1. 引言
原文为《Multi-Relational Graph based Heterogeneous Multi-Task Learning in Community Question Answering》。
社区问答系统(CQA)帮助数百万的用户在网络上获取问题的解决方案或者是分享他们的专业知识。CQA中许多问题已经被进行了大量的研究,比如重复问题检测,答案推荐等。由于CQA是一个关联紧密的平台,这些任务或多或少都存在相关的关联性。比如,重复问题检测和答案推荐对互相可能会有帮助,因为这两个任务都聚焦于语义匹配。因此,在CQA平台中研究多任务学习(MTL)可能会提高所有任务的表现。
但是,大多数现存的MTL框架只考虑相似的任务,比如分类和回归任务,或者假设特征类型相同。考虑到CQA中任务的异质性(任务之间的关联并不大),当前存在的MTL框架并不能有效地与CQA任务结合。总的来说,当前的MTL框架存在两个主要的问题。(1)把异质的CQA数据中的特征使用一个统一的框架来表示是非常必要的,即在同一个语义空间表示所有的特征。(2)不同任务的标签之间存在一定的关联性,当前的MTL框架并没有利用到不同任务之间标签的关联性。
为了解决上述的问题,本文提出算了一个HMTGIN框架,使用多关系的图来构建整个CQA结构,用GIN算法更新节点表示,并且设计了两种跨任务的限制来关联不同任务中的标签。
2. 模型
2.1文中涉及到的任务
文中考虑了五个社区问答系统中的任务,五个任务可以分成三个任务类型。
首先是链路预测,包含两个任务。
(1) 标签预测:给定一个Q-TAG对,判断这两个节点之间是否存在边。
(2) 重复问题检测:给定一个Q-Q对,判断这两个节点之间是否存在边。
其次是排序任务,包含一个答案排序任务:给定当前问题和对应回答列表Q-A list,对列表中的回答进行排序。
最后是分类任务,包含两个任务。
(1) 回答得分分类:以答案获取的投票数为基准,把答案分成[0-3]中的整数。
(2) 用户声誉分类:以用户的专业度为基准,把用户节点分成[0-4]中的整数。
2.2 HMTGIN模型架构
如图1所示,DukeNet包含三个部分:(1)图构建;(2) 子任务学习; (3) 限制设计。
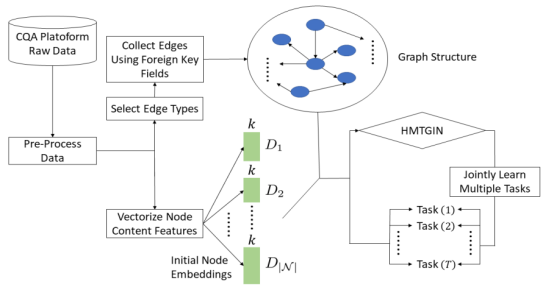
图1 HMTGIN模型
2.3 图构建
