SG-Net: Syntax-Guided Machine Reading Comprehension
这是2020年上交赵海老师团队发表在AAAI上的针对阅读理解相关的论文。
1论文的动机:
当前的针对阅读理解任务的方法有存在亮点不足:
1)传统的注意力模型,对所有词不加任何显式约束地计算注意力向量,会因为一些干扰词(非必须的词)的无差别对待而导致MRC的精度的下降。
2)目前几乎所有的注意方法和语言模型都把输入顺序看作一个整体,例如,一段文字,没有考虑每个句子的内部语言结构。这将导致过程偏见所造成的噪音和缺乏相关的跨度为每个有关的字
所有这些因素促使我们寻求一种信息方法,通过明确地考虑每个输入句子中具有句法重要性的词的相关子集,可以有选择地挑选出重要的词。在句法结构线索的指导下,句法引导法可以给出更准确的注意信号,减少冗长句子带来的噪音影响。
因此本文的解决思路是:
在BERT上下文vector的基础上,对passage和question分别进行句法解析,引入语法向导的(syntax-guided)上下文vector。从而获取句法信息指导的词向量表示。本论文提出“二元上下文表示架构-SG-NET”来获取更加精细的passage, question的向量表示。
2论文的方法:
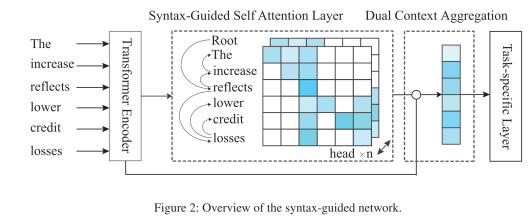
模型主要由两部分组成。
2.1:Syntax-Guided Self Attention Layer
经过bert编码输出H后,我们再利用H 做一次带有syntax mask的self-attention,而关键之处就是设置带有句法结构信息的mask。本文作者采用的方法是先预训练一个dependency parser,然后对文章和问题都进行dependency parsing,这样我们可以得到一个依存分析图。然后作者令每个单词只能够看到它自己和它的子节点(直接和间接),以此来构建一个attention mask,如下图的例子所示。
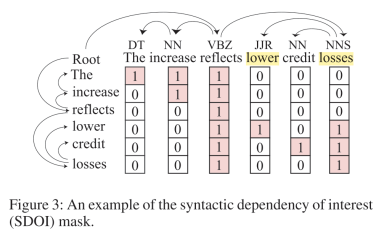
因此对于文章和问题中的每个单词si,我们预先通过dependency parser预处理出他可见的单词集合{pi},然后根据这些信息训练出attention mask M;

有了Mask M之后,就可以按照multi-head self-attention的方式,来计算Figure 2中的所谓“Syntax-Guided Self-Attention层”;
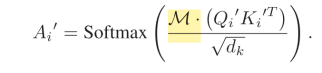
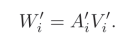
上面的公式中,下标i代表第i个head;之后对得到的每个head的W’i进行串联之后,就得到最后的H’了。
2.2: Dual Context Aggregation
接下来作者将不带syntax信息的表示H和带有syntax信息的表示H’进行融合,它采用的是一个线性组合得到最终的表示
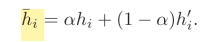
3论文的实验:
在两个数据集上进行了实验,一个基于span提取的SQuAD2.0,另一个是基于MCQ的RACE数据集
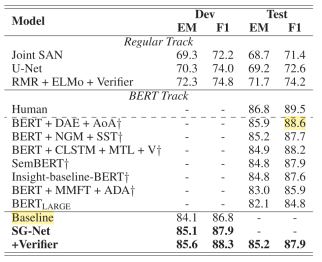
3.1 SQuAD 2.0的实验结果
在RACE上的实验结果:

3.2: 消融实验
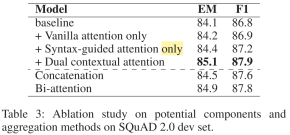
从消融实验可以看出可以看到Syntax-guided attention对baseline的提升是比较显著的(EM 1.3 % 1.3\%1.3% F1 0.4 % 0.4\%0.4%);
3.3 回答长问题的有效性

如图4所示。我们观察到,当遇到长问题时,基线的表现会大幅下降,特别是对于那些超过20个单词的问题,而我们提出的 SG-Net 工作稳定,甚至在准确性和长度之间显示出正相关。这表明,与基线相比,使用语法增强的表示方式,我们的模型能够更好地处理冗长的问题。
3.4 可视化
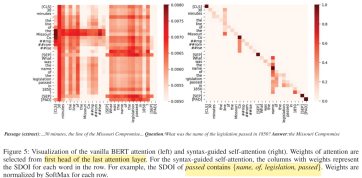
左边是没有任何限制的self-attention,可以看到噪声是很多的,每个词对于句子中其他所有词都有着千丝万缕的联系。而右边是加入了syntax以后的attention weight,非常清爽,每个词都只与和它语法结构上相关的词之间有联系,而且也能看得出问题的答案也被成功地赋予了很大的权重。
4总结:
这篇文章的核心就是syntax-guided,加入了语法结构这种先验知识以后模型效果有了不小的提升。基于syntax-tree的mask tensor可以很好的基于句法结构信息对非必要的词的依存关系进行一定程度的“剪枝“或者退火。