WWW2020:利用情绪分布来区分健康报告文本中的比喻语言

1. 引言
Public Health Surveillance (PHS) 公共卫生监测系统被WHO定义为能够持续、系统地收集、分析和解释与健康相关的数据,为公共卫生实践的规划、实施和评估提供必要的支持。然而, 使用这些数据源的一个重要的缺点是其庞大的数量,数据的局部性和非结构化。新方法和工具对于数据的收集和汇总都需要了解大量的数据。关键的第一步是社会的认同与健康报告有关的媒体内容。这个任务已经被表述为一个二分类任务,目标是检测给定文本(如社交媒体帖子)是否报告健康状况的问题。一般来说,通常积极类表示健康提示,而消极类表示非健康提示。在本文的其余部分中,我们将这个二元分类问题称为健康提及分类(Health Mention classification, HMC)。
在这项工作中,作者提出了一种在Twitter上发布帖子的HMC方法(称为“tweets”)。在健康应用程序中收集Twitter数据的过程通常是通过关键字搜索,然而这也产生通常需要过滤以提高精度的低精度数据集。统计学习已经提出了一些技术来解决检测与健康有关的内容的问题(HMC)。然而,有几个改进的途径却很少受到关注,比如结合情感信息和上下文单词表示。
Iyer表明,症状词的比喻用法可以用来改善健康提及分类,考虑以下推文的例子:‘Idk if i got Parkinson’s or the chills’, ‘i nearly had a stroke readin this’, 其中黑体表示疾病词汇。这些推文都是对相关疾病词汇的比喻性提及,并不能按字面意思进行解释。疾病词汇更多是用于夸张表达,而不是提及健康。这些例子可能会给HMC和PHS系统带来困难,因为在非健康相关的上下文中提到疾病词可能会被错误分类,导致假阳性,从而降低准确性,导致对疾病流行程度的过高估计。
此外,疾病和伴随的症状可能是情感上的困难时期,这可能反映在这些人使用的语言中。考虑以下推文的例子::
i. ‘my grandpa just got diagnosed with lymphoma cancer today i am [expletive] devastated and don’t know what to do’ ,
ii. ‘i feel like my skull is about to crack [emoji] this headache is terrible [emoji]’,
iii. ‘i just feel sad sad my dads gone sad my best friends not my best friend anymore sad because depression is such a [expletive] to deal with ... ’.
在所有这些健康话题的推特上,都有明显的负面情绪流露,用斜粗体突出显示。作者假设,情绪信息可以帮助表明一条tweet是否在健康上下文中提到了一个疾病词汇。然而,据作者所知,在任何SOTA HMC方法中都没有包含这种情感介入的方法。
基于以上的想法,作者提出以下三个问题:
1) 比喻性提及是否对健康提及的分类有不利影响?
2) 相对于非上下文单词表示,上下文单词表示是否为HMC提供了性能改进?
3) 情感性和上下文词表示的结合能导致对当前SOTA HMC分类器的改进吗?
为了回答这些问题,作者做了一些实验来回答它们,从而构建自己的模型。
2. 前期工作
2.1 数据集构建
我们获得了一个2017年发布的包含大约7000个tweet id的英语Twitter数据集,涵盖了六种不同的疾病: Alzheimer’s disease, cancer, depression, stroke, heart attack and Parkinson’s disease。抓取的数据集包含大约5000个tweets,因为有些tweet在下载时不可用。为了扩展这个数据集,我们使用这六个关键字和四个附加关键字: cough, fever, headache and migraine的tweet进行了Twitter抓取,数据集的情况在下表中:
表1 数据集数量明细
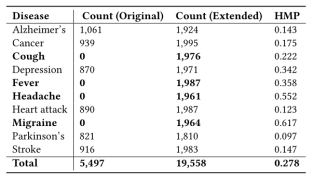
HMP是健康话题在推特中的比例。Twitter数量增加到19558条。总体上健康相关的推文占到27.8%。
表2 数据集内容举例
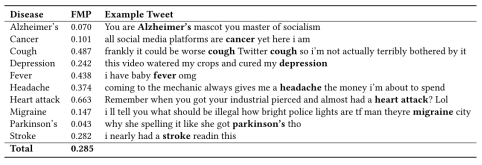
上表中FMP是比喻提及推文的比例,可以看到每一种疾病的FMP值不同,因为每种疾病名在现实生活中的使用情况是不同的。
同时,作者人工标注了一个新的标签,专门指出比喻提及推文,例子显示在下表中:
表3 标签举例

2.2 比喻提及与文本表示实验
在解决了数据集,并且标明了比喻提及的推文之后,作者开始探索比喻提及对任务的影响程度以及文本表示方法的实验。
