本文中,作者探讨了只使用每个类的标签名,而不使用任何标签文档,在未标记数据上训练分类模型的可能性。作者使用了预先训练好的神经语言模型作为类别理解的一般语言知识源和文档分类的表示学习模型。该方法包含以下几步:(1)将语义相关词与标签名称相关联,(2)找到类别指示词并训练模型预测其隐含类别,以及(3)在整个未标注的语料库中自训练这个模型。实验结果表明该模型在四个基准数据集(包括主题和情感分类)上实现了约90%的准确率。
1. 引言
文本分类是自然语言处理(NLP)中的一项经典和基本任务,有着广泛的应用,如问答、垃圾邮件检测和情感分析等。深度学习方法如CNN、RNN等得到了广泛的应用,并且基于预训练的语言模型在这方面取得了很大的成功。近年来,半监督文本分类受到了越来越多的关注,它需要的标记数据量要小得多。但是需要领域专家的付出,这是非常困难的。与现有的监督和半监督模型不同的是,人类专家只需要了解每个类别的标签名称(即一个或几个代表性单词)就可以对文档进行分类。例如,当我们给新闻文章起“体育”、“商业”和“政治”等标签名称时,我们可以很容易地对其进行分类,因为我们能够基于先验知识理解这些主题。
在本文中,作者研究了弱监督文本分类问题,其中只提供每个类的标签名称来训练纯未标记数据上的分类器。提出了一种语言模型自训练方法,其中预训练的神经语言模型被用作类别理解的一般知识源和分类的特征表示学习模型。从未标记的数据创建上下文化的单词级类别监督,以进行自我训练,然后通过自我训练目标将其推广到文档级分类。
提出了标签名称文本分类的LOTClass模型,该模型分三步构建:(1)使用预训练的LM为每个类别构造一个类别词汇表,其中包含与标签名称语义相关的单词。(2) LM在未标记的语料库中收集高质量的类别指示词,通过上下文的词级类别预测任务训练自己捕捉类别独特信息。(3) 通过对大量未标记数据的文本进行自训练来泛化LM。
2. 方法
2.1 通过标签名称替换来理解类别
通过标签名称替换来理解类别。使用预先训练好的带掩码的 BERT 语言模型(MLM)来预测在大多数情况下什么词可以取代 label 名称。在语料库中,每次出现标签名(label name),通过BERT编码器生成 contextualized 的 embedding 向量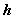 (长度为
(长度为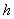 ),将其输入MLM的头,输出在整个语料库的词汇 V 上的概率分布,显示每个单词
),将其输入MLM的头,输出在整个语料库的词汇 V 上的概率分布,显示每个单词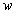 出现在这个位置的可能性:
出现在这个位置的可能性:
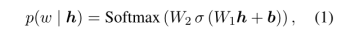
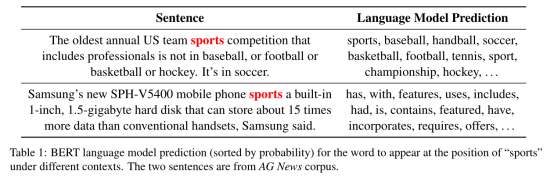
可以观察到对于每个被掩盖的词(masked word),前 50 个预测词通常与原始词有相似的意义,因此我们使用MLM给出的 50 个词的阈值,来定义对标签名称在语料库中每次出现的有效替换 (valid replacement)。
将词汇根据在语料库中有效替换标签名称的次数来排序,选取排名前100 位的词汇来形成每个类别的类别词汇表 category vocabulary,用 NLTK (Bird et al,2009)去掉停用词和出现在多个类别中的词汇。
2.2 被掩盖类别的预测
人们通常在进行分类时关注的一般是句子序列中的类别指示词。如:“篮球赛是一个常常在中学生中风靡的赛事。”,人类通过“篮球”“赛事”来判断这个句子属于“运动”类。同样,我们也希望应用到机器上。一种方式是直接关注方法1中得到的 category vocabulary 的条目在语料库中的每一次出现。这种方式的问题是:
(1)category vocabulary 中有些词不能很好地指示这个类别:
词汇的含义是随上下文变化的,不是每次类别关键词出现时都指示了这个类别。比如:“宇宙中没有不动的物体,一切物体都在不停的运动。” 虽然出现了“运动”这个类别关键词,但并不意味着主题“运动”。
(2)category vocabulary 可能不全:
类别词汇表涵盖范围有限,特定语境下的一些术语可能与类别关键词的含义相似,但不包含在category vocabulary中。比如:“百步穿扬”。
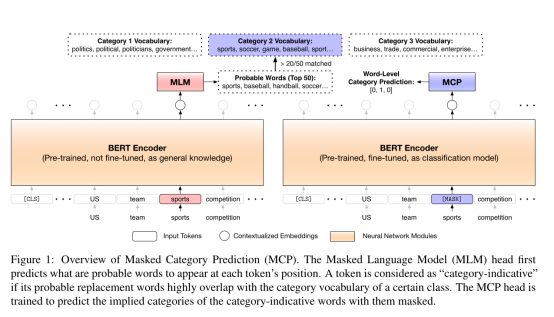
如 Fig.1 所示,一个预训练的LM模型创建了上下文相关的词级(word-level)类别监督,用于训练自身在词汇被掩盖时预测词汇的隐含类别。为了创建语境化的词级类别监督,我们重用(reuse)了 方法1 中的预训练MLM方法,通过检查它们的有效替换词汇,来理解每个词的语境含义。如表1所示,MLM的预测词很好地反映了原词的含义。和之前一样,我们将MLM给出的top-50认为是原词的有效替换。另外,对于一个,如果的替换词中超过20/50出现在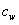 的类别词汇表category vocabulary中时,将作为类别的类别指示词 category-indicative。
的类别词汇表category vocabulary中时,将作为类别的类别指示词 category-indicative。
通过检查上方语料库中的每个词,我们将得到一个类别指示词和对应类别标签的集合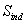 作为词级监督。对于每个类别指示词,我们用【MASK】掩盖它,并训练模型来预测的指示类别,输入的语境化向量,通过交叉熵损失和一个分类器(一个线性层):
作为词级监督。对于每个类别指示词,我们用【MASK】掩盖它,并训练模型来预测的指示类别,输入的语境化向量,通过交叉熵损失和一个分类器(一个线性层):
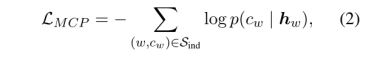
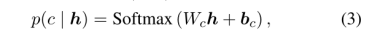
其中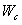 和
和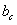 是线性层的可学习参数。(K是类别数)
是线性层的可学习参数。(K是类别数)
我们注意到,为了进行类别预测,必须屏蔽类别指示词,因为这将迫使模型根据单词的上下文 “contexts” 来推断类别,而不是简单地记住与上下文无关的类别关键字。这样,BERT编码器将学习去将序列中的类别判别信息category-discriminative information 编码到语境化向量中,这有助于预测该位置的类别。
2.3 自训练
在用MCP任务训练LM后,我们提出在整个未标注的语料库中自训练这个模型。主要有以下两个原因:
(1)依然存在很多在MCP任务中还不曾被模型发现的未标注文档(由于没有检测到类别关键词),这可以用于优化(refine)模型,使之更好地泛化(generalization)。
(2)分类器已经被训练为可以在top words被屏蔽时预测它们的类别,但是还未被应用于【CLS】标号,这种情况下模型被允许查看整个句子序列来预测类别。
自训练(ST)的思想是:迭代使用模型的当前预测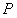 来计算一个目标分布
来计算一个目标分布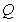 ,它可以指导模型改进(refinement)。ST目标的一般形式可以用 KL发散损失(divergence loss)表示:
,它可以指导模型改进(refinement)。ST目标的一般形式可以用 KL发散损失(divergence loss)表示:
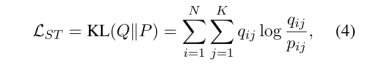
其中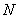 是实例 instance 的数量。
