本篇论文发表于ACL2021,本文作者来自 QTrade、华盛顿大学和香港中文大学。QTrade 是腾讯旗下的一家公司,利用人工智能和大数据技术为市场提供解决方案。
主讲主要分为以下四个部分: 第一部分为引言;其次,详细介绍他们提出的方法;然后,介绍作者的实验结果;最后,将简要总结他们的贡献。
第一部分是引言。
众所周知,关系抽取是一项重要的自然语言处理(NLP)任务,它有助于提高信息抽取。以往的研究试图通过在模型中加入额外的知识来提高关系抽取的性能。在这些知识中,输入句子自动生成的依存关系分析中的句法信息表明其有助于提高模型性能,因为词依存关系提供了长距离上下文信息。

然而,在以往的研究中,主要集中在词之间的依赖关系上,很少关注依赖类型,这也是帮助关系抽取任务的必要条件。此外,以前的研究也受到自动生成的依赖树噪声的影响,在这种情况下,所有的依赖都被平等地建模,而没有确定它们对任务的贡献。
针对这些问题,作者提出了本文的方法。他们的贡献主要如下:首先,对于实体中的每个单词,作者提取与其相关的依赖信息,其中考虑两种类型的依赖信息(实体内和跨实体);其次,提出了一种基于类型感知映射存储器(TaMM)的神经网络关系抽取方法,该方法考虑了依赖类型和依赖路径的权重;最后,在ACE2005和SemEval 2010任务8上对模型的性能进行了评价,作者的模型实现了最先进的性能。
第二部分介绍本文提出的方法。
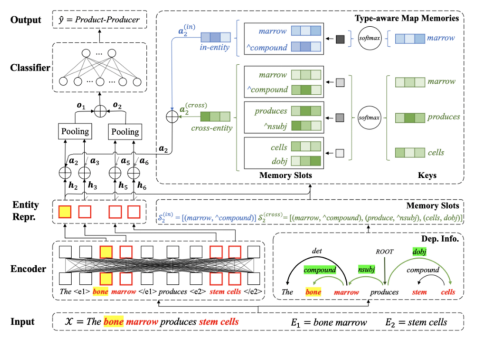
上图是作者的方法的架构,例句中用用红色高亮显示实体。左边部分显示了主干分类模型; 右边部分显示了通过提出的类型感知映射存储器(TaMM)利用与“ bone”(用黄色高亮显示)相关的实体内和跨实体存储槽的过程。实体内存和实体间存储槽分别用蓝色和绿色标记。
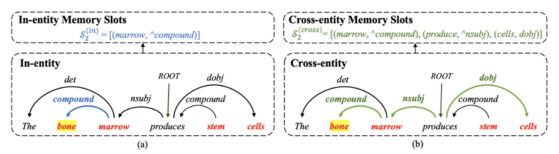
首先,让我们看看作者是如何构造内存插槽的。它们首先使用现成的工具包生成输入 x 的依赖解析结果,对于 x 中的任意两个单词,它们之间只有一条路径。对于实体中的每个单词,考虑由获得的 x 的依赖树建议的两种依赖信息,并构造它们相应的内存插槽。
第一个是“实体内”存储槽。实体内存插槽通过依存解析关注连接到输入单词的上下文信息。为了构造它们,首先从依赖树中定位调节器和输入词的所有依赖项。然后将调控器和依赖项作为存储器插槽中的键,将它们的依赖关系作为对应的值。因此,我们可以得到第 j 个存储插槽列表。其中 k 是通过依赖关系连接 x 的单词,v 是它们之间的依赖关系类型。例如,在这个图中,对于第一个实体“bone marrow”中的单词“ bone”,它的实体内存插槽是[(������������,ˆ����������������)]。类似地,如果我们关注的单词是“ marrow”,那么它的实体内存插槽应该是=[(��ℎ��,������), (bone,compound), (����������������,ˆ����������)]。ˆ表示句法依赖的方向。
