用。为了缓解这些问题,我们提出了LEVEN,一个大规模的中国法律事件检测数据集,包括8116份法律文件和108个事件类型中的150977个人类注释的事件提及。不仅是与指控有关的事件,LEVEN还涵盖了一般事件,这些事件对法律案件的理解至关重要,但在现有的LED数据集中却被忽略了。据我们所知,LEVEN是最大的LED数据集,其数据规模是其他数据集的几十倍,这将大大促进LED方法的训练和评估。广泛的实验结果表明,LED具有挑战性,需要进一步努力。此外,我们只是利用法律事件作为侧面信息来促进下游的应用。该方法在低资源判决预测中实现了平均2.2分的精度改进,在无监督案件检索中实现了平均1.5分的精度改进,这表明LED的基础性。
1. 引言
法律事件检测找出发生的事件及其之间的因果关系,是分析法律案件和作出判断的基础。法律事件检测(LED)旨在从法律案件中自动提取事件触发词,然后对其对应的事件类型进行分类,这个任务有利于许多下游法律人工智能应用,例如法律判决预测(LJP)和类似案件检索( SCR)。
现有LED数据集的不足:(1)数据有限:现有的 LED 数据集仅包含数千个事件提及注释,无法提供足够的训练数据和可靠的评估结果。(2)不全面的事件模式:现有的LED数据集仅涉及十几种罪名事件类型,只覆盖了很小的范围。
LEVEN的优点:(1)规模大:包含 8116 份法律文件,涵盖 118 项刑事指控,并有 150977 次人工注释事件提及;(2)高覆盖率:包含108种事件类型,指控类事件64种,一般类事件44种
2. 数据收集
2.1 事件模式构建
第一阶段:使用法律文章和《刑法的具体理论》作为参考,总结出面向指控的事件,得到198个与刑事指控高度相关的事件类型。
第二阶段:为每项刑事指控抽出20份案件文件,邀请一位法律专家对抽样案件中出现的事件进行人工提取和总结。根据提取的事件,进一步过滤掉抽象的事件类型,最终得到了108个事件类型的注释,其中包括面向指控的事件和一般事件。
根据犯罪理论,犯罪的关键因素包括行为、危害结果和它们之间的因果关系。因此,本数据集将事件类型组织成一个分层结构,有三个类别代表行为,一个类别代表结果。
2.2 文件选择
采用从裁判文书网的案件作为数据源,保留刑事判决书作注释,用正则表达式提取文件中的相关指控,只保留事实描述部分,最终对8166份文件进行标注。
2.3 候选词选择
采用启发式方法自动选择候选触发词,并且缩小每个触发词候选项的事件类型选项。
2.4 触发词候选器的选择
法律专家为模式中的每个事件类型收集语义相关的词汇,得到了一个由1,013个词组成的语义词汇。用JIEBA工具包进行分词和位置标记,所有的内容词,包括名词和动词,都被选为触发器候选词。
2.5 候选的事件类型
为每个候选触发词选择30个事件类型,用SBERT分别计算表征,然后表征之间的余弦相似度,然后根据相似度进行排序,对前30名的事件类型进行相关度排序。还要求注释者对不在推荐列表中的词和事件类型进行标注。最终的注释结果显示,95.6%的触发器词和92.8%的事件类型被推荐,其余的由注释者手工补充。
2.6 对文件中的触发词进行手工注释
根据注释指南,邀请多名注释者进行多阶段的注释,得到高质量的标注结果。
2.7 数据分析
事件模式包含三个代表行为的事件类别,两个代表结果的事件类别,以及一个代表不可抗力的事件类别。
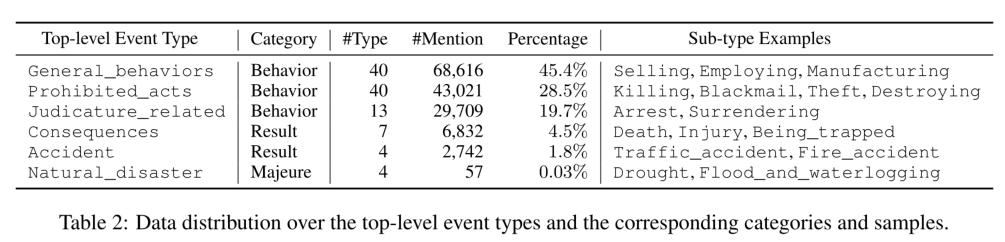
89.6%的事件类型包含100个以上的事件提及,43.4%的事件类型包含1000个以上的事件提及。
3. 实验分析
3.1 基准设置
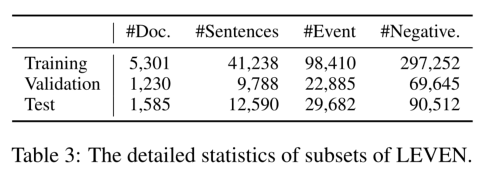
按照0.65 : 0.15 : 0.2的比例,将数据集随机分成训练集、验证集和测试集,采用微平均和宏平均的精度、召回率和F1得分作为实验的评价指标。
3.2 Baseline
分类:用BiLSTM和BERT对给定的句子进行编码,用候选触发器的隐藏表示对其相应的事件类型进行分类。
动态池化:采用卷积神经网络(DMCNN)或者BERT来提取序列特征,并采用动态池化层来获得每个候选者的特定触发词表示。
