这篇论文发表于ACL2022,关注于将机器阅读理解方法应用于命名实体识别任务。最近的工作将命名实体识别看作阅读理解任务,手工构建特定于类别的query来抽取实体。但这种范式存在三个问题。一是特定于类别的query每次推断只能抽取一种实体,效率较低;二是不同类别实体之间的抽取是独立的,忽略了实体之间的依赖关系;三是query的构建依赖于外部知识使其很难应用到具有上百种实体的现实场景。文本提出了Parallel Instance Query Network(PIQN)解决了上述问题,并在嵌套和非嵌套实体数据集上进行实验,证明了本文提出的方法优于SOTA模型。
1. 引言
命名实体识别是自然语言处理中的一项基本任务。 最近的工作将命名实体识别视为一项阅读理解任务,手动构建特定于类型的查询来抽取实体。这种范式存在三个问题,例如,对句子“U.S. President Barack Obama and his wife spent eight years in the White House”,模型以自然语言形式构造特定于人物类型的查询,如“Find person entity in the text, including a single individual or a group”,从而抽取人物实体, 如“U.S. President”和“Barack Obama”。 但是,由于查询是特定类型的,因此每次推理只能提取一种类型的实体。这种方式不仅导致预测效率低下,而且忽略了不同类型实体之间的依赖关系,例如“U.S.”和“U.S. President”。此外,特定类型的查询依赖于外部知识进行人工构建,难以适应具有数百种实体类型的现实场景。
在本文中,作者提出了并行实例查询网络(PIQN),其中全局和可学习的实例查询替换特定类型的查询以并行提取实体。如图1中(b)所示,每个实例查询预测一个实体,可以同时输入多个实例查询来预测所有实体。与以前的方法不同,将查询构造为自然语言形式不需要外部知识。实例查询可以在训练期间学习不同的查询语义。由于实例查询的语义是隐含的,因此模型无法提前将真实实体分配为其标签。为了解决这个问题,作者将标签分配视为一对多的线性分配问题(LAP),并设计了一种动态标签分配机制来为实例查询分配真实实体。

图1 特定于类型的查询和实例查询
2. 模型
如图2所示,该模型由三个组件组成:编码器、实体预测和动态标签分配。编码器对句子和实例查询进行编码。然后对于每个实例查询,模型分别使用实体指针和实体分类器进行实体定位和实体分类。为了训练模型,作者引入了一种动态标签分配机制,将真实实体分配给实例查询。
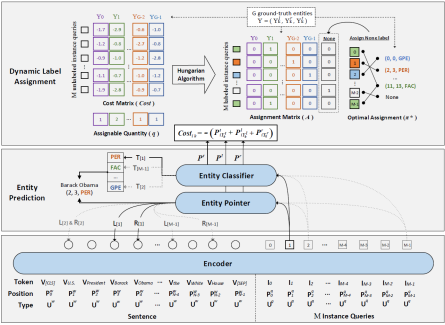
图2 模型总体结构
2.1 任务定义
作者使用 来表示一个训练样本,其中
来表示一个训练样本,其中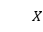 是由
是由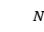 个词组成的句子,由三元组集合
个词组成的句子,由三元组集合 标记,
标记, 。
。 分别是第
分别是第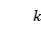 个实体的左边界、右边界和实体类别对应的索引。本文中,作者建立
个实体的左边界、右边界和实体类别对应的索引。本文中,作者建立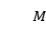 个全局可学习的实例查询
个全局可学习的实例查询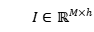 ,每个实例查询从句子中抽取一个实体。它们使用随机方法进行初始化,在训练过程中自动地学习查询的语义信息。
,每个实例查询从句子中抽取一个实体。它们使用随机方法进行初始化,在训练过程中自动地学习查询的语义信息。
2.2 编码器
模型的输入包括两个序列,句子和实例查询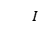 。编码器将它们合并放到一个序列中并同时编码。
。编码器将它们合并放到一个序列中并同时编码。
(1)输入的词嵌入
使用如下方法计算两个序列的token嵌入 ,位置嵌入
,位置嵌入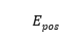 和类型嵌入
和类型嵌入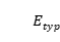 .
.

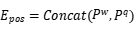

输入可以表示为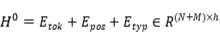
(2)One-Way自注意力
正常的自注意力机制会让句子与所有实例查询交互。通过这种方式,随机初始化的实例查询可以影响句子编码并破坏句子的语义。为了使句子语义与实例查询隔离,作者将BERT中的自注意力替换为单向版本:

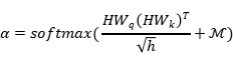
其中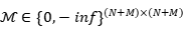 是注意力分数的mask矩阵,该矩阵右侧上方的
是注意力分数的mask矩阵,该矩阵右侧上方的 区域的元素都将设置为
区域的元素都将设置为 ,其他元素都是0,这样可以防止句子编码参与到实例查询中。
,其他元素都是0,这样可以防止句子编码参与到实例查询中。
2.3 实体预测
每个实例查询可以从句子中预测一个实体,使用M个实例查询,最多可以并行预测M个实体。实体预测可以看作是边界预测和类别预测的联合任务。作者分别为它们设计实体指针和实体分类器。
(1)实体指针
对于第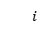 个实例查询
个实例查询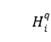 ,我们首先通过两个线性层将查询和句子的每个单词进行交互。第个实例查询和第
,我们首先通过两个线性层将查询和句子的每个单词进行交互。第个实例查询和第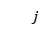 个单词的融合表示计算为:
个单词的融合表示计算为:

