On the Cost-Effectiveness of Neural and Non-Neural Approaches and Representations for Text Classification: A Comprehensive Comparative Study
本次主讲论文是一篇综述类论文,基于神经网络和非神经网络文本分类的成本有效性研究。发表在中科院1区,CCF B类期刊“Information Processing & Management”。论文主要是对最近关于自动文本分类 (ATC) 的神经和非神经方法的批判性分析,分析的重点是评估此类研究的科学严谨性,揭示了与实验程序相关的大量潜在问题。包括: (ii) 缺乏对结果的统计处理; (iii) 缺乏基线超参数调整的细节; (iv) 使用不充分的分类有效性度量(例如,偏态分布的准确性)。论文还考虑了模型有效性和成本(即训练时间)之间的权衡。
目前深度神经网络在文本分类中的应用主要依赖于:用于训练或词汇构建的大量数据;
探索海量计算能力,通常只有大公司才能使用;越来越复杂的学习模型,例如具有多层和复杂架构的深度神经网络。这样就会导致一些问题。这些限制只有一小部分能够继续进行此类研究的大型参与者(由于 1,2),复现性的困难以及与结果的透明度和可解释性相关的问题(由于 3)。目前文本分来工作存在的问题,选择和比较可能较弱或调整不足的基线;使用不充分的实验方案;缺乏对结果的统计处理,例如使用统计显着性检验或置信区间;使用不充分的评估指标。
本文的研究目标,提供证据表明最近关于 ATC 和/或 ATC 文本表示的主要研究中的很大一部分在所采用的实验程序中包含潜在的问题; 考虑训练成本和分类有效性之间的权衡作为主要分析方面,对(最近的)神经和非神经文本分类解决方案进行全面和科学的比较。
本文的第一个贡献是对近期文献(2010-2020年)的批判性分析,分析了这一时期论文实验设置中可能存在的问题。它是通过选择和分析在 Google Scholar 4 和 Semantic Scholar 5 上发布的多个查询产生的前 100 篇最常引用的相关论文来进行的。方法比较——本文比较了最近的神经和非神经文本分类解决方案。 这项研究的新颖性取决于其规模、实验数量和分析的因素,主要在于所采用的科学严谨性,而这在其他文献中是缺失的。
在论文的实验中,我们使用折叠交叉验证——在当前的 NN 比较中很少使用复制实验。 我们还使用合适的文本分类评估指标(Micro 和 Macro F1)。 我们使用统计显着性检验分析结果。 最后,我们比较了所有方法的训练(包括参数化调整)和测试时间成本。论文主要结果基于超过 1500 次实验测量(14 种方法、9 个数据集、两个具有折叠交叉验证的评估指标),为了重现性,我们将所有比较方法的文档化代码以及所有版本和表示形式的预处理和原始数据集(包括折叠划分)提供给社区进行复制和进一步比较 。 我们认为,在我们的实验协议中使用代码,包括我们必须自己实现的方法,以及数据集和适当的文档,对于可重复性和未来 ATC 方法的比较可能非常有用。
Literature Critical Analysis
作者们收集了一组 100 篇出版物,其中包括与 ATC 相关的被引用次数最多和最近(2010-2020 年)的文章,其中包括:非神经文本分类方法、文本表示技术以及基于深度学习和神经网络的方法。我们分析了这些文章,考虑了一些关于他们的实验设置的预先确定的问题,包括(i)对结果进行适当的统计处理(例如,统计显着性检验;置信区间p 值); (ii) 对所提出方法和基线的参数调整过程的描述; (iii) 结果的泛化性(通过对数据集的训练/测试拆分分别进行试验); (iv) 方法的训练效率(时间)分析等。
图 1 显示了选择和分析文献的流程。 第一步包括收集提交给两个来源的文章:(1)Google Scholar; (2) Semantic Scholar。 之后,对于每个来源,文章都会通过其唯一的 URL 进行重复数据删除。 由于 Semantic Scholar 仅返回其自己域内的 URL,因此要使用文章的标题对来自两个来源的文章进行重复数据删除,同一篇文章则选择两个来源之间的引用次数多的。 这一过程产生了 2,506 篇独特的文章。之后,执行预过滤以仅选择与 ATC 和/或 TR 相关的 100 篇被引用次数最多的文章。我们的分析集中在这组前 100 篇被引用次数最多的论文上。
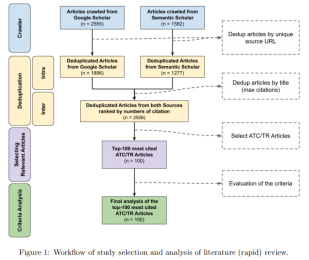
向 Google Scholar 和 Semantic Scholar 搜索引擎提交了一些查询。我们选择这两个搜索引擎是因为 a) 它们的覆盖面广——它们涵盖了来自主要出版商(如 ACM、IEEE、DBLP、AAAI、Elsevier、Springer)的数字图书馆,以及诸如 Arxiv 等文章档案库——并且 b)它们包含关于每篇论文的引用次数。我们根据从两个引擎获得的最大引用数计算的引用数对这组论文进行排序。然后将这些论文分为三类:
• ATC:由主要目标是提出和评估自动文本分类 (ATC) 技术的论文组成,即算法的输入是文本的集合,输出是将每个文本分类为一个或多个类别 .
