对比学习模型在无监督视觉表示学习中取得了巨大的成功,它最大化了同一图像不同视图的特征表示之间的相似性,同时最小化了不同图像视图的特征表示之间的相似性。在文本摘要中,输出摘要是输入文档的较短形式,它们具有相似的含义。论文中,作者提出了一种用于监督抽象文本摘要的对比学习模型,将文档、其黄金摘要及其模型生成的摘要视为相同平均表示的不同视图,并在训练期间最大化它们之间的相似性。
(1)原文标题:Sequence Level Contrastive Learning for Text Summarization.[1]
1. 引言
文档摘要是将较长的文档改写成较短的形式,同时仍保留其重要内容的任务,这需要模型理解整个文档。相关工作中已经探索了许多摘要方法,最流行的方法是抽取式摘要和生成式摘要。抽取式摘要方法生成的摘要通常冗长且冗余,带来不好的阅读体验。因此,作者在本文中专注于生成式摘要。
尽管由于最近引入了大型预训练Transformer,导致生成式模型变得越来越强大,但生成式模型的训练范式仍然没有改变,即最小化模型预测词分布和预测词分布之间的负对数似然。摘要任务的一个重要特性是文档及其摘要应该传达相同的含义,这不是由负对数似然损失明确建模的。
在计算机视觉中,用于无监督图像表示学习的对比学习方法提高了对象检测和图像分割的最新技术水平。其关键思想是最小化同一图像的不同视图(正例)的特征表示之间的距离(或最大化相似性),同时最大化不同图像的视图(负例)的特征表示之间的距离。如前所述,在摘要中,文档及其摘要应传达相同的含义。
本文中,作者将文档、其黄金摘要及其模型生成的摘要视为相同含义表示的不同视图,并且在训练期间,我们最大化它们之间的相似性。为了实现这一点,我们提出了基于对比学习的SeqCo(作为序列级对比学习的简写)。除了黄金摘要,作者还在训练期间使用我们模型动态生成的摘要来增加模型输入的多样性。在实验中,作者发现提出的基于对比学习的模型SeqCo在三个不同的摘要数据集(CNN/DailyMail、New York Times和XSum)上都取得了很好的摘要结果。人类评估还表明,与没有对比目标的对应模型相比,SeqCo获得了更好的忠诚度评级。
2. SeqCo
作者充分描述了用于抽象文本摘要的对比学习模型 SeqCo(作为序列级对比学习的简写)。首先介绍了模型所基于的抽象文本摘要模型(即Seq2Seq模型),然后介绍了SeqCo,使对比学习适应序列到序列的学习设置。
2.1 Sequence Representation
对任务进行如下定义:
(1)两个输入句子 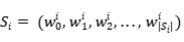 和
和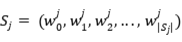
(2)Transformer encoder  和Transformer decoder
和Transformer decoder 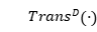
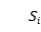 和
和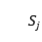 可以是文档
可以是文档 及其黄金摘要
及其黄金摘要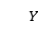 ,或者文档和生成摘要,或者黄金摘要和生成摘要,如图1所示。
,或者文档和生成摘要,或者黄金摘要和生成摘要,如图1所示。

图1 文档、黄金摘要和模型生成摘要之间的相似之处。
在进行相似度计算之前,首先将它们转换为隐藏表示的序列。在这里设计了两个映射函数。

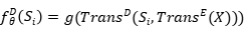
第一个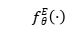 是无条件的,它重用了我们 Seq2Seq 模型的编码器;第二个
是无条件的,它重用了我们 Seq2Seq 模型的编码器;第二个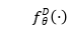 是有条件的,它考虑了输入序列。
是有条件的,它考虑了输入序列。
2.2 Sequence Similarity
定义映射函数后,可以计算序列相似度。为了不失一般性,设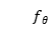 表示映射函数,其中
表示映射函数,其中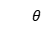 是函数的参数。其中,可以是和中的任何一种。另外使用了另一个映射函数
是函数的参数。其中,可以是和中的任何一种。另外使用了另一个映射函数 ,它与具有相同的架构,但具有参数
,它与具有相同的架构,但具有参数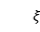 。通过应用和来获得
。通过应用和来获得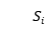 和
和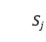 的表示:
的表示:
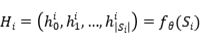

为了充分利用两个序列之间的词与词交互,在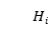 和
和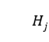 之间应用了交叉注意力:
之间应用了交叉注意力:
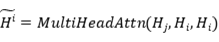
和之间的相似度是所有具有相同索引的向量的平均余弦相似度:

采用多头注意力(MHA)进行相似性计算有两个原因。(1)序列(尤其是文档)很长,MHA 考虑了两个序列中的所有标记对。(2)作者比较的两个序列可能有不同的长度(例如,文档与摘要)。MHA可以将一个序列的隐藏状态转换为与另一个序列的隐藏状态相同的长度,这更容易用于相似度计算。
2.3 Training
为了使和更接近,作者最小化以下损失函数:
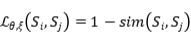
如果同时更新和中的参数,优化可能太容易了,这可能导致解决方案崩溃,因此本文使用来生成的回归目标。具体来说,作者在上述损失优化期间不更新中的参数,而是的移动平均值:

