构建一个能够根据多轮上下文选择适当回复的智能对话系统是一项极具挑战性的任务。现有研究的重点是构建具有各种神经架构或PLM的上下文回复匹配模型,并且通常使用单个回复预测任务进行学习。这些方法忽略了对话数据中包含的许多潜在训练信号,这可能有利于上下文理解并为回复预测产生更好的特征。此外,由传统方式监督的现有对话系统检索到的回复仍然面临一些关键挑战,包括不连贯和不一致。为了解决这些问题,在本文中,我们建议学习一个上下文回复匹配模型,该模型具有为基于预训练语言模型的对话数据设计的辅助自我监督任务。具体来说,我们引入了四个自监督任务,包括下一个会话预测、语段恢复、不连贯检测和一致性判别,并以多任务方式与这些辅助任务联合训练基于PLM 的回复选择模型。通过这种方式,辅助任务可以指导匹配模型的学习,以达到更好的局部最优,并选择更合适的回复。两个基准的实验结果表明,所提出的辅助自我监督任务为基于检索的对话中的多轮回复选择带来了显着的改进,并且我们的模型在两个数据集上都取得了新的最先进的结果。
1. 引言
建立一个可以自然而有意义地与人交谈的对话系统是高级人工智能最具挑战性的问题之一,并引起了学术界和工业界越来越多的兴趣。众所周知,用户画像可以让机器生成更多合适的回复。大多数现有的对话系统要么基于生成[1],要么基于检索[2]。给定对话上下文,基于生成的方法使用条件语言模型逐词合成回复,而基于检索的方法从候选池中选择适当的回复。在本文中,我们专注于基于检索的方法,这些方法在提供信息回复方面具有优势,并已广泛应用于微软的小冰[3]和阿里巴巴的AliMe的智能助手[4]。
我们考虑多轮对话中的回复选择任务,其中检索模型应该通过测量多轮对话上下文与多个回复候选之间的匹配度来选择最合适的回复。早期的研究[5]将上下文连接到单个话语并计算与语段级表示的匹配分数。后来,大多数回复选择模型[6]在表示-匹配-聚合范式中执行上下文回复匹配,其中每轮话语都单独表示序列信息在一系列话语回复匹配特征中聚合。为了进一步提高回复选择的性能,最近的一些方法考虑了多粒度(或层)表示[7]来匹配或提出更复杂的交互上下文和回复之间的机制[8]。
最近,大量研究表明,预训练语言模型 (PLM),例如 BERT[9]、XLNET[10]和 RoBERTa[11]大型语料库可以学习通用语言表示,这有助于下游的各种自然语言处理任务,并且可以摆脱从头开始训练新模型的麻烦。为了使预训练模型适应多轮回复选择[12]首次尝试利用BERT来学习匹配模型,其中上下文和候选回复首先是 拼接,然后输入用于计算最终匹配分数的PLM。这些预训练的语言模型可以很好地通过多个transformer层捕获话语间和语段间的交互信息。 尽管基于 PLM 的回复选择模型由于其强大的表示能力而表现出卓越的性能,但在训练过程中有效地学习任务相关知识仍然具有挑战性,尤其是在训练语料库规模有限的情况下。 自然,这些研究通常仅使用上下文回复匹配任务来学习回复选择模型,并忽略对话数据中包含的许多潜在训练信号。这样的训练信号可能有利于上下文理解,并为回复预测产生更好的特征。此外,由传统方式监督的现有对话系统检索到的回复仍然面临一些关键挑战,包括不连贯和不一致。
鉴于上述问题,在本文中,我们建议使用基于预训练语言模型。 具体来说,我们引入了四个自监督任务,包括下一个会话预测、语段恢复、不连贯检测和一致性判别,并以多任务方式与这些辅助任务联合训练基于 PLM 的回复选择模型。 一方面,这些辅助任务有助于提高回复选择模型理解对话上下文和衡量上下文与回复候选之间的语义相关性、一致性或连贯性的能力。另一方面,它们可以引导匹配模型以固定数量的训练语料有效地学习任务相关知识,并为回复预测产生更好的特征。
我们对多轮回复选择的两个基准数据集进行了实验:Ubuntu对话语料库[13] 和电子商务对话语料库[14]。评估结果表明,我们提出的方法在两个数据集上都明显优于所有最先进的模型。与之前最先进的方法相比,我们的模型在 Ubuntu 数据集的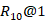 方面实现了 2.9% 的绝对改进,在电子商务数据集上实现了 4.8% 的绝对改进。 此外,我们将我们提出的自我监督学习模式应用于一些非基于 PLM 的回复选择模型,例如双 LSTM和 ESIM。 实验结果表明,我们的学习模式还可以为现有匹配模型的性能带来一致且显着的改进。令人惊讶的是,通过自我监督学习,一个简单的 ESIM 在ubuntu数据集上的表现甚至比 BERT 更好,这表明我们的方法对各种匹配架构都是有益的。