为了探讨比喻提及对HMC的影响,作者训练了一个简单的逻辑回归分类器,利用TF-IDF加权的N-gram向量表示,10折交叉验证,进行简单的分类任务,并且定义了一个参数指标: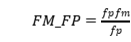 ,fpfm是假阳性的比喻提及推文的数量,fp是假阳性的总数,结果如下表:
,fpfm是假阳性的比喻提及推文的数量,fp是假阳性的总数,结果如下表:
表4 比喻提及的影响

从FPFM_FP指标我们可以看到,在所有疾病中,比喻性提及占50.6%的假阳性。这个范围从cancer的14.1%到heart attack的88.5%。从表中提供的结果可以看出,比喻性提及是造成误报的一个重要因素。
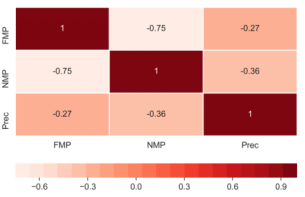
然而,假阳性率只是计算精度度量的一个因素。针对精确度指标并不与假阳性指标正相关的情况,作者做了相关性分析,定义NMP为非健康提及也非比喻提及,下图表现了NMP,FMP,精确度之间的相关性,可以看到NMP和精确度之间有更强的负相关性。
图1 相关矩阵热图
之后作者对时下常见的四种语言表示工具做了对比,结果见下表:
表5 文本表示的影响
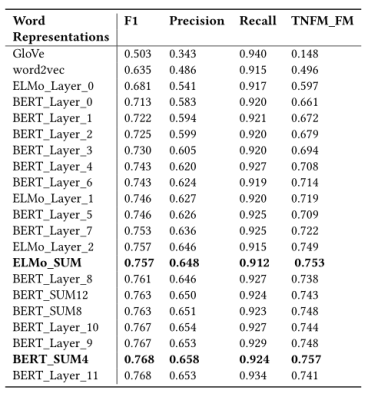
构建指标 ,tnfm是真实的负面比喻提及的数量,fm是比喻性提及的次数。我们发现,在大多数指标中,非上下文表示(GloVe和word2vec)是表现最差的单词表示。这表明上下文单词表示为HMC任务提供了更有用的信息。我们还看到所有ELMo层的总和是ELMo的最佳执行设置,比最后一个ELMo层ELMo_Layer_2在
,tnfm是真实的负面比喻提及的数量,fm是比喻性提及的次数。我们发现,在大多数指标中,非上下文表示(GloVe和word2vec)是表现最差的单词表示。这表明上下文单词表示为HMC任务提供了更有用的信息。我们还看到所有ELMo层的总和是ELMo的最佳执行设置,比最后一个ELMo层ELMo_Layer_2在 度量上稍好一些。最后4层BERT的总和BERT_SUM4是所有BERT表示的最佳执行设置。
度量上稍好一些。最后4层BERT的总和BERT_SUM4是所有BERT表示的最佳执行设置。
通过以上的实验,我们得到了比喻提及对分类结果的影响是很大的,并且上下文相关的文本表示更加适合HMC任务,从而构建了我们的主模型。
3. 模型
构建模型的动机有两个:
•提到疾病词的语境在决定一条tweet是否提及健康方面非常重要
•一条推文的情绪可能是健康提示的一个指标
考虑下面的推文:‘This tweet gave me cancer’ and ‘cancer is ruining my life’. 在这些例子中,将疾病cancer(癌症)一词去掉,突出了上下文感情上的差异。在第一条推文中,语境词在情绪上是中性的,疾病词用来表达负面情绪。这是比喻性提及推文中反复出现的主题。将这个例子与第二条推文进行对比,我们可以看到上下文词汇在情绪上是消极的,这是健康话题推文的一个常见主题。
图2 模型图
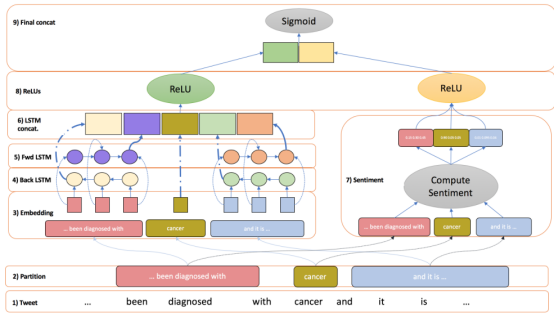
作者将输入的推文分为三个部分;上文,疾病词和下文。这种划分是希望明确地将上下文单词从疾病单词中分离出来,因为根据上文的实验可以看出,上下文就很重要。此外,我们希望捕捉到的情况是,在情绪上有一个对比的推特。对于左侧和右侧的tweet分区,计算一个基于预先训练的单词表示和一个情绪分布的序列。疾病词的划分仅由疾病词的表示和情绪分布来表示。将表示左右上下文的单词序列设置为数据中最大的可能序列,较短的序列填充到这个长度。
模型的左边是一个经典的双向LSTM模型,比较有利于提取上下文信息,重点是右边的情感计算模块,如何将情感分布添加到模型中。对于每一个部分,作者构建一个三维向量S=[tneg,tneu,tpos]用来描述它的情感偏向。这里采用了三种方法做对比:
利用 SentiWordnet 词典
利用 Valence Arousal Dominance (VAD) 词典
利用ULMFit模型训练分类器预测情感分布
从实验可以看出,VAD词典具有更好的鲁棒性,并且可以提供更多的信息。将双向LSTM的结果和情感计算的结果经过ReLU函数拼接到一起,做后经过一个sigmoid函数完成分类。
4. 实验
为了评估提出的分类器的性能,作者在扩展数据上运行HMC实验,只使用健康提及标签作为目标标签,忽略比喻提及标签,并将它们视为非健康提及。结果如下表,其中增量Δ是和第一个线性模型的比较。
表6 实验结果1

表7 实验结果2
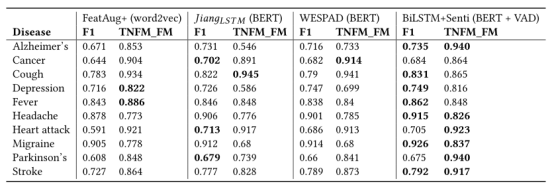
