跨多图像融合注意力实现多模态事件检测
Focusing Attention across Multiple Images for Multimodal Event Detection
王琰
多模态社会事件检测对社会事件具有全面和互补的认识,对公共安全和行政具有重要意义,近年来引起了广泛的研究关注。现有的工作大多集中在多模态信息的融合上,特别是单个图像和文本的融合。这种单一的图像-文本对处理打破了同一帖子的图像之间的相关性,可能会影响事件检测的准确性。在这项工作中,我们建议将注意力集中在多个图像上进行多模态事件检测,这对于具有短文本和多幅图像的推文也更合理。为此,我们设计了一种新的多图像聚焦网络(MIFN),将文本内容与多个图像中的视觉方面连接起来。我们的MIFN由特征提取器、多焦网络和事件分类器组成。多焦网络对所有图像实现焦点关注,并将最相关的区域与文本作为多模态表示。事件分类器最终基于多模态表示来预测社会事件类。
背景
近几年来,随着移动互联网的普及和数字设备的发展,如智能手机、社交媒体也越来越受欢迎,并取得了巨大的进步。得益于便利和传播,人们倾向于在社交媒体上记录和发布日常生活和其他信息,包括文本、表情符号、图像、视频等。

图1:多模态社会数据的一个例子
受文本内容的长度和处理技术的限制,早期的社会事件检测侧重于单模态数据。由于图像比短文本传达更详细的方面,视觉纹理和语义学习被提出从视觉数据中提取事件线索,例如,图像和视频,以利用更详细的信息。然而,社交媒体上的帖子通常由文本、图像、音频和其他元数据组成,如图1所示。只分析文本或图像,几乎不能充分利用多模态信息,而且可能无法捕捉到有效的信息。研究人员进一步从多模态数据中挖掘语义线索,主要从视觉和语言数据,用于社会事件检测。
因此,为了解决上述问题,提出了两个解决方案:
(1)提出了一种用于多模态社会事件检测的多图像聚焦网络。同时整合社交媒体帖子的多幅图像和文本内容,以实现多模态理解和检测事件。
(2)设计了一个多焦网络来聚焦多个图像,这使得模型可以融合来自不同图像的文本和视觉。
模型
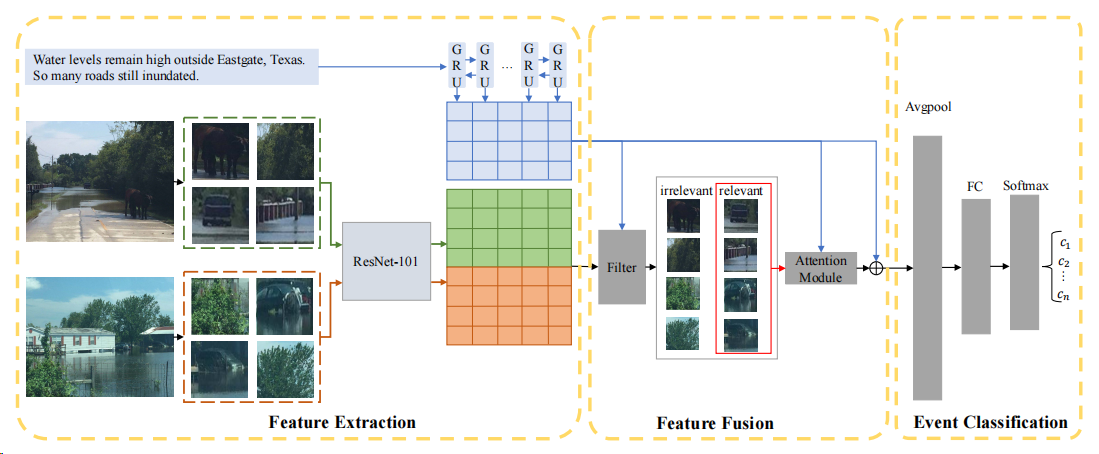
图2:MIFN的框架
如图2所示,给定一条推特,由一条文本和多条图像组成,我们提取文本特征图和视觉特征图。对于每个单词,我们在单词嵌入的基础上进一步过滤出不相关的图像区域,并将所嵌入的单词与相关的图像区域进行融合。最终的tweet嵌入由相应的纹理嵌入和相应的视觉嵌入组成,输入事件分类器。
特征抽取:
对于图像特征,假设一条多模态的推文包含了文本句子s的主要内容和一组图像V,由于文本和图像都与同一事件相关,s描述的对象可能在V={v_i},i=1,...,N中的多个图像之间分布,其中v_i表示第i个图像。我们使用ResNet-101预训练好的Faster R-CNN目标检测模型来抽取图像特征,检测相关目标。对于给定的图像v_i,我们会的到M个目标区域,表示为{v_ij},j=1,...,M, v_ij是第j个目标区域。最终图像集合V表示为V。
对于文本特征,使用Bi-GRU来编码语义信息,即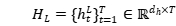 和
和 ,其中
,其中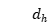 是隐藏层维度,T是文本s的长度。最终通过融合两个方向的信息,得到最终的文本语义表示:
是隐藏层维度,T是文本s的长度。最终通过融合两个方向的信息,得到最终的文本语义表示:
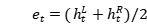 (1)
(1)
Multi-focal Network:
以往的多模态事件检测工作主要集中在文本和单个图像对上,但忽略了文本和多个图像的元组在现实场景中更常见,如图1所示。由于社交媒体上允许使用有限的文字,用户可以分享多张图片作为文本所描述的补充信息。然而,我们发现,本文所描述的对象所对应的图像区域,可能不会集中在单个图像上。为了更好地融合文本特征和视觉特征,我们选择了图像的所有相关区域。最终的推文embedding由文本embedding和相关区域的可视化embedding组成。