• 文本表示(TR):由主要目标是提出一种新的文本表示形式(文档或术语)的论文组成,即关注文本表示质量的论文。 该技术的应用可能不一定在 ATC 领域,但也可能在其他文本相关领域,包括翻译和主题建模。
• 其他:不符合上述任何定义的论文。
作为最后的过滤,我们忽略了 OTHER 类别中的论文,因为它们与我们研究的主要目标无关,这给我们留下了 100 篇论文。 剩下的100篇文章中被引用最少的有134次引用,被引用最多的有4832次引用,其中37篇仅为ATC论文,21篇仅为TR论文,42篇论文被认为属于这两个类别。 TR 论文的一个例子是原始的 BERT 论文 [4],它没有专门处理文本分类,但在 ATC 的后续工作中使用了所提出的表示。在深入研究过滤后的相关论文的评估标准之前,我们检查了检索集中神经网络方法的主导地位。 在 100 篇排名靠前的分析论文中,59% 的论文利用了神经网络方法。如果我们考虑更近的时期(2015-2020 年),94% 的论文涵盖了与神经网络或深度学习相关的主题。这表明在最近的 ATC 文献中,神经网络的主题确实完全优于其他方法。
每篇论文都由一名志愿者分析,提出一组非常客观的是/否问题,以确定所采用的实验程序的潜在问题。 志愿者由 11 名计算机科学研究人员组成,他们在 IR 和机器学习方面做出了相关贡献。 其中六人是经验丰富的教授/研究人员,其余五人是硕士或博士。 从事文本分类或相关领域工作的学生。 这些问题涵盖了八个不同的标准,如下所述:
1. 统计检验:“作者是否采用统计显着性检验来比较所提出的策略与实验评估中的基线?” 统计测试对于评估样本(即所考虑的数据集)中分析方法的性能是否可能以一定的信心反映它们在整个人群中的实际性能是必不可少的。 因此,它们是支持任何声称特定方法优于其他方法的关键。 如果没有这样的测试,在样本中观察到的相对表现无论如何都不能外推到总体。
2. 置信区间:“作者是否通过提供置信区间来支持他们的结论?” 除了明确提及用于评估结果的统计测试之外,一些作者可能会选择简单地呈现置信区间(与统计测试隐含相关),并使用它们来支持他们的主张。 这两种策略都可以用于分析结果的统计显着性。
3. 泛化性:“作者是否使用基于交叉验证的实验设计或多次训练/(验证)/测试拆分,重复实验过程不止一次?” 该标准的目的是分析论文是否评估了实验中比较的每种方法的泛化能力。 使用只有一个训练/测试拆分的输入数据集的默认拆分不符合此要求。 重复对于证明多组训练和测试方法的泛化以及避免对“幸运”(单个)分区的任何怀疑是必不可少的——这种分区有利于作者的方法。
4. 效率分析:“作者是否对算法在训练过程中的效率进行了分析,也就是说,他们是否提供了训练所提出算法和基线的执行时间?”
5. TFIDF + SVM:“TFIDF-SVM 是否用作 ATC 基线?”。 最传统且仍然有效的 ATC 方法之一是将 TFIDF 表示与 SVM 分类器相结合,如 [28] 所示。
6. 仅基于准确性的评估度量:“准确性(或诸如错误率或 Micro-F1 等一些变化)是唯一使用的分类有效性度量吗?” 由于类不平衡(即偏度)是 ATC 数据集的共同特征,因此使用基于类的指标(例如 Macro-F1)来衡量 ATC 结果的质量也很重要。
7. 适当调整的基线:“基线参数是否有任何(最少的描述)参数化过程?”
8. 适当调整提议的方法:“提议的算法是否有任何(最少的描述)参数化过程?”
