A Self-Training Method for Machine Reading Comprehension with Soft Evidence Extraction
最近,在自然语言处理(NLP)领域中,使用语言模型预训练方法在多项NLP任务上都获得了不错的提升,广泛受到了各界的关注。就此,我将最近看的一篇与之相关的论文和大家一起学习分享。该论文提出了一种新的预训练方式,用来对原有的BERT模型需要较大的计算量进行改进,并取得了一定的效果。
1. 摘要
深度神经网络网络在机器阅读理解(MRC)任务上得以成功应用,诸多经典的方法都是基于两个部分,一个是evidence extractor(证据抽取器),另一个是answer prediction(答案预测器)。其中前者目的是从上下文中寻找更相关的信息,后者则是根据抽取的信息生成答案。但是在一些是否问答或多项选择类型问答时,由于evidence extractor模块没有监督类信息使得训练并不简单。为了解决这个问题。我们提出一种Self-Training(自训练方法),通过迭代的过程自动生成evidence label实现对evidence extractor的模块的监督。在每一次迭代过程中,一个传统的MRC模型根据ground truth和noisy label进行训练,并将训练好的模型去预测一个结果作为下一个迭代过程的监督标签。
2. 动机
(1)机器阅读理解可以分为两个类:一个是基于抽取式问答,即根据question从passage中抽取一个span作为答案;另一种是非抽取式式,例如Yes/No是非类,或者选择类等。他们都基于一种范式,即在evidence extractor部分抽取证据信息,在answer prediction部分做预测。在抽取类MRC中,由于其有真实的span进行监督,因此很好训练;但是在非抽取式MRC中,数据集中只有答案,而没有在passage中的evidence span,这使得无法直接训练evidence extractor部分。
(2)这一类问题属于典型的只知道结果(answer),但不知道中间正确结果(evidence label),因此传统的方法典型的有基于人工标注golden evidence,远程监督,以及使用强化学习自主地发现evidence等。但是这类方法(尤其是强化学习)训练非常不稳定;同时远程监督方法也会带来大量噪声;
(3)Self-Training策略是一种迭代训练,在MRC任务中,即每次训练时,根据最终的结果golden answer以及上一轮预测得到的evidence label,一同进行训练;本轮预测的evidence label再次用于下一轮的;
3. Self-Training策略
在训练过程中,维护两个数据池,分别记做U(unlabeled data)和L(labeled data),两个数据池分别对应不包含evidence label和包含evidence label。首先在两个数据池上对MRC的base模型进行训练;其次训练好的模型对U数据池上数据进行预测;通过Selector模块挑选置信度最高的示例并转移到L数据池中。以此反复迭代,如下图所示:
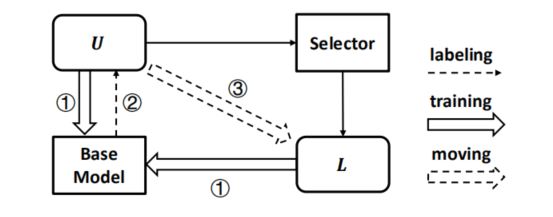
base model
(1)输入question Q和document D,其中D包含若干个句子S。
(2)token attention:根据Q与D中第i个句子的每个token计算权重,并对第i个句子的所有token进行加权求和,得到每个句子的表示:
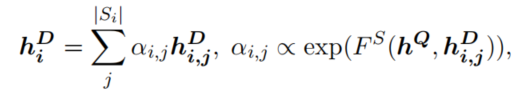
其次,每个句子根据自身再次计算每个token之间的权重,并加权去和得到句子的表示:
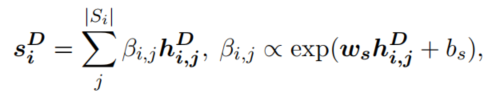