这个对比目标如图2所示。由于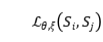 不是对称的,本文损失对称如下:
不是对称的,本文损失对称如下:
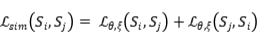
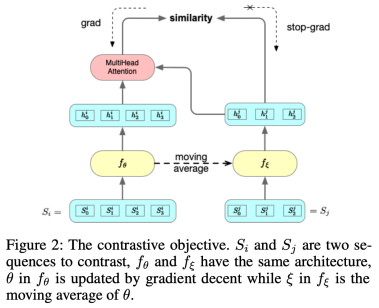
图2 对比学习的训练目标
为了加强文档 、其黄金摘要
、其黄金摘要 和模型生成摘要
和模型生成摘要 之间的相似性,采用以下损失函数作为最终训练损失:
之间的相似性,采用以下损失函数作为最终训练损失:
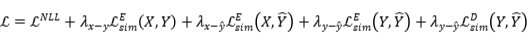
3. 实验
在CNN/DailyMail、New York Times和XSum数据集上进行了摘要实验,采取了Rouge指标评价和人工评价的方式验证模型结果,见图3、4、5。
作者认为可以使用多对文本进行对比学习。在对比学习中,使用超过一对文本获得了更差的结果,也许是因为使用不同的文本对学习的信息有点多余。比较了其他两个数据集的验证集和测试集的结果时,观察到了相似的趋势。
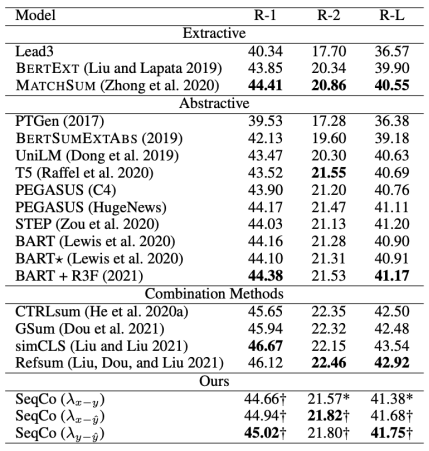
图3 CNNDM数据集上的实验结果
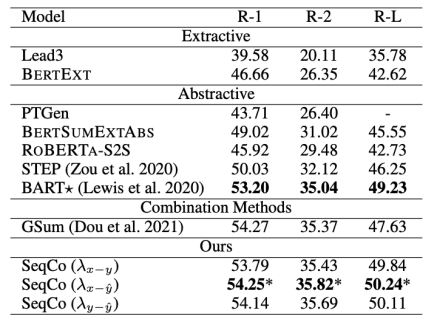
图4 NYT数据集上的实验结果
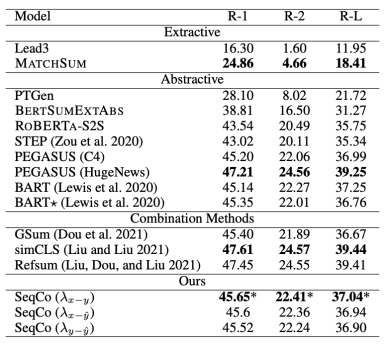
图5 XSUM数据集上的实验结果
作者对CNNDM、NYT和XSum进行人工评估,每个文档有 100 个。要求参与者根据他们的忠诚度对不同系统的输出进行排名,平均排名分数(越低越好)如图6所示。作者聘请(自我报告的)母语人士来注释我们在 Amazon Mechanical Turk上的输出摘要。为了进一步保证注释质量,过滤掉了不到两分钟的注释作业(每个作业花费的平均时间为6分钟)。在过滤过程之后,保证每个文档都由三个注释器注释。在CNNDM和NYT数据集中,Seqco的表现明显优于BART。在 XSum数据集中,这些系统之间没有显着差异。这可能是因为XSum中生成的摘要较短,注释者难以区分差异。作者计算注释者之间的一致性比率(即所有三个注释者的一致性比率和至少两个注释者的一致性比率)来衡量

图6 平均排名分数
4. 总结
在文本摘要中,可以将文档、其黄金摘要和模型生成的摘要视为相同含义表示的不同视图。本文中,作者提出了SeqCo,这是一种用于文本摘要的序列级对比学习模型,旨在最小化文档、其摘要及其在训练期间生成的摘要之间的距离。 在三个摘要数据集(CNNDM、NYT 和 XSum)上的实验表明,SeqCo 持续改进了强大的 Seq2Seq 文本生成模型。未来可以在多语言或跨语言文本生成任务中扩展 SeqCo。同时,作者在实验中观察到,使用多个对比目标并没有改善结果。
参考文献
[1] Xu S, Zhang X, Wu Y, et al. Sequence Level Contrastive Learning for Text Summarization[J]. arXiv preprint arXiv:2109.03481, 2021.
[2] Lewis M, Liu Y, Goyal N, et al. Bart: Denoising sequence-to-sequence pre-training for natural language generation, translation, and comprehension[J]. arXiv preprint arXiv:1910.13461, 2019.