方面实现了 2.9% 的绝对改进,在电子商务数据集上实现了 4.8% 的绝对改进。 此外,我们将我们提出的自我监督学习模式应用于一些非基于 PLM 的回复选择模型,例如双 LSTM和 ESIM。 实验结果表明,我们的学习模式还可以为现有匹配模型的性能带来一致且显着的改进。令人惊讶的是,通过自我监督学习,一个简单的 ESIM 在ubuntu数据集上的表现甚至比 BERT 更好,这表明我们的方法对各种匹配架构都是有益的。
总之,我们的贡献有三方面: 我们建议学习具有多个辅助自监督任务的上下文回复匹配模型,以充分利用多轮对话上下文中的各种训练信号。我们设计了四个自我监督任务,旨在增强基于PLM 的回复预测模型在捕获语义相关性、连贯性或一致性方面的能力。我们在两个基准数据集上取得了最新的最新成果。 此外,在辅助自监督任务的帮助下,一个简单的 ESIM 模型甚至可以在 Ubuntu 数据集上取得比 BERT 更好的性能。
2. 相关工作
随着自然语言处理的进步,使用数据驱动的方法构建智能对话系统近年来引起了越来越多的兴趣。大多数现有方法要么基于生成,要么基于检索。前者通过自然语言生成技术逐字合成回复,而后者从一组候选者中选择最合适的回复。 在本文中,我们专注于基于检索的方法。 早期的研究关注构建单轮上下文回复匹配模型,其中仅考虑单个话语或将上下文中的多个话语连接成一个长序列以进行回复选择。最近,大多数研究都集中在多轮场景,即上下文中的每个话语首先与回复候选交互,然后根据多轮上下文的顺序依赖关系聚合匹配特征,他们通常采用表示匹配聚合范式来构建匹配模型。进一步考虑了用于匹配的多粒度表示。 此外,为了解决使用过多上下文的副作用利用多跳选择器来选择上下文中的相关话语以进行回复匹配。
最近,预训练的语言模型在各种下游 NLP 任务中显示出令人印象深刻的好处,一些研究人员试图将它们应用于回复选择,利用 BERT 来表示每个话语回复对并聚合这些表示来计算匹配分数。将上下文视为一个长序列,并与 BERT 执行上下文回复匹配。 此外,该模型还引入了在对话语料库的后期训练期间借鉴 BERT 的下一个话语预测和掩码语言建模任务,以将域内知识纳入匹配模型。建议将说话人感知嵌入启发式地合并到 BERT 中,以提高多轮对话中上下文理解的能力。
自监督学习已成为 AI 社区的一个重要方向,并为预训练语言模型的成功做出了贡献。 受此启发,一些研究人员提出用辅助的自我监督任务来学习下游任务。 通过这种方式,模型可以通过固定数量的训练数据有效地学习与任务相关的知识,并为主要任务产生更好的特征。 现有的工作已经探索了文本分类、摘要和回复生成方面的自我监督任务。这项工作的独特之处在于我们根据对话数据的特征设计了几个自我监督任务来改进多轮回复选择,我们的学习模式可以为传统的上下文回复匹配带来一致且显着的改进。。
3. 模型设计
任务定义:假设有一个多轮对话数据集 ,其中
,其中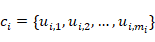 表示对话上下文,
表示对话上下文,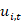 代表第t轮语段,
代表第t轮语段,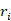 代表候选回复,
代表候选回复,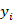 代表是否为的正确回复。任务是从
代表是否为的正确回复。任务是从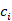 中学习匹配模型
中学习匹配模型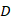 ,以便对于任何新上下文
,以便对于任何新上下文 和回复候选
和回复候选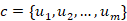 ,
,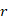 可以衡量c和r之间的匹配程度。
可以衡量c和r之间的匹配程度。
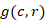 图1 模型整体架构
图1 模型整体架构
我们考虑使用预训练的语言模型构建上下文回复匹配模型,因为它在大量未标记数据上进行训练并提供强大的通用表示,可以在特定于任务的训练数据上进行微调,以在下游任务上实现良好的性能 . 根据之前的研究我们选择 BERT 作为基础模型进行公平比较。