(3)sentence-level attention:根据每个句子的表示,学习一个权重并对所有句子进行加权求和,得到整个文档的表示:
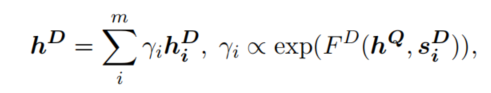
理解:句子被分配权重越高,说明该句子对预测的贡献越大。
loss
loss分为两个部分,一个是根据golden answer使用negative log损失函数,这部分和传统的目标一样,本文记做task-specific loss
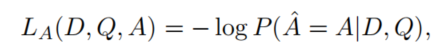
第二部分是本文的核心,记做evidence loss:
假设我们的目标是要挑选K个evidence sentence,我们一步步地计算loss。第一步step,挑选最合理的句子(理解为权重最大的)并计算loss,第二步step在剩余的句子上计算loss,而前面已经被挑选的句子则不再计算loss;最终所有step的loss进行平均,直到K个evidence sentence全部挑选完成。第二部分的loss公式可以定义为:
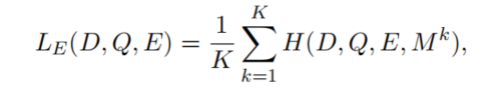
其中 D , Q , E D,Q,ED,Q,E 分别表示document,question和evidence label(0/1值),
表示mask。
对于每一个step,均在unselected的句子上计算权重,不过要注意的是,其本质是在所有sentence上计算权重,但是为了不去计算已被挑选的sentence,则显式添加一个mask。因为在计算attention时,神经网络的输出维度是固定的,即sentence总的数量没法变,因此只能通过添加mask方法来控制已被挑选的句子不去计算attention,这部分比较类似于transformer中的mask,通过添加一个非常小的数使得其权重接近于0:
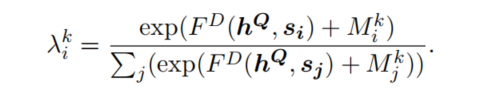
因此每个step的loss表示为:

其中mask矩阵中,已被挑选的句子设置为非常小的数(无穷小),未被挑选的句子则使用上一step的mask值:
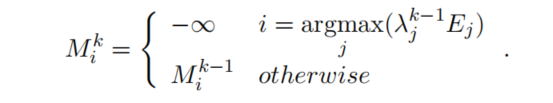
最终模型的loss是task-specific和evidence两个loss的和。
Selector
事实上,每一个迭代包含两个部分,一个就是上面介绍的训练,另一个就是在U数据池上进行预测,并挑选置信度高的。假设在一个包含evidence label的数据上,作者定义置信度为

即两个loss的负数的指数乘积,事实上其表示loss越小,其置信度就越高。对于预测的evidence label则可以通过上面的式子重新计算一次loss,并获得置信度,挑选两个loss分别都低于阈值的样本加入到L数据池中。
4.结果
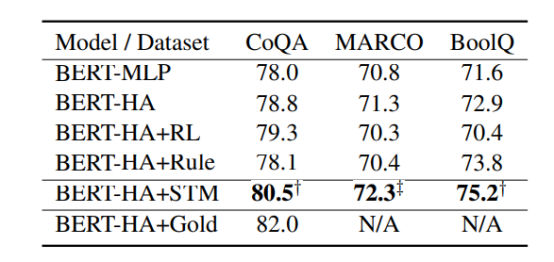
在这些数据上做的都是YES/NO二分类很奇怪第三行加入RL(强化学习)的方法在MARCO和BoolQ数据集的准确率都比基线低或者说差不多,反而降低了准确度,作者并没有给出解释,添加rule的方式也是(期待作者能够开源代码)。还有就是最后一行的数据,论文中说MARCO原数据提供了evidence label,但是这个表中这列的数据不对。可能不是最终提交版本,是挂在arxiv上未更新的原因吧。后面的实验数据可以看出,RL在其中是有一定的作用的
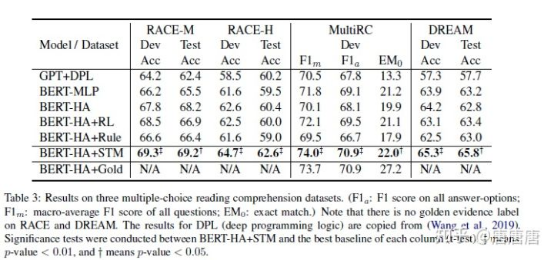
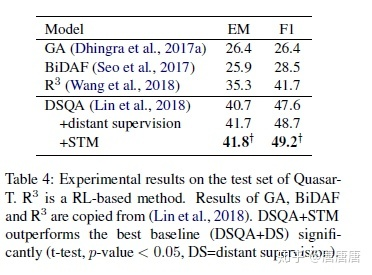
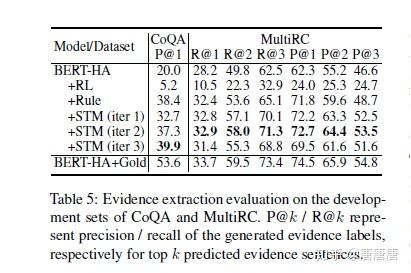
总的来说,这篇论文把半监督引入了阅读理解任务。