1. 引言
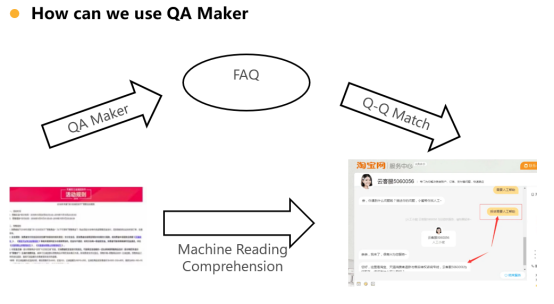
图1 QA对的用途
本文发表于WWW2021,题目为OneStop QAMaker: Extract Question-Answer Pairs from Text in a One-Stop Apprach。
如果用户遇到问题,大部分业内工作走的都是一个FAQ的链路,即拿这个用户的问题跟后台去匹配一个QA pair也就是问答对,然后进行一个qq匹配。然后拿到最相关的这样的Question和对应的answer返还给用户。另外一个途径就是直接拿用户的问题对这个文档文档进行查找,然后找到确定的这个答案片段,这也就是抽取式问答或者机器阅读理解的任务。其中,最常见的还是FAQ这条路,最依赖的也就是QQ MATCH 的准确度。但是部署时,需要一些基础建设。就是需要提前在这个知识库里配好一些问答对的片段。目前业内研究的重点是思考怎么将QA自动化产生做的又好又准确,而且尽量成本尽可能的降低。
以pipeline方式从文档中抽取问答对的方法有两个弊端:首先是问题生成和答案抽取过程之间没有显式关联,即问题生成模型和答案抽取模型在训练过程中是独立的,这导致提取的问答对不兼容。其次是,基于pipeline的方法由于涉及至少两个模型,在工业应用中训练和部署麻烦且耗时,且沿pipeline会有累积误差。

图2 D2Q2A和D2A2Q存在的问题
如上图所示,pipeline方法会导致一些问题呢。第一个问题就是非兼容问题,即第一阶段产生问题之后,再用这个问题去抽答案。这两个步骤其实是完全隔离开的,或者先抽取这个答案片段,然后再找这个问题,这两步也是完全隔离开的。因此,这种隔离开会导致两种后果,第一个后果就是可能产生的问题,这个文档解决不了。我们看上面这个例子,文档是说三角洲的西部被东部的一条现代化的河道所分割,然后模型生成出来的问题是这个三角洲看起来像什么。这在文档里是找不到答案的。还有一点是有可能预测的答案的这个片段太细节了,这个问题非常普遍,先找出来的答案片段很多情况下是一些助动词,或者一些介词,这些词也很难对它们进行提问,做问题生成的时候效果比较差。在下面这个案例中,法国王室是拒绝非天主教徒定居在新法兰西,这解释了殖民地人口增长速度比英国殖民地缓慢的原因。这里的may help to explain模型无法提问。以上是一个非常大的动机,也就是产生的这个问题跟答案是非兼容的。
人类标注者在从文档中抽取问答对时会考虑兼容性及QA对的整体质量。受此启发,论文将问题生成和答案抽取整合到一个统一架构中来提升问答对的兼容性。OneStop模型对目标概率直接优化,其问题生成和答案抽取模块相互协作:答案抽取任务使问题生成模块生成更加可以回答的问题,因为根据不可回答的问题抽取答案是困难的;问题生成任务可增强答案抽取模块的表现,因此答案抽取模型会对易提问点给予更多关注。
此外,将问题生成模型和答案抽取模型统一在一个单一模型中,使OneStop比现存的至少有两个模型的pipeline方法轻量很多。论文贡献:1.提出了一个统一的架构,使答案抽取模块和问题生成模块可以相互促进;2.OneStop是第一个以一站式方式生成兼容问答对的基于transformer的模型:3. OneStop可以很容易地以现有预训练语言模型为基础构建,相比于pipeline方法在工业场景下训练和部署更加高效;4.在三个数据集上做了充分的实验,在问题生成、问答对生成、模型效率方面对模型进行了评估。
2. 相关工作
目前大多方法使用pipeline的方式实现。
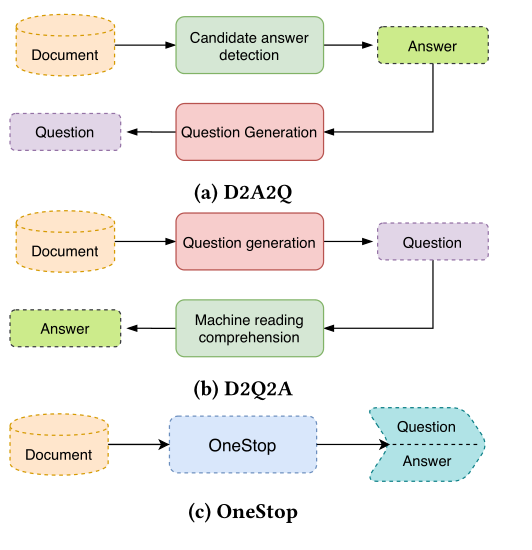
图3 pipeline 和onestop方法对比
可以用公式描述为
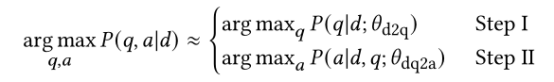
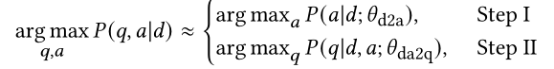
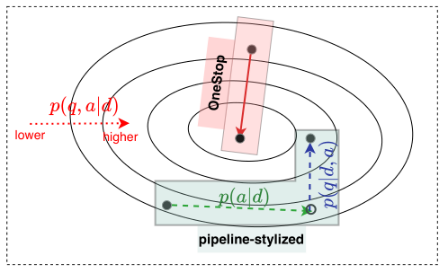
图4 概率图
从概率图上看pipeline在执行第一个任务时可能无法找到最优点,会影响第二个任务的结果。而一站式方法可能更好地找到全局最优解。
3. 模型
2.1任务定义
模型架构可以表示为:
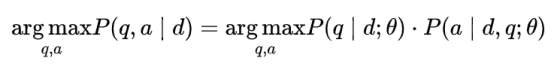
其中θ为模型参数,被问题生成模块和答案抽取模块共享,因此两者可互相影响。
3.2 OneStop模型架构
模型采用基于transformer的seq2seq架构实现,论文中使用BART,由双向编码器和自回归解码器构成。编码器输入文档,解码器生成问题,答案开始和结束位置的预测基于编码器输出与解码器结尾输出。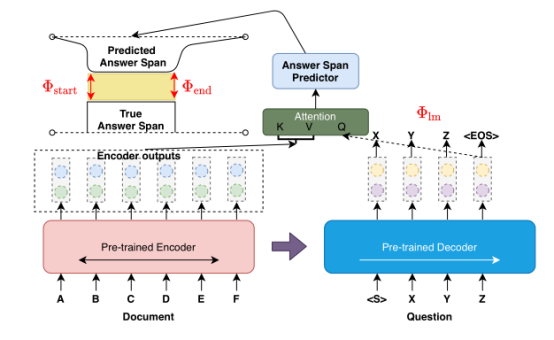
图2 OneStop模型
问题生成采用交叉熵损失: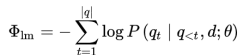
文档中每个token作开始和结束的概率预测公式为:
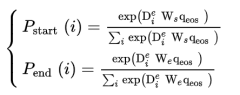
答案抽取交叉熵损失表示为:
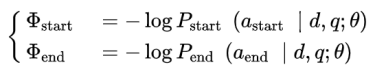
因此模型训练目标可表示为:
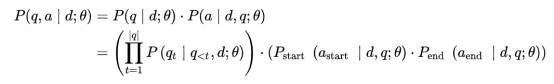
其负对数似然表示为:
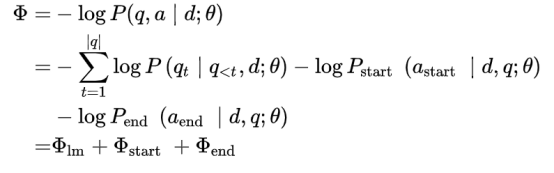
最终模型损失定义为:
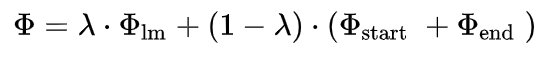
3.3 模型算法
如算法1所示,直接训练的话模型不太好收敛。因此先分别对模型进行预训练。