具体来说,我们首先将s中的单词的相关得分矩阵R初始化到V中的所有区域:
 (2)
(2)
对于每个单词,我们假设相关区域获得的相关得分高于不相关区域。因此,我们过滤掉了相关得分低于所有区域的平均得分的区域。滤波的功能可以表述为:
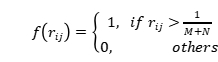 (3)
(3)
最后,使用公式(4)重新分配其余相关区域的权重:
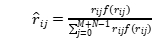 (4)
(4)
融合后的特征表示为:
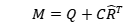 (5)
(5)
事件分类:
为了保留M的所有信息,使用平均池来获得最终的tweet嵌入:
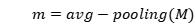 (6)
(6)
最终得到事件类别概率:
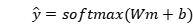 (7)
(7)
数据集及实验结果
数据集
CrisisMMD是一个自然灾害事件数据集,在7个自然灾害中收集,并使用文本-图像对注释了三个任务:(1)Informative vs. Not Informative,(2)Humanitarian Categories,(3)Damage Severity。在这些任务中,任务1是为了确定该推文是否对人道主义援助目的有用,而任务3(损害严重程度)只适用于图像,因此只有任务2,即人道主义类别,适合于我们的多模式事件检测。此外,任务2是关于不同自然灾害期间的人道主义事件,包括飓风、野火、地震和洪水。为了避免不同的灾害对图像背景和推文语义的影响,我们设计了另一个实验任务,检测特定灾害的人道主义事件,飓风有更多的样本。具体数据集情况如表1和表2所示:
表1:任务2(Humanitarian Categories)的数据统计数据
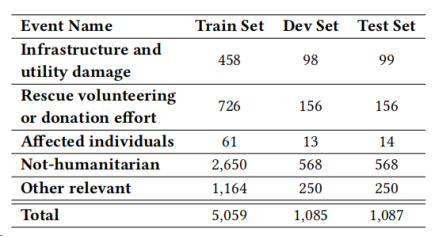
表2:飓风灾害的数据统计
实验结果
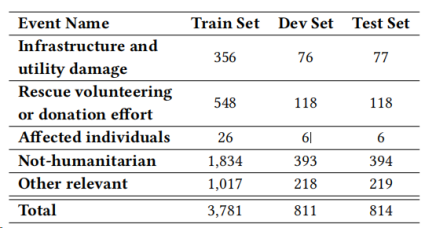
总体实验结果,如表3和表4所示
表3:任务2的实验结果
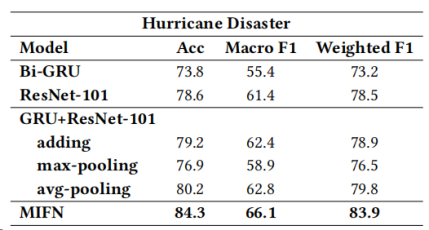
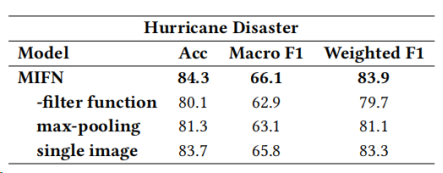
表4:飓风灾害实验结果
消融实验,为了研究文本和视觉信息的有效性,我们设计了MIFN的两种变体,-text和-image。如图3所示,如果没有这两种信息中的任何一种,性能都会下降。
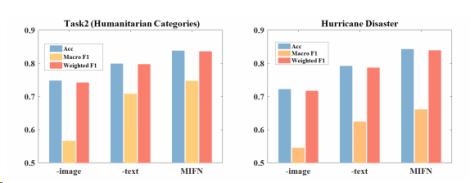
图3:提出的MIFN的不同版本在人道主义事件检测上的性能。-image/-text表示没有视觉信息/文本信息的MIFN变体。
此外,还设计了另外三种变体来分析多重图像、滤波函数和池化方法的效果。结果如表5和表6所示。
表5:任务2上MIFN的消融分析
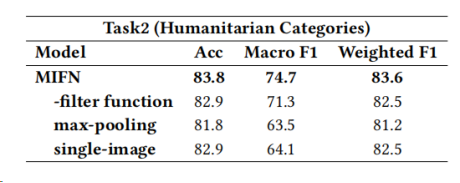
表6:飓风灾害上MIFN的消融分析
结论
在本文中,作者研究了在一个更真实的场景下的多模态事件检测。此外,还提出了一种多图像聚焦网络(MIFN)来融合文本特征和视觉特征。对于多幅图像,利用预先训练的Faster R-CNN来获取每个图像的图像区域并提取其特征。与大多数多模态事件检测的融合方法不同,在融合多模态信息之前,过滤掉了对给定单词的无关图像区域。为了探索融合多幅图像的有效性和所提出的滤波器函数,作者设计了两种不同的MIFN。实验结果表明,MIFN优于这两种变体,说明了利用多幅图像扩展文本信息,并在多模态融合前过滤掉不相关信息的优势。