跨实体存储槽的目的是沿着两个实体之间的依赖路径合并上下文信息。为了构造跨实体内存槽,对于 中的每个
中的每个 ,首先找到从到另一个实体最后一个字的依赖路径,使用最后一个词的动机是英语中的名词短语往往是head-final。然后,类似于构造实体内存插槽的过程,提取该路径上的所有单词以及相应的依赖关系类型。最后,它们将词作为键,将依赖关系类型作为内存插槽中的值。对于“bone”这个词,定位 “bone”和第二个实体“stem cells”的最后一个词“cells”之间的依赖路径是“bone–marrow–produces–cells”。因此,“bone”的跨实体存储槽就是=[(������������,ˆ����������������), (����������������,ˆ����������), (����������,��������)]。
,首先找到从到另一个实体最后一个字的依赖路径,使用最后一个词的动机是英语中的名词短语往往是head-final。然后,类似于构造实体内存插槽的过程,提取该路径上的所有单词以及相应的依赖关系类型。最后,它们将词作为键,将依赖关系类型作为内存插槽中的值。对于“bone”这个词,定位 “bone”和第二个实体“stem cells”的最后一个词“cells”之间的依赖路径是“bone–marrow–produces–cells”。因此,“bone”的跨实体存储槽就是=[(������������,ˆ����������������), (����������������,ˆ����������), (����������,��������)]。
在学习依赖信息的过程中,在自动生成的依赖结果中存在噪声,会影响模型的性能。为了解决这个问题,作者提出了一种类型感知映射存储器(TAMM) ,用来合并键和值所携带的依赖信息。具体地说,对于实体中的每个单词,考虑两种类型的依赖关系信息,并使用相同的过程对它们进行建模。首先使用两个矩阵将存储器插槽中的键和值映射到它们的嵌入中。然后,通过键嵌入和 x 的隐向量之间的内积,计算每个值的有符号权重,然后对相应的存储槽应用权重,得到键和值的加权和。最后,将生成的两个向量连接起来,如下图所示。
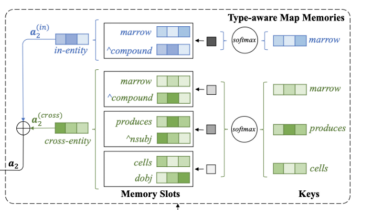
一旦构建了 TaMM,就可以直接通过骨干分类器将其应用于关系提取。在作者的方法中,他们使用 BERT 作为分类器对输入 x 进行编码,并获得两个实体中单词的隐层向量。因此,对于实体 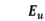 中的每个单词 ,将
中的每个单词 ,将 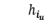 输入 TaMM 并获得相应的输出
