Raise a Child in Large Language Model:
Towards Effective and Generalizable Fine-tuning
本篇论文发表于2021年,本文作者来自北京大学和阿里巴巴集团。
1 引言
预训练语言模型最近对 NLP 领域产生了显著影响。 预训练和微调已经成为 NLP 的新范式,主导着各种各样的任务。尽管取得了巨大的成功,但如何将这种具有数百万到数十亿参数的大规模预训练语言模型适应各种场景,尤其是在训练数据有限的情况下,仍然具有挑战性。
在迁移学习中,大模型下finetune的过程变成了一个复杂的过程,因为不同的参数对不同任务下的结果的敏感度不同,而且模型规模大导致模型表达能力过强。稍加训练后很容易过拟合,或者破坏预训练所学的内容,使模型失去泛化能力。
针对这个问题,作者提出了这篇论文。 他们的贡献主要如下: 首先,他们提出了 CHILD-TUNING,一种直接但有效的微调技术,它只更新子网络中的参数。 他们探索以无任务和任务驱动的方式检测子网络。 其次,CHILD-TUNING可以有效地将大规模预训练模型适应各种下游场景,从域内到域外,以及跨任务迁移学习。 最后,由于 CHILD-TUNING 与之前的微调方法正交,将 CHILD-TUNING 与它们结合可以进一步提升微调性能。
2 相关工作
在讨论他们的解决方案之前,我们先来看看本文中提到的其他一些优化思路。 首先是权重衰减,这是一种比较简单的方法。 它在损失函数中添加了一个惩罚项,以调节微调模型和预训练模型之间的 L2 距离。这样,可以将参数变化的范围限制在整体上不是特别大。
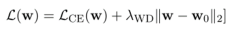
Top-K 是所有方法中最直接的。 Top-K Fine-tuning 只更新前 K 层和分类层,同时冻结所有其他底层。
Mixout 的工作与上述两种方法类似。 它在微调过程中以一定的概率随机用其预训练的权重替换参数,旨在最小化微调模型对预训练权重的偏差。
RecAdam 可以被认为是 权重衰减的高级版本,因为两个不同损失项的系数随着训练的进行而改变。 如下公式展示了新的损失函数,其中 k 和 t0 是控制超参数,t 是当前训练步长。
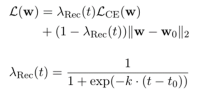
与权重衰减和 RecAdam 不同,R3F 将噪声添加到序列输入嵌入中,并尝试最小化给定原始输入和噪声输入的概率分布之间的对称KL 散度。 R3F的损失函数如下。
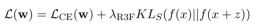
3 方法
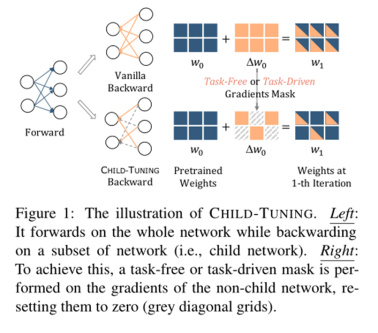
为了更好地使大规模预训练语言模型适应各种下游任务,作者提出了一种简单而有效的微调技术 CHILD-TUNING。 他们首先在后向过程中引入梯度掩码,以达到更新参数子集的目的,同时在前向过程中仍然利用整个大型模型的知识。
普通微调计算损失的梯度,然后将梯度下降应用于所有参数。 、
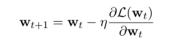
CHILD-TUNING依旧向后计算所有可训练参数的梯度,如普通微调。 然而,关键的区别在于 CHILD-TUNING 在第 t 次迭代时确定了一个子网络 Ct,并且只更新这部分参数。 为了实现这一点,他们首先定义了一个与权重大小相同的 0-1 掩码,然后,他们通过如下公式定义了 CHILD-TUNING 技术。
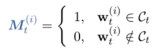
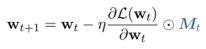
但是如何确定子网络Ct,作者提出了两种方法。 第一个是 CHILDTUNING-F。 CHILDTUNING-F 在第 t 次迭代中生成一个 0-1 掩码 Mt,该掩码从具有概率 pF 的伯努利分布中提取。 换句话说,对于每个模型参数,它都有一定概率在没有梯度更新的情况下被屏蔽。 作者指出 CHILDTUNING-F 改善了梯度的方差,可以看作是优化过程的强正则化。