具体来说,给定上下文 ,其中第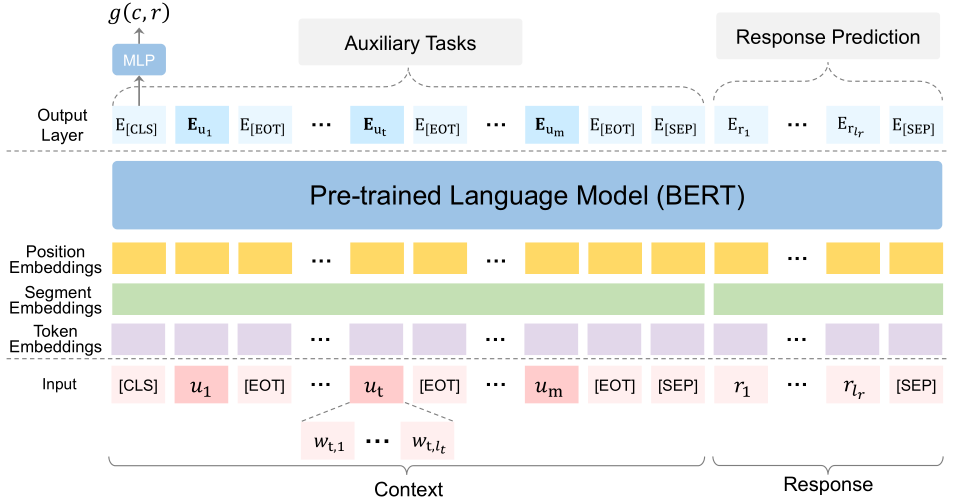 个语段是一个包含
个语段是一个包含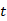 个单词的序列,候选回复
个单词的序列,候选回复 由
由 个单词和标签
个单词和标签 组成,我们首先将上下文中的所有话语和回复候选连接为单个连续的标记序列用特殊标记分隔它们,可以表示为
组成,我们首先将上下文中的所有话语和回复候选连接为单个连续的标记序列用特殊标记分隔它们,可以表示为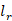 。 这里[CLS]和[SEP]是BERT的分类符号和分段分隔符号,[EOT]是专为多轮上下文设计的“End Of Turn”标签。对于
。 这里[CLS]和[SEP]是BERT的分类符号和分段分隔符号,[EOT]是专为多轮上下文设计的“End Of Turn”标签。对于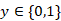 的每个单词,对的标记、位置和段嵌入进行求和,并在预训练的 Transformer 层(也称为 BERT)中进行计算,从而为我们提供上下文化的嵌入序列
的每个单词,对的标记、位置和段嵌入进行求和,并在预训练的 Transformer 层(也称为 BERT)中进行计算,从而为我们提供上下文化的嵌入序列 。
。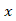 是一个聚合的表示向量,包含上下文-回复对的语义交互信息。然后我们将输入到多感知层以获得上下文回复对的最终匹配分数:
是一个聚合的表示向量,包含上下文-回复对的语义交互信息。然后我们将输入到多感知层以获得上下文回复对的最终匹配分数:
最后,使用交叉熵损失函数作为上下文回复匹配任务的训练目标:
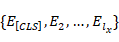
在使用上述上下文回复匹配任务进行微调之前,为了公平比较,我们遵循之前的研究并进行域自适应将领域内知识整合到BERT中的后期训练。 在本节的其余部分,我们将介绍我们提出的四个辅助自我监督任务,然后介绍我们模型的最终学习目标。
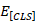
图2 四个自监督任务框架
为了寻找一种匹配模型,该模型可以通过固定数量的训练语料有效地学习领域知识并为回复预测产生更好的特征,我们设计了四个辅助的自我监督任务,即会话级匹配、话语恢复、不连贯检测和一致性分类。这些自监督任务试图增强模型测量上下文和回复候选之间的语义相关性、连贯性和一致性的能力。 另一方面,它们也可以指导模型的学习,以达到更好的局部最优。 图 2 展示了四种类型的自我监督任务的草图。
由于对话轮次之间的自然顺序关系,后轮次通常与上下文中的前轮次表现出强烈的语义相关性。 受此特征启发,我们设计了一个更通用的带有对话上下文的回复预测任务,命名下一个会话预测(NSP),以充分利用对话数据的顺序关系,增强模型测量语义相关性的能力。 具体来说,下一个会话预测任务需要模型预测两个序列是否连续且相关。 然而,模型需要计算两个对话会话之间的匹配度,而不是匹配上下文与回复话语。
形式上,给定上下文 ,我们随机将 c 分成两个连续的部分 和 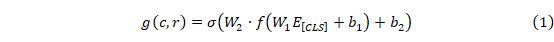 。 然后,有 50% 的机会,我们将
。 然后,有 50% 的机会,我们将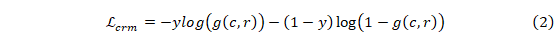 或
或 替换为从整个训练语料库中采样的一段上下文。如果两部分之一被替换,我们设置标签,否则
替换为从整个训练语料库中采样的一段上下文。如果两部分之一被替换,我们设置标签,否则 。 下一个会话预测任务要求模型区分和是否可以形成连续的上下文。为了使用提议的自我监督任务训练 PLM,我们首先将每个片段的所有话语连接为单个序列,并将 [EOT] 附加到每个话语的末尾。与主要任务类似,我们将两个片段输入 BERT 编码器并获得片段对
。 下一个会话预测任务要求模型区分和是否可以形成连续的上下文。为了使用提议的自我监督任务训练 PLM,我们首先将每个片段的所有话语连接为单个序列,并将 [EOT] 附加到每个话语的末尾。与主要任务类似,我们将两个片段输入 BERT 编码器并获得片段对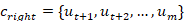 的聚合表示。 我们进一步计算最终匹配得分