输入 TaMM 并获得相应的输出 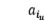 。然后,将 和 连接起来,对于每个实体,使用最大池化策略获得向量表示 o。
。然后,将 和 连接起来,对于每个实体,使用最大池化策略获得向量表示 o。
第三部分是实验与结果。
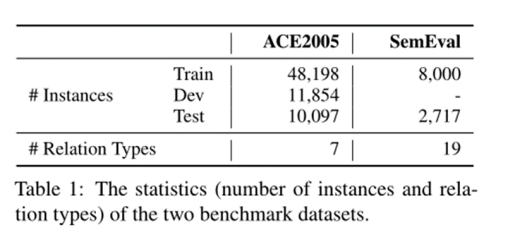
实验中使用了两个英语基准数据集 ACE2005EN 和 SemEval 2010 Task 8来评价该方法。
在主实验中,作者使用带 TaMM 和不带 TaMM 的 BERT-base 和 BERT-large 编码器运行他们的模型,并尝试不同的实体依赖信息和跨实体依赖信息组合。选择的基线为标准图卷积网络(GCN)、标准图注意网络(GAT)和 KVMN。下表显示了不同模型的结果(f1分数)。
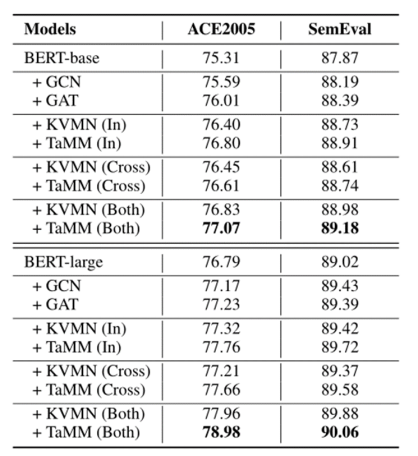
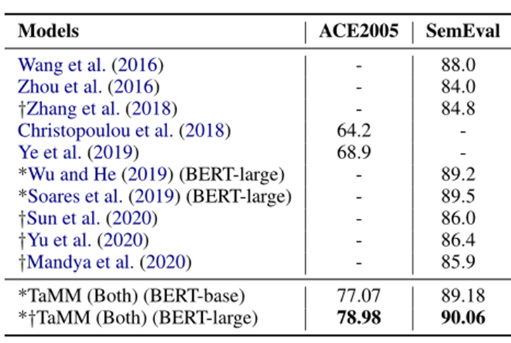
此外,作者将他们的模型在最佳环境下与以前的研究进行比较,并在下表中报告结果。结果表明,本文提出的模型性能优于以往的研究成果。
为了分析使用依赖信息的效果,作者对使用 BERT-large 编码器的模型进行了三次研究。第一个研究是检查 TaMM 中使用的不同依赖阶数。他们通过模型尝试二阶和三阶依赖。从下表中我们可以看到,对于使用 TaMM (Both)的模型,使用高阶依赖项通常会导致较差的结果; 而对于使用 TaMM (in)的模型,趋势正好相反。作者给出的解释是,对于 TaMM (both) ,两个实体之间最基本的词依赖关系已经编码,高阶依赖关系有时会引入非有用信息的噪声; 而对于 TaMM (in) ,利用高阶依赖关系允许模型沿着两个实体之间的依赖路径覆盖更多上下文信息。

第二部分是探讨模型在按实体距离分组的不同测试实例上的性能。作者根据实体距离将 SemEval测试集分成三组。可以发现,TaMM 在所有三组测试实例中都优于 BERT-baseline,在这三组测试实例中,当实体的距离增大时,可以观察到更大的间隔。实验结果表明,该方法能有效地对依赖信息进行编码,从而提高关系抽取的效率。

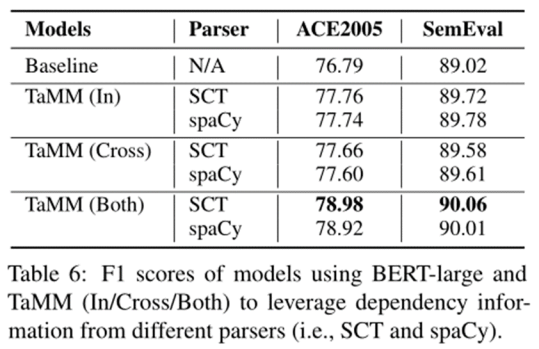
第三个研究是探讨 TaMM 使用不同依赖解析器的效果。具体来说,除了主要实验中使用的 Stanford CoreNLP 工具包(SCT)之外,作者还尝试使用 spaCy 获得依赖树。结果表明,不同依赖解析器的模型的性能均优于基线,说明作者的模型设计在改进关系抽取方面具有较强的鲁棒性。
最后,总结本文的贡献。首先,对于句子中的每个实体,根据输入句子的依存关系分析及其相应的依存关系类型提取与其相关的单词。然后,作者提出 TaMM 对这些信息进行编码和加权,并将其集成到关系抽取任务中。在两个公共英语基准数据集上的实验结果表明,该方法在所有数据集上都取得了最佳性能。