论文名:
《Learning Relationships between Text, Audio, and Video via Deep Canonical Correlation for Multimodal Language Analysis》
《通过多模态语言分析的深度典型相关学习文本、音频和视频之间的关系》
研究背景
(1) 多模态语言分析:通常考虑基于文本的特征与基于声学和视觉属性的特征之间的关系。
(2) 多模态情感分析:文本特征通常优于非文本特征,存在强弱模态之分。
(3) 造成各模态强弱区别的原因:
a) 文本特征源自在海量数据源上训练的高级语言模型或词嵌入,而音频和视频特征是人工设计的且相对欠发达。
b) 文本本身包含大量与情感相关的信息。
c) 视觉或听觉信息有时可能会混淆情绪或情绪分析任务。
(4) 现有算法的劣势:尽管以往的方法通过挖掘跨模态的交互信息,有助于学习多模态特征。但它们通常忽略了基于文本的音频和基于文本的视频之间隐藏的相关性。
(5) 各模态特征的相关性:很明显,将音频和视频特征附加到相同的文本信息可以使非文本信息更好地被理解,进而非文本信息可以赋予文本更大的意义。因此,研究基于文本的音频和基于文本的视频特征之间更深层次的相关性是合理的。
(6) 数据集
a) CMU-MOSI+CMU-MOSEI:基于YouTube 电影评论的多模态数据集,有极性标签和具体情感的标签。
b) IEMOCAP:该数据集包含 302 个视频,其中说话者表现出 9 种不同的情感(愤怒、兴奋、恐惧、悲伤、惊讶、沮丧、快乐、失望和无情感)。
典型关联性分析
在线性回归中,我们使用直线来拟合样本点,寻找n维特征向量X和输出结果(或者叫做label)Y之间的线性关系。其中 ,
,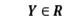 。然而当Y也是多维时,或者说Y也有多个特征时,我们希望分析出X和Y的关系。
。然而当Y也是多维时,或者说Y也有多个特征时,我们希望分析出X和Y的关系。
若采用回归的方法进行分析的话,做法如下:

其中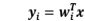 ,形式和线性回归一样,需要训练m次得到m个
,形式和线性回归一样,需要训练m次得到m个 。这样做的一个缺点是,Y中的每个特征都与X的所有特征关联,Y中的特征之间没有什么联系。
。这样做的一个缺点是,Y中的每个特征都与X的所有特征关联,Y中的特征之间没有什么联系。
换一种思路来看这个问题,如果将X和Y都看成整体,考察这两个整体之间的关系。我们将整体表示成X和Y各自特征间的线性组合,也就是考察 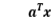 和
和 之间的关系。
之间的关系。
这样的应用其实很多,举个简单的例子。我们想考察一个人解题能力X(解题速度 ,解题正确率
,解题正确率 )与他/她的阅读能力Y(阅读速度
)与他/她的阅读能力Y(阅读速度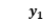 ,理解程度
,理解程度 )之间的关系,那么形式化为:
)之间的关系,那么形式化为:
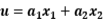 , v
, v
然后使用Pearson相关系数来度量u和v的关系,我们期望寻求一组最优的解a和b,使得Corr(u,v)最大,这样得到的a和b就是使得u和v就有最大关联的权重。公式如下:
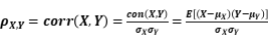
安德鲁等人于2013年提出了CCA的DNN扩展,称为深度CCA(DCCA)。在DCCA中,两个DNN f和g用于提取每个视图的非线性特征以及提取的特征 和
和 最大化:
最大化:

普通的CCA只适用于线性情景,但DCCA不仅能够解决线性问题,对于非线性的情景也同样适用。

模型
a) 各模态特征提取
之前的研究表明,外积能够有效地学习不同特征之间的交互。因此,受到TFN模型的启发,本文使用外积来表示text-video和text-audio特征。
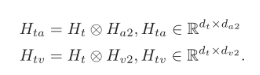
鉴于外积和 DCCA 应用于话语(句子)级别,我们独立地提取每个单模态的话语级别特征,以便更直接地测试ICCN的有效性。