4. 实验
采用数据集为SQuAD、NewsQA、DuReader。
数据集处理:答案需是文档片段,过滤掉DuReader中的部分数据;一篇文档对应一个QA对,对数据集中的长文档进行拆分。
问题生成实验结果如下:

比较BART-QG可发现答案抽取可促进问题生成模型的性能。
问答对生成的实验结果采用人工评价,结果如下:
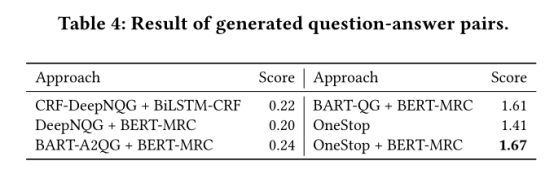
OneStop中的答案抽取模块性能不及BERT,原因是BERT层数更多,具备更强的表示能力。与BART-QG+BERT-MRC模型结果相比,可知OneStop模型中答案抽取模块对生成QA对质量有提升作用。
Onestop方式因为一站式完成两个任务,因此模型的参数更少,如下图所示:
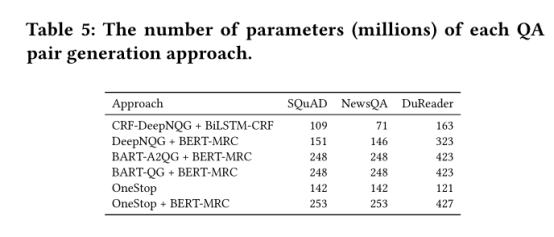
仅包含一个模型,参数量较小,在训练和部署时均较高效。且pipeline模型在线上应用时需额外的人工劳动,如D2A2Q中答案抽取模型可能不选择或选择一个以上的答案,则需设计较好的规则从候选中选择答案用于问题生成。
最后,本文给出案例分析,表明OneStop可以生成更好的问答对:

5. 总结
基于pipeline的QA对生成方法存在不兼容、效率低、需人工参与等问题。本文提出一站式模型,在三个数据集上以更高效的方式实现了问题生成和QA对生成的SOTA。