Adversarial Learning for Zero-Shot Stance Detection on Social Media
情感组 张浩
本次主讲的论是发表于
NAACL
2021的Adversarial Learning for Zero-Shot Stance Detection on Social Media,这篇文章定义了社交媒体零样本立场检测的任务和方向,对于零样本的迁移利用了对抗学习的方式去提高跨主题的泛化性。
一、任务介绍
立场检测任务被当做情感分类的一个子问题,主要目的是为了识别文本作者对于某一个目标的立场,这个目标可以是实体、声明、观点、主题等等,他们可以在原文中提及,也可以在原文中不被提及,这些目标在这篇论文里统称为主题,对于输入的文本,要输出作者的立场:支持、反对、中立三种。下图的数据集为SemEval-2016 Task 6的数据集,是推特中的立场数据集。

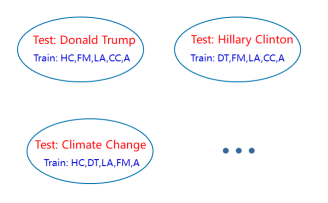
从上面的数据集可以看出,立场检测对于目标的依赖非常严重,同一段文本可能因为目标的切换,立场发生反转,如果要研究文本立场,对所有目标进行标注显然是很耗费成本,可行性很差的,所以零样本的立场检测任务被提了出来,在EMNLP2020上论文作者就制作了一个专门用在零样本立场检测上的数据集,也定义了零样本立场检测问题,作者把该任务当做了一种域适应的任务。具体的,在本文的任务中把SemEval-2016 Task 6数据集中的每个主题的数据集放到一起共同做切分,六个主题,五个主题的数据集作为训练集,剩下一个主题作为测试集,这样轮转在六个数据集上进行立场检测实验。
二、模型方法
在领域适应中,对抗性学习迫使模型学习领域不变(即主题不变)特征,然后可以将其转移到新领域。 为此,分类器和鉴别器从相同的特征表示中联合训练,以最大化分类器的性能,同时最小化鉴别器的性能。

1. 面向主题的文本编码器
这部分使用双向条件编码 (BiCond)对每个样本进行编码,以主题为条件的计算表示对于零样本姿态检测有很大的效果提升。首先使用 BiLSTM将主题编码,然后使用这个主题编码为条件通过第二个BiLSTM 对文本进行编码。
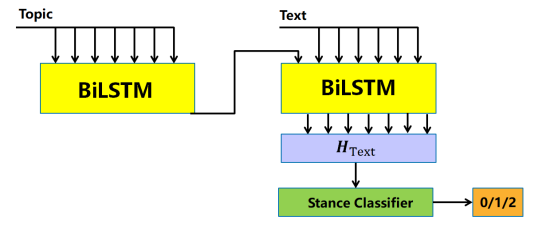
2. 主题鉴别器
本文提出的主题鉴别器是一个带有 ReLU 的两层前馈神经网络,并在给定线性变换层的输出的情况下预测输入的主题。为了学习对源域和目标域都不变的表示,使用数据集中源主题的标记数据和零样本主题的未标记数据训练鉴别器,在这个过程当中,使模型对立场的分类更明确,对主题的分类更模糊,达到训练出对主题无关的表示。

文中提出的模型是通过组合单个组件损失进行训练。 对于立场分类器和主题鉴别器,使用交叉熵损失(分别为 Ls 和 Lt)。 由于假设主题不变表示将非常适合零样本传输,因此希望最小化判别器从输入中预测主题的能力并且在最大化 Lt 的同时最小化 Ls,在反向传播期间使用梯度反转来做到这一点。 所以最终的损失函数是:
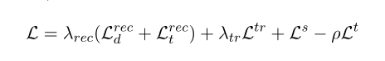
三、实验结果与评价
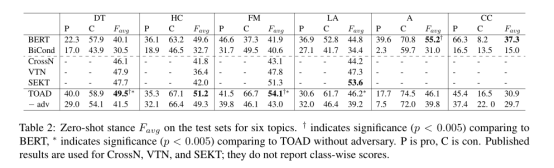
实验的平均指标为Favg:F1 是在 支持立场和 反对立场上的平均值。我们的模型 TOAD 在跨目标姿态检测中使用的四个主题中的两个(DT,FM)(DT:唐纳德特朗普,HC:希拉里·克林顿,FM:女权运动)上实现了最先进的结果(见表 2) ,洛杉矶:堕胎合法化)。与 BERT 基线和没有对抗训练 的 TOAD 相比,这些结果具有统计学意义 (p < 0.005)。此外,本文还提供了以前未用于零样本评估的两个主题(A:无神论,CC:气候变化是一个真正的问题)的基准结果。我们还观察到,TOAD 在另外三个主题(HC、LA、CC)上与 BERT 在统计上无法区分,而参数只有 0.5%(600k 对 1.1 亿)。由于体积小,TOAD 可以仅使用 CPU 进行训练,并且由于它的循环架构,从 GPU 增加的并行计算中获得的收益会更少(与基于转换器的模型相比)。因此,TOAD 对环境的影响可能比 BERT 低得多,在六个零样本中的五个主题上具有相似(或更好)的性能。
四、总结
本次介绍了Adversarial Learning for Zero-Shot Stance Detection on Social Media,这篇文章提出了利用对抗学习来泛化零样本立场检测的主题泛化性,这一点是一个启示,可以用在其他任务的零样本分类上,并且本文也提出了零样本分类的方向,也可以进行参考,在这个方向的基础上做一些工作。