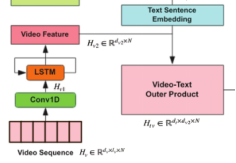
b) ICCN模型整体结构
交互规范相关网络(ICCN),它在基于 DCCA 的网络中提取 CNN 的交互特征。最后,描述了在多模态语言分析任务中使用该方法的整个流程。
用于对齐基于文本的音频特征和基于文本的视频特征的
ICCN 方法。句子级单模态特征是独立提取的。文本音频和文本视频的外积矩阵用作 Deep CCA 网络的输入。在使用 CCA Loss 学习 CNN 的权重后,将两个 CNN 的输出与原始文本连接起来,形成多模态嵌入。这可以用作独立下游任务的输入。
I
CCN
模型如下图所示:
ICCN方法充当特征提取器。为了测试它的性能,还需要一个额外的下游分类器。可以使用各种简单的提取方案以及通过使用更复杂的基于神经网络的模型(例如顺序 LSTM)学习特征来提取单模态特征。一旦获得了文本、视频和音频的单模态特征,ICCN 就可以用于学习基于文本的音频特征  和基于文本的视频特征
和基于文本的视频特征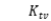 。
。
最终的多模态嵌入为上述特征的串联,表示为: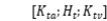 。
。
可以用作下游分类器的输入,例如逻辑回归或多层感知器。
该模型的算法流程如下:

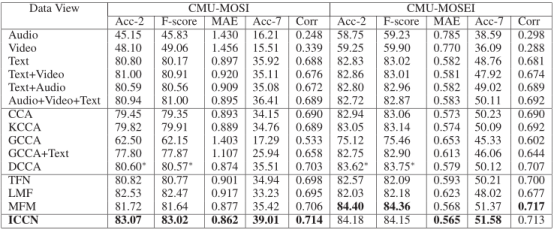
1. 实验结果
总结
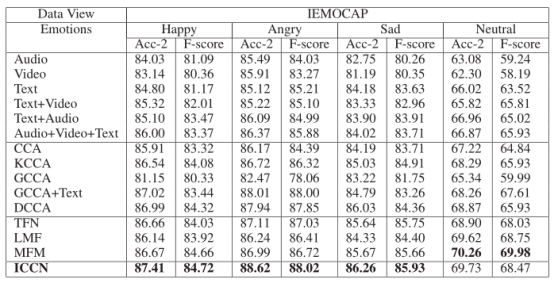
a) 与使用单模态和简单连接的结果相比,ICCN 在所有标准中都优于所有这些。请注意,文本特征的性能始终优于音频和视频的性能,文本、视频和音频的简单串联效果不佳。这表明高度发达的预训练文本特征能够提高整体多模态任务性能的进步。然而,它也展示了如何将如此高度发达的文本特征与音频和视频特征有效结合的挑战。
b) ICCN 也优于其他基于 CCA 的方法。使用其他基于 CCA 的方法的结果表明,它们无法提高多模态嵌入的性能。我们认为这是因为:1) CCA / KCCA / GCCA 没有利用神经网络架构的力量,因此它们的学习能力是有限的。 2) 在不学习基于文本的音频和基于文本的视频之间的交互的情况下使用 DCCA 可能会牺牲有用的信息。
c) 与其他基于神经网络的最先进方法(TFN、LMF 和 MFM)相比,ICCN 仍然取得了更好或相似的结果。这些结果证明了 ICCN 的竞争力。
d) 使用 CCA 损失比使用带或不带外积的 Cosine-Similarity Loss 表现得更好。这是合理的,因为 DCCA 能够学习隐藏关系(借助非线性变换),但余弦相似性受到原始坐标的限制。为了进一步验证这一点,我们还记录了基于文本的音频和基于文本的视频之间(即 ICCN 中 CNN 的两个输出之间)的典型相关性和余弦相似性的变化,方法是使用 ICCN 的 CCA 损失或余弦相似性损失,使用MOSI 数据集。结果表明,通过使用 CCA Loss 最大化典型相关并不一定会增加余弦相似度,反之亦然。这表明典型相关是与余弦相似度真正不同的目标函数,并解释了下游应用程序中的不同行为。 CCA 能够学习余弦相似度看不到的输入之间的隐藏关系。
e) 学习非文本和文本之间的交互比直接使用音频和视频效果更好。这也是有道理的,因为当音频和视频基于相同的文本时,它们的相关性更高,因此学习基于文本的音频和基于文本的视频表现更好。