Adapting BERT for Target-Oriented Multimodal Sentiment Classification
情感组 崔席郡
2022.03.21
本次主讲的一篇论文是发表于IJCAI 2019的 Adapting BERT for Target-Oriented Multimodal Sentiment Classification,这篇文章在传统的Target-Oriented Sentiment Classification(TSC)任务的基础上,针对Target-Oriented Multimodal Sentiment Classification(TMSC)任务,提出了一种基于BERT改进的多模态情感分类方法。本文的主要贡献如下:
(1)为TMSC任务设计了一种target-oriented multimodal BERT的结构。
(2)使用标准的BERT层来模拟目标文本和文本图像的对齐,并且设计了一个特殊的目标图像匹配层,结合目标注意力机制来模拟目标-图像对齐。
一、任务介绍
TSC是情感分析中的一项基本任务,旨在检测句子中提到的个人观点目标的情感极性。为了解决TSC问题,已经有各种有监督学习方法被提出。由于目前注意力机制的最新研究,许多研究提出了不同的基于注意力机制的神经网络结构来模拟观点目标与上下文本的相互关系,能够进一步提升在几个benchmark数据集上的SOTA。然而所有这些方法都有两个共同的限制:
第一, 大多数人只随机初始化他们的模型参数,这可能会导致在一些小规模、特定任务的与语料库上达到次优的结果,随着最近针对各种NLP任务的带有预训练参数的无监督语言模型趋势,很自然地期望这些初始化良好的模型能在不同的上下文本中捕捉到每一个词的语义信息和与语法信息,来为TSC提供更好的解决方案。
第二, 更重要的是,这些存在的方法基本上都是依赖文本内容,没有去考虑其他的数据源,比如图片,其可能会潜在地补充本文内容并增强这些基于文本的模型。
随着用户生成的内容越来越多模态,可以观察到相关图片通常对于TSC都有用。首先,用户生成的句子通常聚焦于一个观点目标,相关图片往往会突出这一目标;此外,有时很难去通过一个很短或不标准的句子去检测用户的情感,但是有了相关图片可能会有助于反映用户的情感;最后对于那些剩余的目标,句子往往表达他们的中立情感,图片也倾向于较少或者不关注他们。因此,探索如何去构建观点目标和文本、视觉内容之间的对齐,以建模模态内的动态,然后在面向目标的多模态情感分类(TMSC)统一模型中融合文本和视觉表示,以揭示它们的模态间对齐,将是一件有趣的事情。
二、模型构建
首先,得到了一个多模态样本集D,对于其中每一个样本c∈D,他包含一个带有n个词的句子S(w1,… wn),和一个相关图片I,以及一个观点目标T(S中第一个子序列)。对于观点目标T,它关联一个情感标签y,可以使积极的,消极的或者是中性的。该问题被描述如下:以D作为训练语料库,本文目标是学习一个面向目标的情感分类器,它能正确的预测未知样本中观点目标的情感标签。
由于BERT模型有助于从大型语料库中获得上下文本表示,具有学习两个任意输入之间的对齐的能力,因此将其用做基础模型。为了更好地将BERT用于TSC,本文将每个句子S转换成两个子句:即观点目标T和剩余的上下文C,并将他们concat作为BERT的输入序列。如下表:

用X =(x1,x2,…,xN)来表示转换后的输入,xi∈Rd是word,segment,和position embeddings的加和,N是最大序列长度。
接下来,简短介绍了BERT模型,在这里我就不再赘述了。
1.mBERT
在BERT模型的基础上,我们很容易且直观的想法是,直接将图片的最终隐藏状态concat到输入序列中,然后在顶部堆叠额外的BERT层,以模拟视觉和文本表示之间的跨模态交互。对于关联的图片I,本文先将它resize成224*224像素,然后采用SOTA图像识别模型ResNet-152来获取卷积层的输出,将原始图片分成7*7=49个区域,每个区域用一个2048维的向量rj来表示,然后用一个线性变换函数来映射视觉特征到本文特征相同的空间,然后将文本特征HS和图片特征G进行concat,然后将他们通过一个Multimodal Encoder,它包含另一组BERT层,用于自动模拟文本和视觉功能之间的丰富交互。
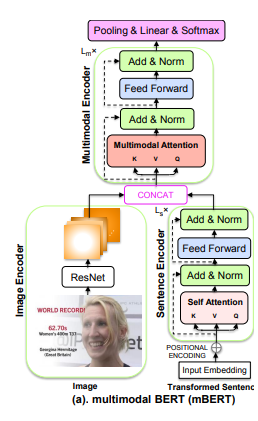
2.TomBERT
虽然mBERT模型有望较好的捕捉模态间的的动态,但其主要局限性在于其视觉模态表征对于观点目标不敏感,因为同一输入句子的视觉特征总是相同的,无论它考虑的目标是什么。直观地说,以特定的意见目标作为输入,通常情况下,只有相关图像的某些区域与之密切相关,而其他区域应该忽略以消除噪声。受此启发,本文设计了一个目标图像(TI)匹配层,该层采用m头目标注意机制来执行目标与图像之间的匹配,以获得对目标敏感的视觉表示。