如图2所示,文中的图包含四类节点:问题,答案,用户,标记(TAG)。这些节点包含了各种类型的边,从而全面的对复杂异质的CQA社区进行了表示。

图2 图构建
对于不同类型的节点,文中采取了不一样的初始化策略。对于问题节点,根据问题节点的相关属性:标题,问题内容,创建时间等进行初始化。对于答案节点:使用文本还有创建时间等。对于用户节点:使用用户等级等属性进行初始化。对于文本类型的属性,文中采用GLOVE词向量的平均,对于离散的数字,则使用one-hot形式编码。最后采用SVD降维方式将所有的节点表示映射到相同的维度。
文中采用如下公式对节点表示进行更新:
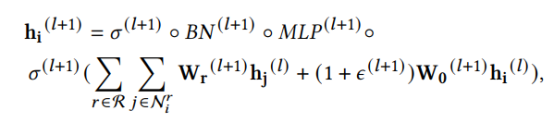
其中,BN表示batch正则,MLP表示多层感知机,W则是需要训练的参数。值得一提的是,对于不同的邻居节点类型,W的权重是不一样的。
2.4 子任务学习
以下会展示对于不同的任务类型,输出层与损失函数如何构建。
2.4.1 链路预测
给定节点对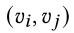 ,计算两个节点之间的相似度得分
,计算两个节点之间的相似度得分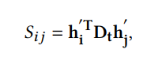 ,最后计算损失函数:
,最后计算损失函数:

2.4.2 答案排序
给定问题和对应的回答列表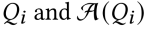 ,计算每个回答的得分
,计算每个回答的得分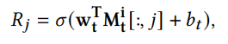 ,最后计算相关的损失:
,最后计算相关的损失:
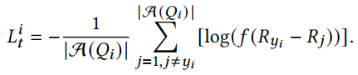
2.4.3 分类任务
给定回答或者用户节点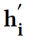 ,映射节点
,映射节点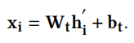 ,计算损失:
,计算损失:
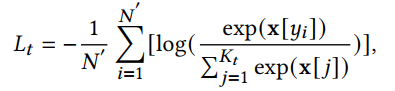
2.5 限制设计
文中根据如下两点假设来对标签设计限制:
(1)如果答案A的得分比B更高,那它更可能被接收。
(2)如果用户A比用户B的声誉更高,那么他提供的答案更可能被接收。
文中根据上述两点假设做了两个限制,对于第一个限制,使用如下的步骤:1)获取问题和回答列表的表示;