从表6所示的结果可以看出,我们的BiLSTM+Senti方法使用BERT训练词表示,并通过VAD 词典计算出情绪分布,总体上是性能最好的方法。F1 = 0.829,比线性BERT基线高9%,比第二好的SOTA方法WESPAD好0 .011点。作者的模型始终为ELMo和BERT表示提供最佳的F1。从表7还可以看出,在这10种疾病中,BiLSTM+Senti在F1得分最高的有7种。从表6中我们可以看到,作者的方法与BERT、ELMo和word2vec的TNFM_FM度量线性基线相比,提供了21.1%、19.4%和72%的巨大改进。当对BERT进行训练时,BiLSTM+Senti在TNFM_FM度量上的得分为0.046,对ELMo进行训练时为0.053,对word2vec进行训练时为0.129。在表7中,我们看到我们的方法在10种疾病中有6种获得了最高的TNFM_FM值。从情感资源的选择上可以看出,VAD取得最好效果。
在错误分析中作者提到两点:
1) 需要常识事实的知识
a) ‘just drank a kombucha for the first time and my depression is cured’,
b) ‘literally trying to not cough up my lungs from whats happening in my mentions’,
c) ‘I’ve had a headache ever since the jonas brothers reunited
2) 基于简单语言模式的错误分类
a) ‘for people who don’t like seasoning on their food cough cough’
b) ‘excuse my language cough cough but i am a bad [expletive]’
第一条需要一些常识信息推理,比如第一个例子,第一次喝kombucha就治愈了抑郁,很明显这是一个夸张手法,但模型缺乏常识会进行误判,第二条是由于一些语言上的一些固定模式,如重复,这样也会让分类器形成误判。
5. 总结
在本文中,作者展示了如何利用情绪分布来检测疾病报告(即,健康提及分类,HMC)。构建的分类器叫做BiLSTM+Senti。该分类器利用上下文单词表示和情感信息进入基于BiLSTM体系结构的分类器,产生了具有SOTA预测性能的分类器。文章首先表明,含有疾病词汇的推文经常被HMC系统错误地归类为与健康相关的内容。另外,在一个HMC分类器的所有误报中,有一半以上是被误标记为健康提及的比喻性推文。提到疾病词汇的方式有很大的不同(例如,“心脏病”在推文中通常是比喻性的,而“帕金森”则不是)。我们发现,疾病词的比喻提及比例与健康提及分类器对该疾病的准确性呈负相关。由此,我们得出结论,疾病词的比喻性提及对HMC模型是有害的,针对这些比喻性提及可以产生更健壮的HMC模型。在区分Twitter上的健康提及、非健康提及和疾病提及的比喻性提及时,上下文相关的词表示比非上下文相关的词表示更能提供信息。
关于工作的不足作者提到了三点:
1) 专注于有限数量的疾病和症状。不同的疾病可能会带来新的挑战;
2) 在任何监督分类实验中都没有使用添加的比喻标签;
3) 预训练模型没有进行微调,未来可能的工作是对这些模型进行微调。
这篇文章的优点在于:逻辑链条很完整,对搭建模型的各部分先用实验进行论证,比较有说服力。另外实验很丰富,针对问题的角度也很新颖。
不足之处我认为有两点:一是提升效果有限,针对于F1值最高提升1个百分点,第二点是消融实验不够充分,不能够说明各个部分的贡献,最有效的部分是哪一块,加上这一部分应该会更好。
参考文献
[1] Rhys Biddle, Aditya Joshi, Shaowu Liu, Cecile Paris, and Guandong Xu. 2020. Leveraging Sentiment Distributions to Distinguish Figurative From Literal Health Reports on Twitter. In Proceedings of The Web Conference 2020 (WWW ’20). Association for Computing Machinery, New York, NY, USA, 1217–1227. DOI:https://doi.org/10.1145/3366423.3380198
[2] Adith Iyer, Aditya Joshi, Sarvnaz Karimi, Ross Sparks, and Cecile Paris. 2019. Figurative Usage Detection of Symptom Words to Improve Personal Health Mention Detection. arXiv preprint arXiv:1906.05466 (2019).