的聚合表示。 我们进一步计算最终匹配得分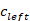 。
。
作为 PLM 中常见的自监督任务之一,标记级掩码语言建模通常用于指导模型学习具有双向上下文的词序列的语义和句法特征。 在这里,我们进一步介绍了话语级掩码语言建模,即话语恢复(UR)任务,以鼓励模型了解上下文中话语之间的语义联系。具体来说,我们掩盖了从对话会话中随机采样的话语中的所有标记,并让模型使用来自其余上下文的信息来恢复它。通过学习预测适合其周围对话上下文的适当话语,该模型可以产生更好的表示,可以很好地适应对话,类似于连续词袋模型的想法。
受语言学中话语连贯概念的启发,我们进一步引入了不连贯检测(ID)任务,该任务要求模型识别对话会话中的不连贯话语,以增强模型捕获的能力 话语之间的顺序关系和选择连贯的回复候选。 具体来说,给定对话上下文,我们随机选择一个话语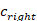 并将其替换为从整个训练中随机采样的话语语料库。然后,模型应该在上下文中找到不连贯的话语。 对于每个样本,我们定义一个单热标签
并将其替换为从整个训练中随机采样的话语语料库。然后,模型应该在上下文中找到不连贯的话语。 对于每个样本,我们定义一个单热标签  ,其中
,其中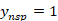 如果,表示第 个话语被替换,否则
如果,表示第 个话语被替换,否则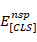 。
。
选择与对话上下文一致的回复是构建引人入胜的对话代理的主要挑战之一。 然而,大多数先前的研究都集中在对上下文和回复候选之间的语义相关性进行建模。直观地说,来自同一对话会话的话语往往具有相似的主题,来自同一对话者的话语往往具有相同的个性或风格。 根据这些特征,我们尝试通过利用对话数据的自然结构的自监督判别训练方案来增强回复预测模型测量一致性的能力。
形式上,给定对话上下文,我们从同一个对话者中采样两个话语,并将它们分别表示为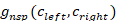 和 。 然后,我们从训练语料库的另一个上下文中随机抽取一个话语
和 。 然后,我们从训练语料库的另一个上下文中随机抽取一个话语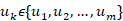 。 该模型需要衡量
。 该模型需要衡量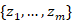 与
与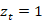 的一致性程度,并给予更高的分数。由于
的一致性程度,并给予更高的分数。由于 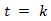 和
和 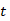 在对话上下文中不是连续的并且来自同一个对话者,因此鼓励模型捕获关于两个序列之间一致性(如主题、个性和风格)的特征,而不是语义相关性或连贯性。
在对话上下文中不是连续的并且来自同一个对话者,因此鼓励模型捕获关于两个序列之间一致性(如主题、个性和风格)的特征,而不是语义相关性或连贯性。
4. 实验
我们评估了用于多轮对话回复选择的两个基准数据集的建议方法。 第一个数据集是 Ubuntu Dialogue Corpus (v1.0),它由关于技术支持的多轮英文对话组成,收集自 Ubuntu论坛的聊天记录。 我们使用Gu等人共享的副本。其中数字、路径和 URL 被占位符替换。Ubuntu 数据集包含100万对用于训练的上下文回复对,以及50万对用于验证和测试。正例和负例的比例在训练集中是 1:1,在验证集和测试集中是 1:9。 第二个数据集是电子商务对话语料库,它由中国最大的电子商务平台淘宝上客户和客服人员之间的真实世界多轮对话组成。 电子商务数据集包含100万对用于训练的上下文回复对,以及 10000 对用于验证和测试的上下文回复对。正例和负例的比例在训练集和验证集中为 1:1,在测试集中为 1:9。