序列标注:采用序列标注模型(BiLSTM+CRF,BERT+CRF)来捕捉不同事件之间的相关性。
3.3 Baseline结果
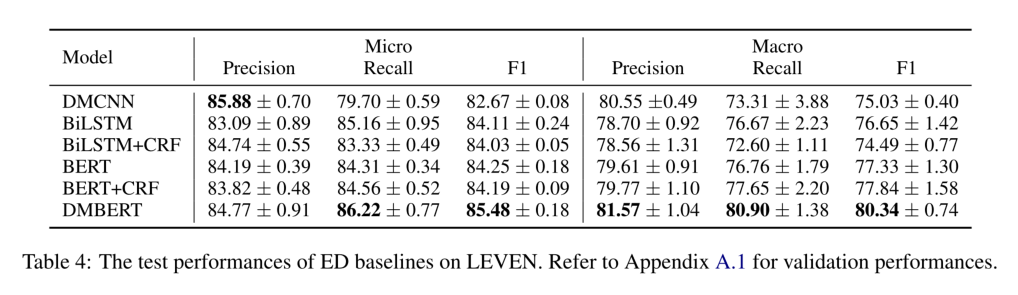
DMBERT可以明显地超过其他基线,并且微平均上的标准差相对较小,因为LEVEN在测试集中包含足够的数据,能够提供稳定的评价结果。从基于BiLSTM和基于BERT的模型的比较中,可以看出基于BERT的模型不能在LEVEN上取得明显的改进。这表明设计针对法律事件的预训练模型对LED来说是必要的。基于CRF的模型表现比其相应的分类模型略差,本实验采用CRF来捕捉多个事件之间的依赖性,而结果却与预期不一致。表明在建立单句中多个事件之间的相关性上仍然有待提高。值得注意的是,由于法律文件结构标准,使用的语言比一般领域更规范,事件检测模型在LEVEN上可以取得比一般领域数据集更好的性能。DMBERT在MAVEN上只能取得67.1%的micro-F1得分,而在LEVEN上则为85.5%。因此,可以应用现有的LED模型来促进下游任务的发展。
3.4 误差分析
长尾问题:虽然LEVEN包含数十万个事件提及,但有一些事件类型的实例不可避免地有限。少于50个实例的事件类型的micro-F1得分是65.97%,少于100个实例的事件类型是72.24%,低频类型的性能与总体平均性能之间仍有很大差距。
语境感知的预测:许多触发器需要模型整合来自句中实体或其他句子的复杂语境信息来预测相应的事件类型。 Bob rushed to call ENT to inform the situation。如果ENT是警察或110,触发电话的事件类型是Reporting_to_police,而如果ENT是其他人,事件类型是Reporting。有时,重要的信息来自于其他句子,这就需要模型来捕捉跨句子的依赖性。我们随机抽取100个案例,请另一位注释者统计需要上下文感知预测的错误数量。从统计结果来看,36.98%的错误是由不正确地捕捉上下文信息造成的。
3.5 法律事件检测的应用
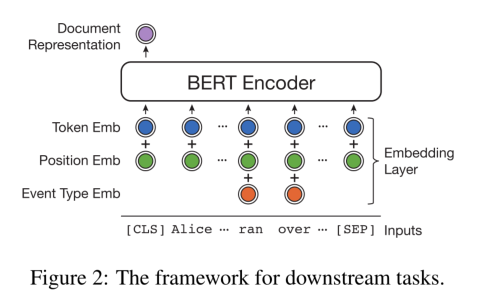
选用BERT作为基本结构,对词嵌入做出微小的改动,以整合事件信息。
采用BERT+CRF模型来检测案例文档中的触发词及其事件类型。通过在输入嵌入层中添加事件类型嵌入来利用BERT模型中的事件信息。事件类型嵌入在训练过程中被随机初始化和更新。
LED可以促进LJP的性能,尤其是在低资源环境下,这证明了LED的有效性。在完整的训练数据集下,LED只能在指控预测和法律条文预测上取得微弱提高,而在期限预测上取得显著提高。
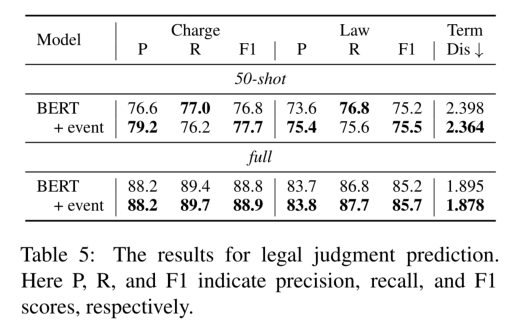
事件信息有助于提高BERT模型的性能,进一步证明了事件信息对案例检索的重要性。

4. 总结
本文构建了最大的法律事件检测数据集LEVEN,它包含了一个全面的法律事件模式和数十万个事件提及。本文对几种baseline模型进行了评估,并在LEVEN上对这些模型进行了误差分析。实验结果证明,LED结果还有很高的提升空间。此外,本文使用LED进行下游法律任务,包括法律判决预测和相似案例检索。这表明LED可以提供细粒度的信息,可以作为法律人工智能的基础流程。
参考文献
[1] Collin F. Baker, Charles J. Fillmore, and John B. Lowe.1998. The Berkeley FrameNet project. In COLING 1998 V olume 1: The 17th International Conference on Computational Linguistics.
[2] Anderson Bertoldi, Rove Chishman, Sandro José Rigo,and Thaís Domênica Minghelli. 2014. Cognitive linguistic representation of legal events. Proceedings of COGNITIVE.