题目
One Model to Serve All: Star Topology Adaptive Recommender for Multi-Domain CTR Prediction
1论文介绍
本文发表于CIKM 2021年。在业务场景数量快速扩张的背景下,多场景联合建模可以提高算法性能。STAR模型首先对每个场景分别建模,然后使用共享参数进行联合建模,获得最优结果。
2论文原理
2.1任务介绍
CTR预估任务作为推荐系统的一个重要任务,其目标是利用模型来预测目标广告的点击率。传统的行业推荐系统通常使用数据单个域训练模型,然后服务于该域。然而,一个大型商业平台通常包含多个领域,它的推荐系统经常需要点击率(CTR)预测的多个领域。一般来说,不同的域可以共享一些常见的用户组和项,并且每个域可以有自己独特的用户组和项。
例如,有两个具有代表性的业务域。如图所示,横幅和猜猜你喜欢淘宝移动应用程序主页。


(左图)Banner:在Banner中,被推荐的商品出现在淘宝首页的顶部Banner中。项目可以是单一商品、商店或品牌。
(右图)Guess What You Like:在Guess What You Like中,所有商品都是单一商品,显示在左栏或右栏
可以发现,在不同的域,由于是对同一用户进行推荐,因此这些域存在一些共同性。
由于不同的业务领域具有重叠的用户组和项,因此这些领域之间存在共性。启用信息共享有利于了解每个领域的CTR模型。
但是,具体的用户组可能不同,不同领域的用户行为也会发生变化。这些区别导致了特定于领域的数据分布。简单地混合所有的数据和训练一个共享的CTR模型不能很好地工作在所有领域。因此,本文采用多领域学习的方法进行推荐。
2.2模型结构
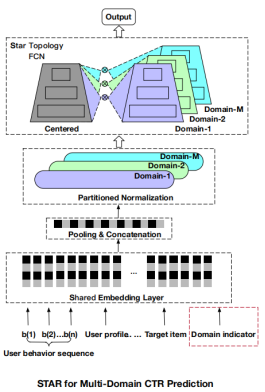
为了解决这些问题,研究人员提出STAR。该模型的核心是在每个域中维护自己的域模型,同时通过更新共享的域模型来连接不同的域。星形结构如图所示
接下来让我们看一下模型的细节。
2.2.1 模型输入
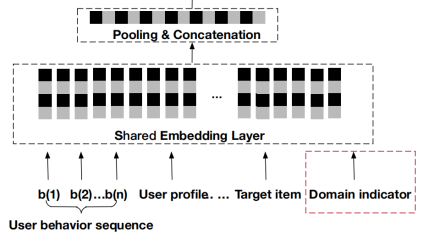
模型的输入由用户行为、用户配置文件、目标项和域指标组成。在所有数据通过嵌入层嵌入之后,SRAT的输入是通过池化和连接获得的。
这里我们令p为域指示器,则我们可以得到输入

2.2.2 模型组成
在获得模型输入之后,我们开始引入模型体系结构。STAR由三个主要部分组成:
分区标准化(PN),它将来自不同领域的标准数据私有化,如图所示,
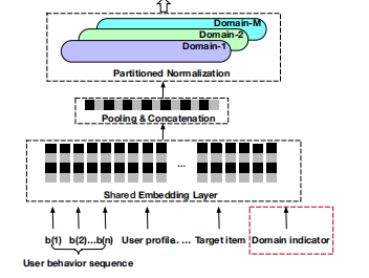
一般的标准化我们可以使用分区标准化(BN)来进行。但是在本文中,不同域的数据具有不同的归一化矩,BN模糊了域差异,导致模型性能下降。因此STAR使用分区归一化(Partitioned Normalization, PN)对数据进行归一化,PN的计算公式如下:
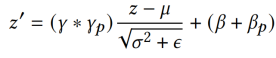
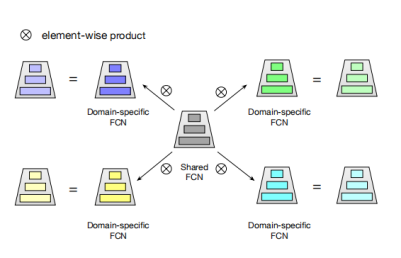
STAR的第二部分是星型拓扑全连接神经网络(星型拓扑FCN),
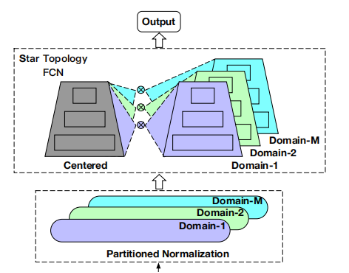
如图所示,提出的星型拓扑FCN由中心共享的FCN和每个域独立的FCN组成,因此FCN的总数为M+ 1,其中M为域的数量。对于共享的FCN,取W为权重,b为神经网络层的偏置。对于第p个域的具体FCN,输出由图中所示公式得到

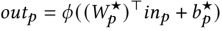
STAR的最后一个模块是辅助网络。
辅助网络直接将域指示符作为输入特征,学习其语义嵌入以获取域区别。简单地说,辅助网络的作用就是增加关于域特征的信息特征,将星形拓扑FCN的一维输出记为sm,将辅助网络的输出记为sa,即可得到CTR预测结果
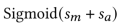
STAR以最小交叉熵损失为损失函数,计算公式如下:
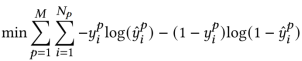
至此,我们可以得到STAR的完整结构,其核心思想是通过保持一个共享的FCN来调整各个领域的FCN参数,整体模型图如下:
3论文结果
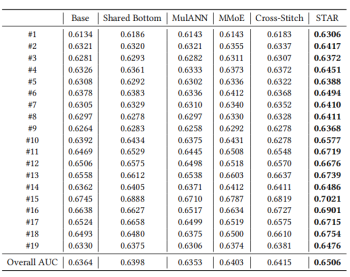
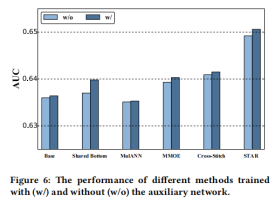
4消融实验
本文对STAR拓扑FCN和PN进行消融实验,结果如下图所示