是实例 instance 的数量。
对目标分布有两种主要选择:Hard labeling 和 Soft labeling。
软标记(Xie et al.,2016)通过增强高自信预测,并对当前预测进行平方和归一化来降低低自信预测,从而得到Q:
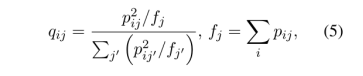
将MCP训练的分类器(公式(3))应用于每个文档的【CLS】标记进行模型预测:

在实践中,我们发现软标记策略始终比硬标记提供更好和更稳定的结果,可能是因为硬标记将高自信的预测直接视为ground-truth标签,更容易错误传播。软标记的另一个优点是,可以计算每个实例的目标分布,不需要预先设置置信阈值。
将50作为批量大小,通过 公式(5) 更新目标分布,通过 公式(4) 训练模型。
3. 算法
输入:一个未标注的文本语料库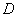 ; 一个标签集
; 一个标签集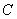 ; 一个预训练的神经语言模型
; 一个预训练的神经语言模型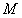 。
。
输出:一个训练好的模型,用于分类 个类别。
个类别。

4. 实验
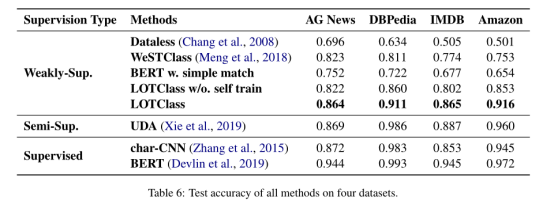
主要实验结果如表6所示,LOTClass始终比所有弱监督方法有很大的优势。即使没有进行自训练,LOTClass的消融版本在所有数据集上都表现良好,证明了我们提出的类别理解方法和MCP任务的有效性。在自训练的帮助下,LOTClass的性能可以与最先进的半监督和监督模型相媲美。
5. 讨论
1、弱监督分类的潜力还未被完全开发。
(1)为了使方法简单明了,我们只使用了基于BERT的简单模型,而不是更高级的更近期的语言模型。
(2)我们只使用了至多3个单词作为每个类别的标签名称。
(3)我们没有使用像反向翻译系统之类的其他依赖项进行增强。我们相信,随着模型的升级,输入的丰富和数据处理技术的使用,性能将会变得更好。
2、将弱监督模型运用到其他的自然语言处理任务。
很多其他NLP问题都可以被表示为分类任务。比如,命名实体识别(named entity recognition)和面向方面的情感分析(ABSA:aspect-based sentiment analysis) (Huang et al., 2020)。有时标签名称含义有一般性,以至于不好诠释,比如"person","time"等。为了应用类似这篇文章的方法到这些情景下,可以考虑使用更具体的示例术语(如特定的人名)来实例化标签名称。
3、弱监督文本分类的局限性。
在一些困难情况下,标签名称不足以教会模型进行正确分类。比如,有些评论文本的隐含语义可能与词级理解是对立的。
“I find it sad that just because Edward Norton did not want to be in the film or have anything to do with it, people automatically think the movie sucks without even watching it or giving it a chance.”
因此,用主动学习(active learning)来改进弱监督分类将是一件很有趣的事情,在这种情况下,模型允许用户对困难的情况给出结果。
4、是否可以和半监督分类方法相结合。
我们可以很容易将弱监督与半监督方法集成到不同场景:
(1)当没有训练文本可用时,弱监督方法的高可信预测可以作为真实标注(ground-truth labels)来初始化半监督方法。
(2)当训练文本和标签名称都可用时,可以设计一个联合目标,用单词级任务和文档级任务来训练模型。
6. 总结
这篇文章证明了标签名称是一种有效的文本分类监督类型,它可以避免繁琐的人工标注过程,降低了分类成本,也有一定的准确率,未来可以更加完善。