信息提取的目标不同,结构不同,需要特定的模式。本文提出了一个统一的文本到结构生成框架,即UIE,它可以通用地为不同的IE任务建模,自适应地生成目标结构,并从不同的知识来源协同学习通用的IE能力。具体来说,UIE通过一种结构化的提取语言对不同的提取结构进行统一编码,通过一种基于模式的提示机制——结构化模式讲师自适应地生成目标提取,并通过一个大规模的预先训练的文本-结构模型来捕获常见的IE能力。实验表明,UIE在4个IE任务、13个数据集和所有有监督的、低资源的、少镜头的设置上,对于广泛的实体、关系、事件和情感提取任务及其统一,都达到了最先进的性能。这些结果验证了UIE的有效性、通用性和可移植性。
1. 背景知识
论文题目为Unified Structure Generation for Universal Information Extraction。文章发表在ACL2022上。论文地址为https://arxiv.org/abs/2203.12277,源码链接为https://universal-ie.github.io/。
1.1 挑战
目前,大多数IE方法都是任务专门化的,这导致了针对不同IE任务的专用架构、隔离模型和专门的知识来源。这些任务专门化的解决方案极大地阻碍了IE系统体系结构的快速发展、有效的知识共享和快速的跨领域适应。首先,为大量的IE任务/设置/场景开发专用架构是非常复杂的。第二,学习孤立的模型严重限制了相关任务和设置之间的知识共享。最后,为不同的IE任务构建专门的数据集和知识库是昂贵和耗时的。因此,开发一种通用的IE架构,能够对不同的IE任务进行统一的建模,将是非常有益的。
1.2 IE任务的共同点
分析不同的IE任务结构,我们可以从图中看到,实体是一个命名的span结构,事件是一个模式定义的记录结构。IE中的这些文本到结构的转换可以进一步分解为几个原子转换操作:首先是Spotting,它根据给定的语义类型定位所需的范围。例如,将span“Steve”定位为Person实体,将“excited”定位为情感表达。其次是Associating,它通过在预定义的模式中为跨区域分配语义角色来连接跨区域。例如,通过将“Steve”和“Apple”指定为“Work-for”关系的主体和客体来关联它们。通过这种方式,不同的IE任务可以分解为一系列原子文本到结构的转换。
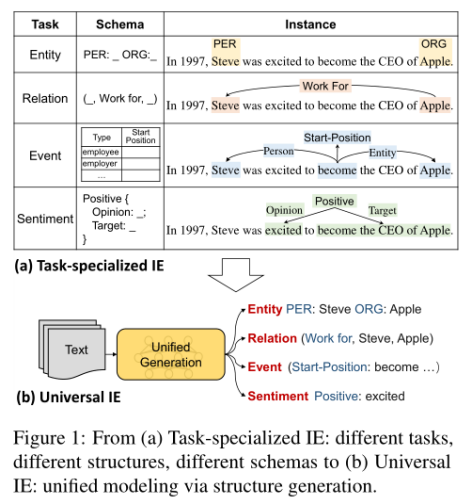
图1 从(a)任务专门化的IE:不同的任务,不同的结构,不同的模式到(b)通用的IE:通过结构生成进行统一建模。
1.3 提出
基于以上观察,我们提出UIE,一个统一的文本-结构生成架构。具体地说,我们设计了一种结构提取语言(SEL),它可以有效地将不同的IE结构编码为统一的表示,以及一个结构模式讲师(SSI),一种基于模式的提示机制,它控制在UIE中发现什么、关联什么和生成什么。
2. 整体框架
让我们更详细地看看SEL部分。如图所示,我们可以看到每个SEL表达式都包含三种类型的语义单元。SPOTNAME / ASSONAME和INFOSPAN。图2b显示了如何使用SEL。有三个实体,每个实体都被表示为一个定点结构,如“人:史蒂夫”,“组织:苹果”,和“时间:一千九百九十七”;一种关系表示为“Steve”和“Apple”之间的关联结构,关联名称为;一个事件被表示为一个关联结构,触发点是一个发现结构“start-position:became”,它的参数与触发点相关:史蒂夫是雇员,苹果是雇主,时间是一千九十九十七。我们可以看到SEL具有对不同IE结构统一编码的优点,因此可以将不同的IE任务建模为相同的text-to-structure生成过程。生成的输出结构非常紧凑,大大降低了解码的复杂度。

图2 结构抽取语言的插图
接下来是SSI部分,结构模式指导程序包含三种类型的标记段:1)SPOTNAME/ ASSONAME和特殊符号,它们被添加在每个SPOTNAME、ASSONAME和输入文本序列之前。SSI中的所有标记都被连接起来并放在原始文本序列之前。
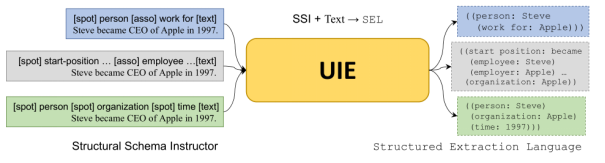
图3 UIE的总体框架