我们选择英文 uncased BERT base (110M) 作为 Ubuntu 数据集的上下文回复匹配模型和电子商务数据集的中文BERT模型。我们使用 https://github.com/huggingface/transformers 中的代码实现模型。上下文和回复的最大长度设置为 448 和 64,因为 BERT 中输入序列的最大长度为 512。直观地说,上下文中的最后一个标记和回复候选中的前一个标记更重要,所以我们切断上下文的先前标记,但如果序列长于最大长度,则对回复候选者进行反向截断。我们选择32作为 minibatch 的大小进行训练。在Ubuntu集和豆瓣数据集上,我们在按照 Whang 等人的设置进行微调之前应用了域自适应后训练。 。 辅助任务的训练实例是动态生成的。
表1 基线模型与本文模型的对比
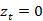
表1报告了 BERT-SL 和所有基线模型在Ubuntu数据集和电子商务数据集上的结果。从评估结果中,我们可以很容易地观察到,基于 PLM 的回复选择模型通常比基于各种神经架构的模型表现更好。该现象显示了预训练模型在提供强大的通用表示方面的优势。
表2 消融实验结果
为了调查不同自我监督任务的影响,我们进行了全面的消融研究。 我们保留匹配模型的架构,并从模型中单独删除每个自监督任务,并将模型表示为“BERT-SL w/o. T ”,其中 T ∈ {NSP, UR, ID, CD} 分别代表下一个会话预测、话语恢复、不连贯检测和一致性判别。 详细结果报告在表 1 的最后四行。首先,我们发现所有四个自监督任务都是有用的,因为删除其中任何一个都会导致两个数据集的性能下降。 其次,我们可以得出结论,在 Ubuntu 数据上,任务在 R 10 @1 方面的排名是 ID > NSP > CD > UR ; 而在电子商务数据上,任务的排名是 CD > ID > NSP > UR 5 。 在这四个任务中,ID 在改进回复选择任务方面起着重要作用。 原因可能是 ID 任务可以鼓励模型考虑上下文和回复候选之间的连贯性,这是对主要任务的补充。 还需要注意的是,删除话语恢复任务会导致两个数据集的性能略有下降,因为 UR 学习的特征可能与预训练中的令牌级掩码语言建模学习的特征是多余的。 此外,生成任务学习的表示可能有相当大的与判别任务的差异。 最后,CD 任务在电子商务数据上比在 Ubuntu 数据上更重要,因为电子商务语料库包含更多样化的内容。
ESIM/DualLSTM 的自监督学习。 我们很好奇所提出的自我监督学习模式的有效性是否取决于回复选择模型的架构。 因此,我们在一些非基于 PLM 的回复选择模型上测试了我们提出的学习模式,例如双 LSTM和ESIM。最初的两个模型将多轮上下文视为一个长序列,并且仅使用上下文回复任务进行训练。因此,我们实现了两个模型,并以多任务方式与提出的四个自监督任务联合训练它们。 表 报告了两个数据集的比较结果。我们观察到DualLSTM和ESIM的性能都有一致且显着的改进。特别是在辅助自监督任务的帮助下,一个简单的ESIM模型甚至可以在 Ubuntu 数据集上实现比 BERT 更好的性能,BERT是一个更大的预训练模型。结果表明我们的学习模式有利于各种匹配架构,并表明所提出方法的有效性和通用性。
5. 结论
在本文中,我们建议学习一个上下文回复匹配模型,该模型具有四个为对话数据设计的辅助自我监督任务。与这些辅助任务联合训练,匹配模型可以有效地学习对话数据中包含的任务相关知识,实现更好的局部最优,并产生更好的回复选择特征。两个基准的实验结果表明,所提出的辅助自我监督任务为基于检索的对话中的多轮回复选择带来了显着的改进,并且我们基于 PLM 的模型在两个数据集上都取得了新的最先进的结果。
参考文献
[1] Vinyals, O. and Le, Q. A neural conversational model. arXiv preprint arXiv:1506.05869, 2015.
[2] Wang, H., Lu, Z., Li, H., and Chen, E. A dataset for research on short-text conversations. In EMNLP, pp. 935–945, 2013.
[3] Shum, H.-Y., He, X.-d., and Li, D. From eliza to xiaoice: challenges and opportunities with social chatbots. Frontiers of Information Technology & Electronic Engineering, 19(1):10–26, 2018.