考虑到下游标记数据,作者提出了另一种方法 CHILDTUNING-D,它检测目标任务最重要的子网络。 他们采用 Fisher 信息估计来为特定下游任务找到高度相关的参数子集。 作者通过以下公式推导出第 i 个参数的 Fisher 信息。
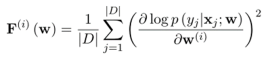
然后根据F(w)对每个参数进行排序,选择最重要的top-����部分进行优化。 由于获取task-driven child network的开销比task-free的开销大,所以他们在fine-tuning开始时简单地推导出CHILDTUNING-D的child network,在后续fine-tuning的过程中保持不变。
4 实验
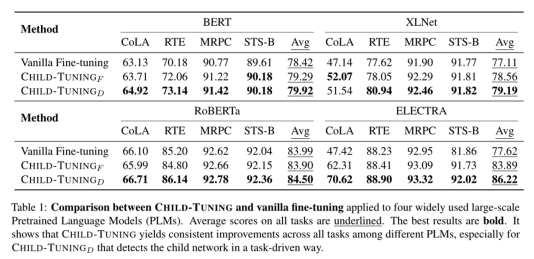
作者进行了非常详细的实验来说明他们的方法的有效性。 一是常规模型效果检验。 作者基于bert、roberta、xlnet和electra这四种模型,在GLUE的多个子任务下对其进行评估,发现ChildTuning优于普通微调方法。
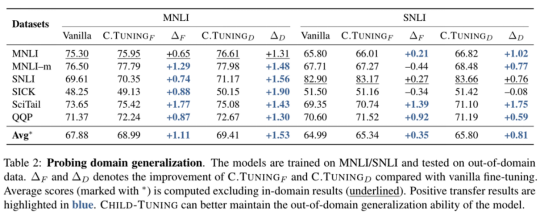
然后,为了衡量各种微调方法的泛化特性,作者从两个方面进行了探索性实验。 第一个是Domain Generalization,他们根据几个自然语言推理任务评估微调模型对域外数据的泛化效果。 这些模型在 MNLI 或 SNLI 上进行训练,并在域外数据上进行测试。 结果表明,CHILD-TUNING 鼓励模型在微调过程中学习更一般的语义特征,而不是训练数据特有的一些表面特征。 因此,微调后的模型可以很好地泛化到不同的数据集。
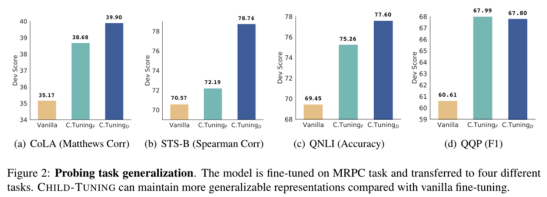
第二个是Task Generalization,作者使用MRPC数据集进行finetune,然后冻结参数,给模型加一个dense layer放到其他任务中训练,然后检验模型的效果。 简单来说,当微调模型转移到另一个任务时,使用 CHILD-TUNING 进行微调可以获得更好的性能,证明CHILD-TUNING 可以保持模型产生的比普通微调更泛化的表示。
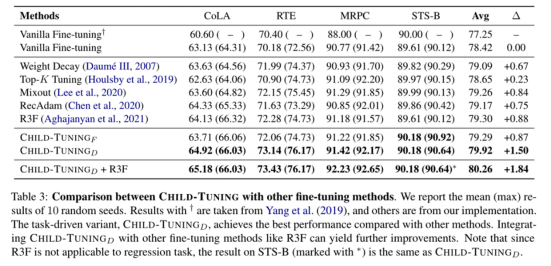
然后,作者将 ChildTuning 与其他微调策略结合起来进行横向比较,结果如下表所示。 从表中我们可以看出,CHILD-TUNING 更有效地使相关语言模型适应各种任务,特别是对于任务驱动的变体 CHILDTUNING-D,而 CHILD-TUNING 的优点是足够灵活,可以与其他方法结合取得进一步的改善。
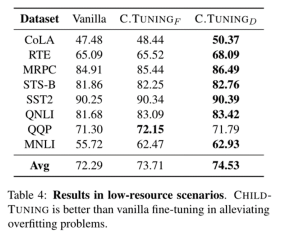
此外,作者通过少样本数据集探索了 CHILD-TUNING 的效果。 为此,他们将 GLUE 中的所有数据集下采样到 1000 个训练示例,并利用它们微调 BERT_large。下表表明,虽然在训练数据处于极端低资源场景时过拟合非常严重,但 CHILD-TUNING 仍然可以有效提高模型性能,尤其是对于 CHILDTUNING-D,因为它可以减小模型的假设空间。
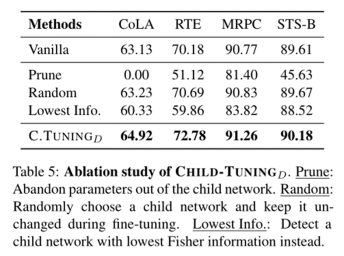
最后,为了说明 CHILDTUNING-D 相比模型剪枝的有效性,作者将所有不属于子网络的参数设置为零,即为下表中的 Prune。 在子网络中,四个任务的平均分数急剧下降,模型甚至在 CoLA 任务上崩溃。 其还表明,除了子网络中的参数外,非子网络中的参数也是必要的,因为它们可以提供在预训练中学到的一般知识。
5 总结
最后,我总结了本文作者的贡献。 首先,为了缓解过拟合问题并提高微调大规模预训练语言模型的泛化能力,作者提出了一种简单而有效的微调技术 CHILD-TUNING。 引入了两个变体 CHILDTUNING-F 和 CHILDTUNING-D,它们分别以无任务和任务驱动的方式检测子网络。 对各种下游任务的大量实验表明,它们都可以在四种不同的预训练语言模型中大幅提升原始微调和先前的工作,同时大大提高微调模型的泛化能力。