本文发表于ACL2020,同时也是该年最佳论文。
一、简介
训练NLP模型的主要目标之一是泛化,虽然Accuracy是评价泛化的主要方法,但它往往高估了NLP模型的性能,用于评估模型的替代方法要么侧重于单个任务,要么侧重于特定的行为,benchmark的准确性不足以评估NLP模型。
除此之外许多额外的评估方法已经被提出来了,例如评估对噪声或对抗性变化的鲁棒性、公平性、逻辑一致性、可解释、诊断数据集和交互式错误分析。然而,这些方法要么侧重于单个任务,如问答或自然语言推理,要么侧重于一些能力(如鲁棒性),因此没有提供关于如何评估模型的全面指导。
因此在这这篇论文中,作者提出了CheckList(检查表),一种新的评估方法和配套工具,用于NLP模型的综合行为测试。
二、CHECKLIST
软件工程研究提出了测试复杂软件系统的各种范式和工具。特别是“行为测试”(黑盒测试)是指在不了解内部结构的情况下,通过验证输入输出行为来测试系统的不同能力。虽然有明显的相似之处,但软件工程的许多见解还没有应用到NLP模型中。
作者借鉴软件工程中行为测试的原理提出了CheckList:一种和模型、任务都无关的测试方法,它使用三种不同的测试类型来测试模型的各个功能。
作者用三个任务的测试来说明检查表的效用,识别商业和SOTA模型中的关键错误。在一项用户研究中,一个负责商业情绪分析模型的团队在一个经过广泛测试的模型中发现了新的、可操作的bug。在另一个用户研究中,使用CheckList的NLP实践者创建了两倍多的测试,发现的bug几乎是没有检查表的用户的三倍。

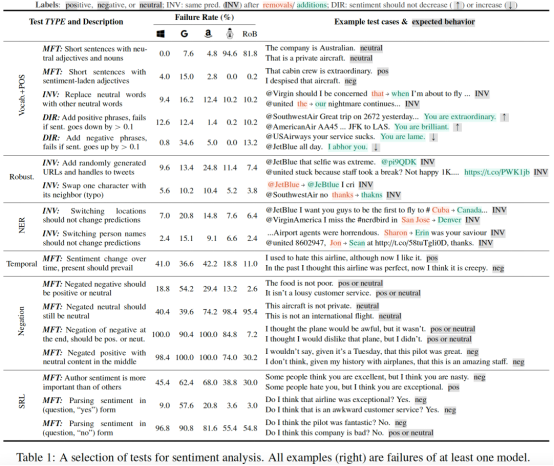
CheckList包括一个通用语言能力和测试类型的矩阵,有助于全面的测试构思,以及一个快速生成大量不同测试用例的软件工具。从概念上讲,用户通过填写矩阵中的单元格来“检查”模型(图1),每个单元格可能包含多个测试。CheckList应用了“测试与实现脱钩”的行为测试原则,即将模型视为一个黑盒,允许对不同数据上训练的不同模型进行比较,或者对不允许访问训练数据或模型结构的第三方模型进行比较。
CheckList通过提供适用于大多数任务的语言能力列表,指导用户测试什么。CheckList引入了不同的测试类型,比如在某些干扰下的预测不变性,或者一组“健全性检查”的性能。
虽然测试单个组件是软件工程中的常见实践,但现代NLP模型很少一次只构建一个组件。相反,CheckList鼓励用户考虑如何在手头的任务上表现出不同的自然语言能力,并创建测试来评估这些能力的模型。例如,词汇+POS能力取决于一个模型是否具有必要的词汇,以及它是否能够恰当地处理具有不同词性的单词对任务的影响。对于情绪,我们可能需要检查模型是否能够识别带有积极、消极或中性情绪的单词,方法是验证它在“这是一次很好的飞行”等示例上的行为。
基于此,作者建议用户至少考虑以下性能(capabilities):
1. 词汇+POS(任务的重要单词或单词类型)
2. Taxonomy(同义词、反义词等)
3. 健壮性(对拼写错误、无关更改等)
4. NER(正确理解命名实体)
5. 公平性
6. 时态(理解事件顺序)
7. 否定
8. 共指(Coreference),
9. 语义角色标记(理解诸如agent、object等角色)
10. 逻辑(处理对称性、一致性和连词的能力)。
通过以上,CheckList实现包括多个抽象,帮助用户轻松生成大量测试用例,例如模板、词典、通用扰动、可视化和上下文感知建议。然而此功能列表并非详尽无遗,而是用户的一个起点,用户还应提供特定于其任务或域的附加功能。
作者提示用户使用三种不同的测试类型来评估每个功能:最小功能测试、不变性和定向期望测试(矩阵中的列)。
1)最小功能测试(MFT):它是受软件工程中单元测试的启发的一组简单的示例(和标签)的集合,用于检查功能中的行为。MFT类似于创建小而集中的测试数据集,尤其适用于在模型使用快捷方式处理复杂输入而不实际掌握功能的情况下进行检测。