[4] Li, F.-L., Qiu, M., Chen, H., Wang, X., Gao, X., Huang, J., Ren, J., Zhao, Z., Zhao, W., Wang, L., et al. Alime assist: An intelligent assistant for creating an innovative e-commerce experience. In CIKM, pp. 2495–2498, 2017.
[5] Hu, B., Lu, Z., Li, H., and Chen, Q. Convolutional neural network architectures for matching natural language sentences. In NIPS, pp. 2042–2050, 2014.
[6] Devlin, J., Chang, M.-W., Lee, K., and Toutanova, K. BERT: Pre-training of deep bidirectional transformers for language understanding. In NAACL, pp. 4171–4186, 2019.
[7] Vinyals, O. and Le, Q. A neural conversational model. arXiv preprint arXiv:1506.05869, 2015.
[8] Shum, H.-Y., He, X.-d., and Li, D. From eliza to xiaoice: challenges and opportunities with social chatbots. Frontiers of Information Technology & Electronic Engineering, 19(1):10–26, 2018.
[9] Yang, Z., Dai, Z., Yang, Y., Carbonell, J., Salakhutdinov, R. R., and Le, Q. V. XLNET: Generalized autoregressive pretraining for language understanding. In NIPS, pp.5754–5764, 2019.
[10] Yuan, C., Zhou, W., Li, M., Lv, S., Zhu, F., Han, J., and Hu, S. Multi-hop selector network for multi-turn response selection in retrieval-based chatbots. In EMNLP, pp. 111– 120, 2019.
[11] Gu, J.-C., Li, T., Liu, Q., Ling, Z.-H., Su, Z., Wei, S., and Zhu, X. Speaker-aware bert for multi-turn response selection in retrieval-based chatbots. In CIKM, 2020.
[12] Whang, T., Lee, D., Lee, C., Yang, K., Oh, D., and Lim, H. An effective domain adaptive post-training method for bert in response selection. In Proc. Interspeech 2020, 2020.
[13] Liu, Y., Ott, M., Goyal, N., Du, J., Joshi, M., Chen, D., Levy, O., Lewis, M., Zettlemoyer, L., and Stoyanov, V.Roberta: A robustly optimized bert pretraining approach. arXiv preprint arXiv:1907.11692, 2019.
[14] Mikolov, T., Chen, K., Corrado, G., and Dean, J. Efficient estimation of word representations in vector space. arXiv preprint arXiv:1301.3781, 2013.