如图所示,首先应用另一个BERT编码器来获得观点目标的隐藏表示,然后将目标HT的隐藏状态作为queries,区域图像特征G视为Keys和values,以便让目标引导模型将其与适当的区域对齐,仅对与目标密切相关的图像区域分配高注意权重。

其中W_Q,W_K, W_V , 分别是可学习参数,相似于BERT,采用前馈网络和两层带有残差网络的layer norms以获得目标敏感的视觉输出:
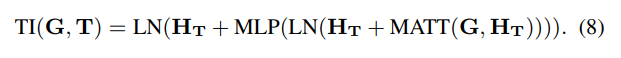
然后,将这些TI匹配层堆叠起来,以获得最终的视觉表示:HV=TILt(G,T),其中HV∈Rd×M和HV中的每个隐藏状态本质上是相关图像中49个区域的加权和。
接下来,为了形成多模态输入表示,考虑如下两种concat类型:
All-Text:直接将HV和HSconcat起来。
First-Text:只考虑HV中第一个元素的最终状态HV0,然后将其和HS concat起来。
为了整合最终分类的视觉和文本表示,使用以下三种pooling类型以获得最终输出:
FIRST:多模式输入序列的第一个标记始终是49个区域图像特征的加权和。其最终隐藏状态被视为聚合多模态序列表示,视觉表示作为查询,因此可以作为输出:O=H0;
CLS:类似地,特殊标记(即句子输入中的[CLS]标记)的最终隐藏状态是以文本表示作为查询的聚合表示,也可以用作输出:O=H[CLS];
BOTH:将H0和H[CLS] concat后作为混合输出。
最后,将O输入一个线性函数,然后是一个softmax函数,用于面向目标的情感分类:
目标是最小化标准交叉熵损失函数:
三 实验结果与评价
为了评估BERT和TomBERT的效果,采用了三个TSC benchmark数据集, SemEval-2014任务4中的 LAPTOP和REST、TWITTER-14以及两个多模态数据集TWITTE-15和TWITTER-17。
结果如下:
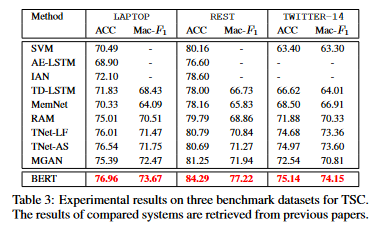
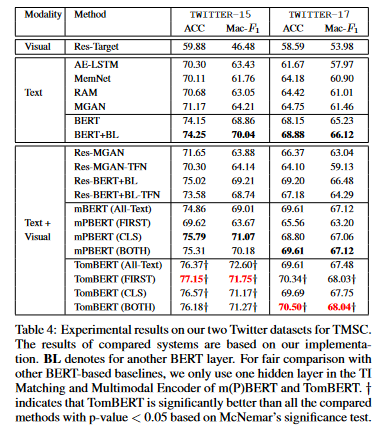
对于TomBERT的进一步分析,文章研究了mBERT和TomBERT中不同成分的影响。
首先,比较表4中的三种pooling类型,观察到以下几点:
1)。无论使用哪种pooling类型,TomBERT通常都比mPBERT性能更好。由于它们之间的唯一区别是TI匹配模块,这表明本文的目标注意机制能够生成对目标敏感的视觉表征,这可以显著提高性能;
2)对于mPBERT而言,由于其视觉表示对目标不敏感,因此使用其最终隐藏状态(即FIRST)会导致有限的性能是合理的。相比之下,使用CLS和二者都可以学习更多地关注文本表征,并获得更好的结果;
3)对于TomBERT来说,由于视觉和文本表示都是目标敏感的,所以直观地说,所有三种池类型都可以产生有希望的结果。
四、总结
本文中研究了面向目标的多模态情感分类(TMSC),并提出了一种Target-Oriented Multimodal BERT(TomBERT)体系结构,以有效地捕捉模态内和模态间的动态。对TSC和TMSC的五个数据集进行的广泛评估表明,BERT和本文提出的TomBERT模型在检测个人意见目标的情感极性方面是有效的。