接下来看UIE的整体框架。形式上,UIE将给定的结构模式讲师和文本序列(x)作为输入,UIE计算每个标记的隐藏表示。其中Encoder是一个Transformer编码器。UIE在SEL序列中生成令牌YI,解码器状态为HD,如下所示。译码器是一个变压器译码器,它预测令牌YI的条件概率。
作者还对三个不同语料库进行了预训练。D pair是文本结构并行数据,其中每个实例是一个并行对(令牌序列x,结构化记录y),用于预训练UIE的文本到结构的转换能力。为了学习一般的映射能力,我们还会为每对自动构造负模式。D record是结构数据集,其中每个实例都是结构化记录y,用于预训练UIE的结构解码能力。D text是非结构化文本数据集,用于预训练UIE的语义编码能力。
3. 实验结果
为了验证UIE的有效性,我们在不同的IE任务和设置下进行了实验。
3.1 全监督实验
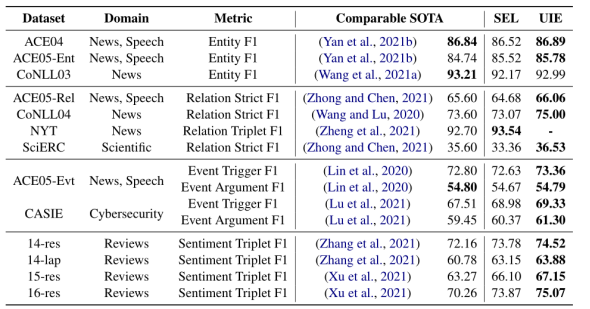
如表所示,展示了Supervised Settings实验的结果。SEL指的是没有预先培训的UIE。我们可以观察到:UIE在4类信息提取任务、13个数据集和7个字段中都实现了SOTA性能。通过对比SEL和UIE的结果可以看出,pre-training可以显著提高UIE的一般信息提取能力,具有较好的跨任务迁移能力。
表1 全监督实验结果
3.2 小样本实验
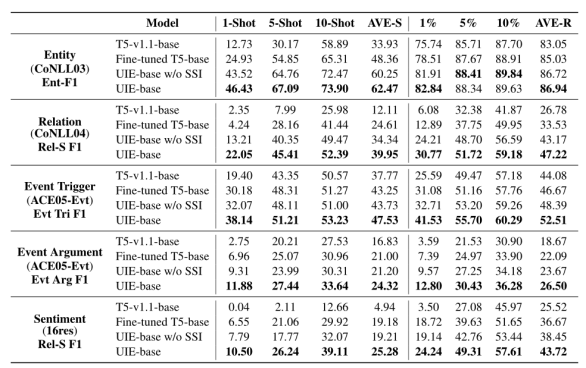
我们对原始训练集的6个不同分区进行了4个任务的低资源实验。我们观察到:大规模的异构监督预训练可以学习一般信息提取能力,使模型具有较好的小样本学习能力。当SSI去除后,各项指标下降。因此,结构化提取指令具有更好的定向迁移能力。
表2 小样本实验结果
3.3 抑制噪声的影响实验
本实验研究了提出的抑制噪声的影响。表中显示了在10次射击设置下,不同的预训练模型在开发集上的结果。错误生成的标签会对所提生成方法的精度产生负面影响,导致大量错误的提取结果。提出的抑制噪声的产生方法是有用的,导致平均改善。
表3 预抑制噪声的影响实验结果

参考文献
[1] Wasi Ahmad, Jianfeng Chi, Tu Le, Thomas Norton,Y uan Tian, and Kai-Wei Chang. 2021. Intent classification and slot filling for privacy policies. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (V olume 1: Long Papers), pages 4402-4417, Online. Association for Computational Linguistics.
[2] Peggy M. Andersen, Philip J. Hayes, Steven P . Weinstein, Alison K. Huettner, Linda M. Schmandt, and Irene B. Nirenburg. 1992. Automatic extraction of facts from press releases to generate news stories. In Third Conference on Applied Natural Language Processing, pages 170–177, Trento, Italy. Associationfor Computational Linguistics.
[3] Heng Ji and Ralph Grishman. 2011. Knowledge base population: Successful approaches and challenges.In Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies, pages 1148–1158, Portland,Oregon, USA. Association for Computational Linguistics.