2)计算每个回答的分类值,并取其中最高的若干个回答;
3)计算每一个选中的答案的排序得分,形成惩罚项:
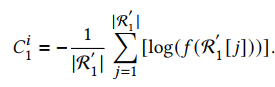
对于第二个限制,采取的步骤如下:
1)获取问题和回答列表中的用户的表示;
2)计算每个用户的分类值,并取其中最高的若干个回答;
3)计算每一个选中的用户对应回答的排序得分,形成惩罚项:
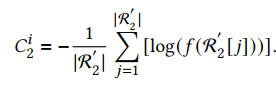
具体过程如下图所示:
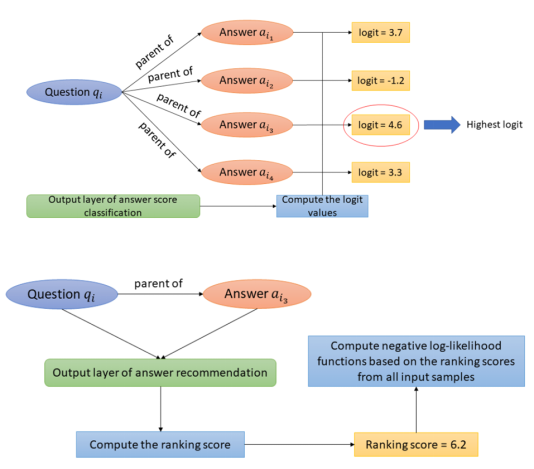
图4 限制1
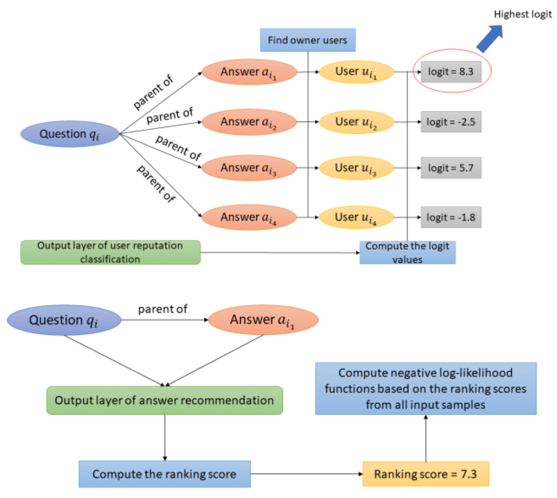
图5 限制2
2.6 最终的损失
如图6所示,文中最后把所有的损失按照权重进行相加。
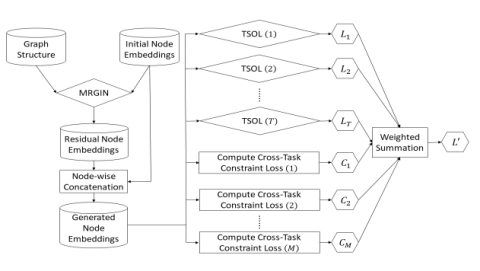
图6 损失构成
3. 实验
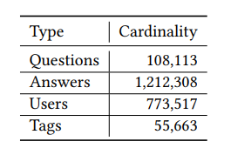
采用数据集为Stack Overflow,数据结构如表1所示:
表1 数据结构
文中采用的对比实验如下表所示:
表2 对比实验设计
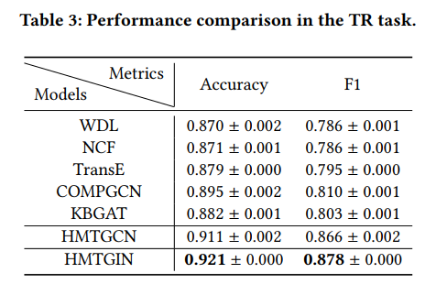
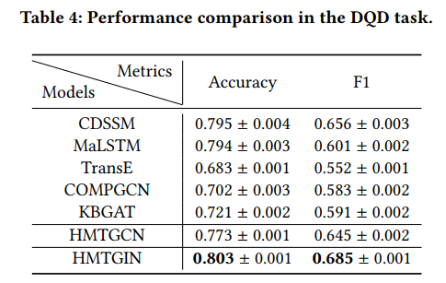
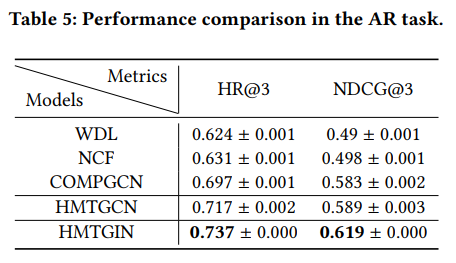
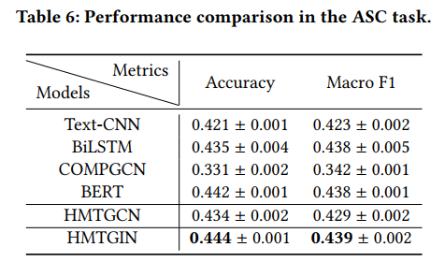
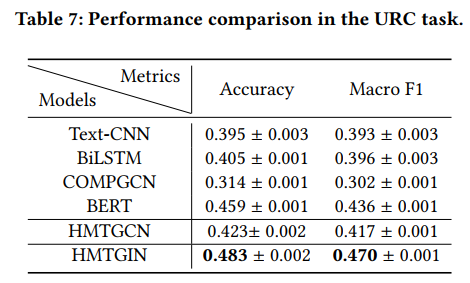
实验结果如下表所示:
最后,本文给出了消融实验的相关结果,如下图所示:
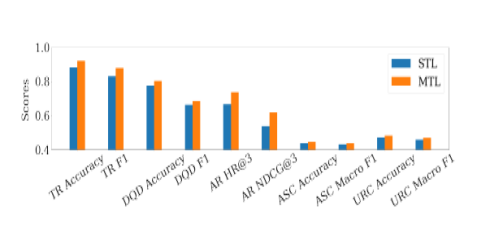
图7 单任务学习与多任务学习效果
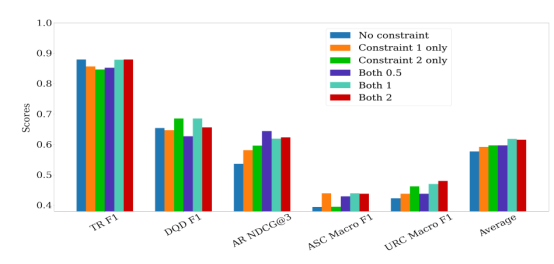
图8 跨任务限制的作用
图9 MLP层数的影响
4. 总结
本文是第一个采用多关系图来研究CQA中的多任务学习的。本文构建了一个上百万节点的数据集并且进行了开源,文中的实验结果表明增强任务之间的关联限制确实可以明显提升多任务学习的效果。未来工作可以探索不同多任务学习中的相关限制。