本周我的主讲主要是针对基于知识图谱的多跳问答任务从而设计的使用知识图谱任务作为预训练任务训练一个大规模语言模型从而生成答案。主讲从五个方面介绍这篇论文,首先是介绍一下这篇文章的作者信息以及相关知识的介绍。

可以看出作者一直研究关于知识表示学习与多跳问答相互结合从而得到答案的方法,其中主要的思想在于首先学习知识图偶中每一实体及关系的表示,并利用知识图谱补全技术的思想,将问句中的主题实体看作三元组中的头实体,问题表示作为关系,利用补全技术中的得分函数去计算所有其他实体与主题实体和问句的相似度分数从而选择分数最高的实体作为最终的问句答案。如该作者于2020年在ACL发表的文章就是上述思路所示。
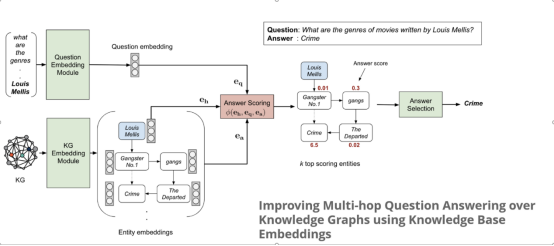
本篇文章不同的是,直接利用现在非常火的Seq2Seq生成式思路来进行答案的生成从而能够更进一步的打开问句复杂程度以及实体数量的限制并在知识图谱不全的情况下利用知识图谱补全这个任务作为预训练任务补全知识图谱推理出那些不曾出现的实体关系。
首先介绍一下问答以及补全任务的目标:在已知一个知识图谱以及全部实体E全部关系R以及由头实体尾实体关系组成的(s,p,o)三元组之后,问答任务的目的是通过在知识图谱内进行推理从而从问句中的主题实体出发找到答案实体的过程。而知识图谱补全任务,即链路预测任务,其主要的目标在于已知头尾实体预测其中的关系或已知头尾实体中的一个及关系边从而预测另一个与之相关的关系的过程,如下图所示。


为了同时解决上述的两个任务,作者构建了KGT5这个模型,满足模型的通用性,质量,简单及多功能性四个指标并取得了非常好的性能。
作者比较了以往做KGC以及KGQA两个任务的众多模型并克服了其他模型面临的困难与缺点并进行改进。
 最后取得了如下的贡献:
最后取得了如下的贡献:

传统的KGE以及KGQA的方法主要分为以下的几个方面其缺点也随之展现出来:


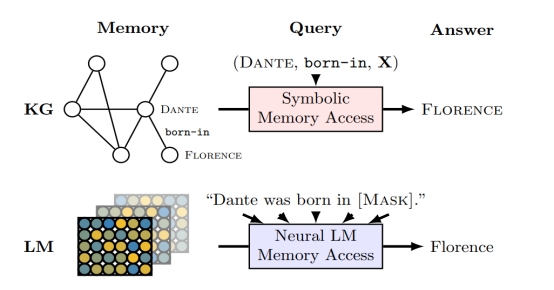
作者提出的模型则是利用预训练语言模型作为知识库的思路:关系型知识库,本身是来源于自然语言的,它的抽取离不开一系列NLP任务。即:抽取实体,实体对齐,抽取关系等一连串NLP工作才能得到一个实体关系的知识库。这个过程依赖于知识的表示具有特定的特征,人类的主动标注,还很容易产生错误,错误会被带入到下一轮的任务中去。
既然知识是通过一系列 NLP task 的 pipeline 抽取出来的,何不直接从自然语言中训练一个编码了这些关系型知识的语言模型出来。
对预训练好的T5模型用QA任务中的问题-答案对进行微调,由于没有上下文或者额外语料的信息补充,模型需要利用预训练时所学到的知识来完成任务
在微调过程中模型需要学习如何挖掘之前预训练获得的知识并加以利用,表明预训练语言模型不仅存储了大量的知识,并且可以将这些知识迁移到下游任务中。
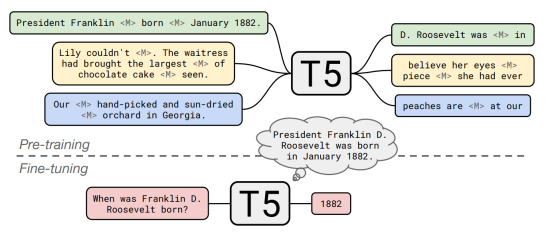
为此,作者使用KGC任务作为预训练任务,具体在训练阶段与推理阶段如下所示:
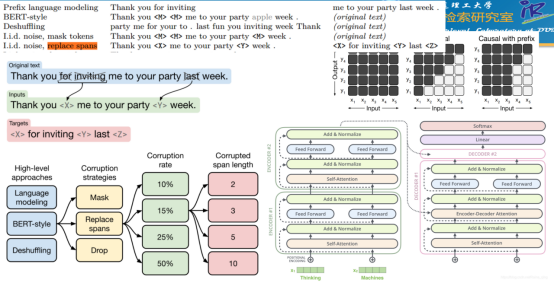
利用T5的模型结构:Transformer的Encoder-Decoder的设计思路,以打乱后的句子或者是Span-Mask掉后的句子作为输入,生成还原后的句子或Span从而作为训练目标。
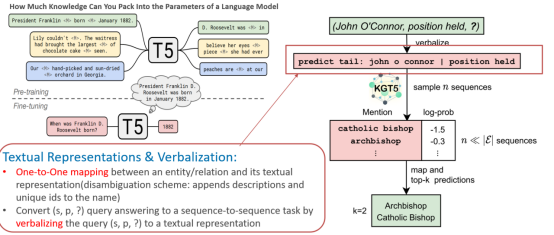
预训练将补全任务作为一个序列化任务,输入为predict tail: s| p and predict head: p| o的形式,从而让KGT5预测其生成结果作为预测实体的答案,其中引入Teacher Forcing的Trick;在预测阶段则选取每次预测分数最高的Token一步一步生成预测的实体,并使用前缀树来控制预测出的结果能够组成已知实体。