2)不变性测试(INV):当对输入应用保留标签的扰动并期望模型预测保持不变时。不同的功能需要不同的扰动函数,例如,更改NER情感功能的位置名称,或者引入输入错误来测试健壮性能力。
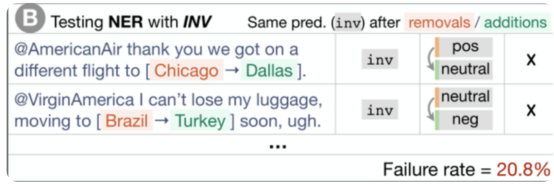
3)定向期望测试(DIR):与不变性测试类似,只是标签会以某种方式发生变化。例如,我们预计,如果我们在针对某家航空公司的推文末尾添加“You are lame.”,情绪不会变得更积极。
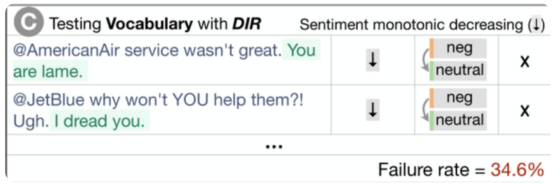
三、测试用例生成
用户可以从头开始创建测试用例,也可以通过扰动现有的数据集来创建测试用例。从头开始可以更容易地为原始数据集中可能未充分表示或混淆的特定现象创建少量高质量测试用例。然而,从头开始编写需要大量的创造力和努力,这通常会导致测试覆盖率低或者生成成本高、耗时长。扰动函数很难编写,但同时生成许多测试用例。为了支持这两种情况,作者提供了各种抽象,从零开始扩展测试创建,并使扰动更容易处理。
四、实验
1.商业模型测试
作者通过付费API 检查了以下商业情绪分析模型:微软的文本分析、谷歌云的自然语言和亚马逊的Constract。我们还检查了在SST-23(acc:92.7%和94.8%)和QQP数据集(acc:91.1%和91.3%)上微调的BERT base和RoBERTa base。对于MC,作者使用了一个经过预训练的大BERT 微调阵容,达到93.2 F1。
2.重复问题检测
测试了 BERT-base 和 RoBERTa-base(在 QQP 数据集上微调,acc 分别达到 91.1% 和 91.3%)。在部分任务(如 Negation)上,所有模型的表现都很糟糕。

3.机器阅读理解
测试了基于 SQuAD 的 BERT-large,F1 值达到 93.2%。

四.用户研究
作者进行了一项用户研究,以在一个更可控的环境中进一步评估检查表的不同子集,并验证即使是没有任务经验的用户也能获得洞察并发现模型中的错误。
尽管用户在使用CheckList时不得不解析更多的指令和学习新的工具,但他们同时为模型创建了更多的测试。
在实验结束时,作者要求用户评估他们在每个特定测试中观察到的失败的严重程度,研究结果令人鼓舞:有了检查表的子集,没有经验的用户能够在2小时内发现SOTA模型中的重大缺陷。此外,当被要求对检查表的不同方面进行评分时(1-5分),用户表示,测试环节有助于他们进一步了解模型,功能帮助他们更彻底地测试模型,模板也是如此。
评估特定语言能力的一种方法是创建挑战性数据集。我们的目标不是让检查表取代挑战或基准数据集,而是对它们进行补充。CheckList保留了挑战集的许多优点,同时也减轻了它们的缺点:用模板从头开始编写示例提供了系统控制,而基于扰动的INV和DIR测试允许在未标记的自然发生的数据中测试行为。
最后用户研究表明,CheckList可以轻松有效地用于各种任务:用户在一天内创建了一个完整的测试套件进行情绪分析,两个小时内创建了的MFTs,这两个都揭示了之前未知的严重错误。
五.总结
传统的基于准确率的评估并不足以完全评估NLP模型的真实表现,本文借鉴软件工程中行为测试的思想,提出了CheckList,一种模型无关和任务无关的测试方法,其通过三种不同的「测试类型」测试模型的各种「语言学能力」。为了说明其有用性,文章在三种不同的任务上测试了多个模型,暴露了大量传统的评估方法难以发现的问题。用户评估表明,CheckList非常易于学习和使用,对各类用户都是有帮助的。此外,CheckList的开源实现所提供的抽象方法和工具能够更加轻松地创造测试用例,进行面向各种任务的测试。