其中, 表示左右边界。之后计算句子中第
表示左右边界。之后计算句子中第 个词是左右边界的概率:
个词是左右边界的概率:
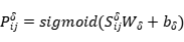
(2)实体分类器
实体的边界信息对实体分类是有用的。文中使用 来代表所有词的权重,然后将它们和实例查询拼接。第个实例查询的边界表示可以计算为:
来代表所有词的权重,然后将它们和实例查询拼接。第个实例查询的边界表示可以计算为:
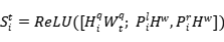
然后我们可以得到第 个实例查询所查询的实体属于类别
个实例查询所查询的实体属于类别 的概率:
的概率:
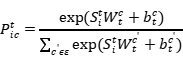
最后被第个实例查询预测的实体为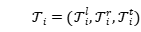 。分别为实体的左边界、右边界和实体类别。模型对所有实例查询执行实体定位和实体分类,以并行提取实体。如果多个实例查询定位到同一个实体但预测不同的实体类型,模型只保留分类概率最高的预测。
。分别为实体的左边界、右边界和实体类别。模型对所有实例查询执行实体定位和实体分类,以并行提取实体。如果多个实例查询定位到同一个实体但预测不同的实体类型,模型只保留分类概率最高的预测。
2.4 训练中的动态标签分配
由于实例查询是隐式的(不是自然语言形式),不能提前为它们分配真实实体。为了解决这个问题,作者在训练期间为实例查询动态分配标签。具体来说,将标签分配视为线性分配问题。任何实体都可以分配给任何实例查询,产生一些可能因实体查询分配而异的成本。定义将第个实体分配给第个实例查询的损失如下:
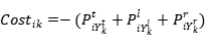
要求分配尽可能多的实体,每个查询最多分配一个实体,每个实体最多分配一个查询,以使分配的总成本最小化。但是,一对一的方式并没有充分利用实例查询,很多实例查询没有分配给黄金实体。因此,我们将传统的LAP扩展到一对多,其中每个实体都可以分配给多个实例查询。该一对多LAP的优化目标定义如下:
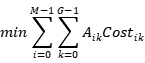
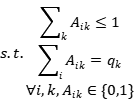
其中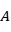 是分配矩阵,
是分配矩阵, 代表第
代表第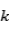 个真实实体可分配的数量。之后使用匈牙利算法求解上述公式。由于实例查询的数量远比实体标签可分配的数量要多,有些实体查询不会分配给任何实体标签。我们使用None标签标记它们。
个真实实体可分配的数量。之后使用匈牙利算法求解上述公式。由于实例查询的数量远比实体标签可分配的数量要多,有些实体查询不会分配给任何实体标签。我们使用None标签标记它们。
训练的损失包括边界损失和分类损失,损失的计算公式如下:
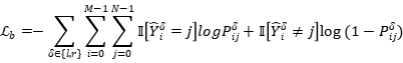
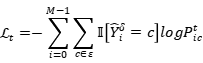
3. 实验
3.1 数据集
为了证明模型的有效性,作者在8个英文数据集(包括5个嵌套实体识别数据集和3个非嵌套实体识别数据集)和1个中文非嵌套实体识别数据集上进行了实验。
3.2 评价指标
精确率、召回率、F1值
3.3 结果与分析
(1)总体效果
实验结果如图3所示。图中展示了本文提出的模型和baseline模型在嵌套实体识别数据集中的性能。可以看到嵌套NER数据集的性能比以前的最先进模型有显著提升。此外,模型在FewNERD和MSRA数据集上实现了最先进的性能。在CoNLL03和OntoNotes数据集上,模型也取得了可比较的结果。

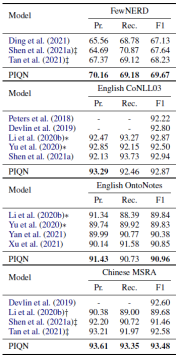
图3 实体识别数据集的实验结果
(2)推理速度
作者在ACE04和NNE数据集上比较了模型的推理速度。与特定类型的查询方法相比,本文模型不仅提高了性能,而且还获得了显着的推理加速。这是因为之前的模型需要对每个特定类型的查询进行一次推理,而本文中的方法对所有实例查询执行并行推理,并且只需要运行一次。

图4 推理速度的实验
(3)消融分析
作者分析了模型中不同组件对性能的影响。与按出现顺序的静态标签分配相比,动态标签分配有着显著的提升。此外,一对多标签分配比一对一更有效。单向自注意力阻止了对实例查询的句子编码的注意力,这说明了保持句子语义独立于查询的重要性。相反,查询之间的语义交互是有效的。
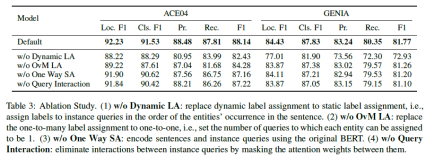
图5 消融分析实验
4. 结论
在本文中,作者提出了用于嵌套NER的并行实例查询网络,其中一组实例查询同时输入到模型中,并且可以并行预测所有实体。实例查询可以在训练期间自动学习与实体类型或实体位置相关的查询语义,避免依赖外部知识的手动构造。为了训练模型,作者设计了一种动态标签分配机制来为这些实例查询分配黄金实体。在嵌套和非嵌套NER数据集上的实验表明,所提出的模型实现了最先进的性能。