针对KGQA任务则作为下游的微调任务,同样输入作为延续与训练任务的模式设计为(predict answer:),同时为了保证微调过程中满足预训练的训练模式并且防止训练过拟合,采用(predict answer:) or (predict head:) or (predict tail:)预测模式混合的方法来进行预测。

以下是实验结果以及结论部分:
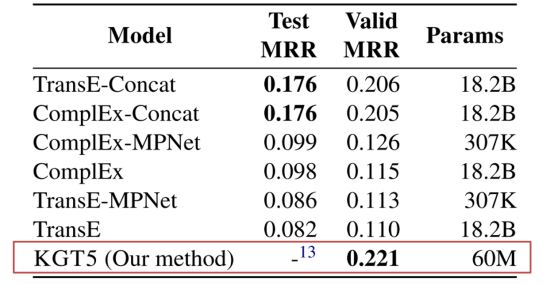


可以看出在大规模知识图谱中进行补全任务的效果是非常显著的但是针对小规模的知识图谱就不是特别理想了。但是作者在进行了集成Complex的方法之后也能达到较为理想的综合结果。
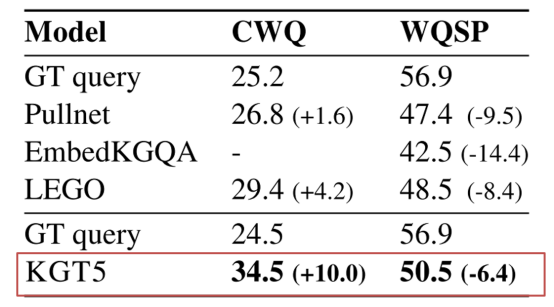
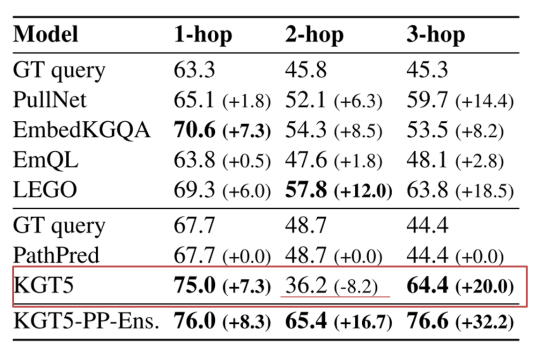
在针对KGQA任务时,由于其知识图谱随机稀疏化的影响,其没有办法进行横向效果对比,因此将其与GT-Query进行了纵向对比来体现了模型的效果。
同时由于MetaQA在两跳问答推理上效果下降的问题,其设计了基于远程监督思想的先验路径映射的方法来保证模型预测的效果。

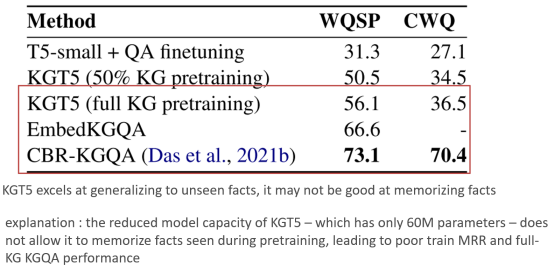
最后也指出了模型的一个性能上的弊端:也就是由于其参数较少因此并不能较好的获取记忆能力,从而导致在完整的知识图谱上效果并不理想。