标准 5 和 6 仅适用于 ATC 类别的论文。对于调整标准(7 和 8),我们寻找并考虑使用网格搜索、随机搜索、贝叶斯优化 [29],或提及任何其他经过适当调整的优化过程。 此外,对于这两种情况,如果作者明确给出了方法参数的实验值,而没有指定应用了哪个优化过程,我们假设网格搜索为默认值。 在所有这些情况下,我们假设适当的参数调整。
在分析的前 100 篇相关论文中,绝大多数 (82%) 没有遵循适当的科学协议来呈现具有统计显着性检验的实验结果、置信区间或 p 值的呈现以及具有不同分割的实验的多次重复 数据集。
1. 绝大多数 (82%) 没有报告所提出方法的训练性能。
2. 绝大多数(76%)没有正确呈现基线超参数的调整过程,这带来了两个可能的问题:(i)如果基线的调整确实没有正确执行,则可能存在不公平的比较; (ii) 复现论文中报告的结果存在困难。
3. 绝大多数(96%)的 ATC 论文没有与传统的经过适当调整的 TFIDF-SVM 分类器相比,这是一种强大的调整方法,我们将看到。
4. 绝大多数(87%)的 ATC 论文仅使用准确性作为评估指标,它仅提供了偏斜数据集分类有效性的部分视角。
重要的是要强调,我们的目标不是要使分析文章的结论无效,而是要表明基于许多研究中存在的某些实验问题,某些主张可能过于强烈(例如,声称优于某些 基线或最先进的)。
Methods
我们在五个大型(超过 100,000 个文档)规模的 ATC 数据集 [24] 上评估模型的有效性和成本——AG 新闻 (AGNEWS)、搜狗新闻 (SOGOU)、Yelp 评论 2015 (Yelp 2015)、IMDB 评论 (IMDB)和雅虎! Answers (Yahoo)——以及 ATC 社区已知的四个较小的数据集——分别为 20 个新闻组 (20NG)、WebKB (WebKB)、路透社 (REUT)、ACM 数字图书馆 (ACM)。
我们将数据集分为这两类,以评估这些方法的行为是否因数据集大小而异。这一点很重要,因为一些 ATC 应用程序是小型或中型的(即不包含数十万个文档)。此外,在实际应用中,由于手动标记组成它们的文档通常涉及成本,因此数据集(主要是训练集)倾向于较小。
所使用的数据集已被该领域的大多数工作用作“事实上的”基准进行比较。
表 2 中详述的,我们可以观察到这些数据集的许多方面在大小、域、维度(即特征数量)、类数、偏度水平等方面存在差异,这对数据集不同的算法有很大挑战。
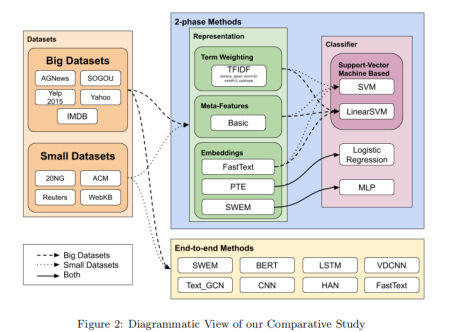
正如我们在图 2 中看到的,此类方法主要分为两大类:2-pass (2P) 方法和端到端 (E2E) 方法。 第一类方法用于预测文档类别的分类器不用于文档表示的构建阶段。使用微平均 F1 (MicF1) 和宏观平均 F1 (MacF1) 评估分类有效性。 微平均Micro-F1 测量总体决策的分类有效性,而 宏平均Macro-F1 测量每个单独类别的分类有效性。较小数据集中的实验是使用 10 倍交叉验证。对于较大的数据集,由于成本,我们使用了5 倍。为了比较我们交叉验证实验的平均结果,我们以 95% 的置信度进行统计显着性检验。为了考虑多重测试,使用弗里德曼 Friedman-Nemenyi-Test 对平均秩和进行多重比较。弗里德曼检验用于比较多种方法对算法进行排序。对于交叉折叠验证中数据集的每一折叠,对于所有数据集的所有折叠,性能最佳的方法排名第一,第二好的方法排名2,依此类推.
论文里方法是根据所有折叠中分配的排名 (R) 的平均值进行比较的。然后对每个方法a的秩求和,每个秩和表示为R i 。统计测量 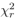 计算为
计算为

其中b是样本数(数据集数×实验中的折叠数)。 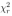 的分布可以被认为是由具有 a-1 自由度的正太分布。 零假设是认为所有方法具有相同的平均排名位置,也就是说,方法之间没有统计差异。这个测试的主要优点是提供了对跨多个数据集的多种方法的比较的总结比较直观,具有统计严谨性。
的分布可以被认为是由具有 a-1 自由度的正太分布。 零假设是认为所有方法具有相同的平均排名位置,也就是说,方法之间没有统计差异。这个测试的主要优点是提供了对跨多个数据集的多种方法的比较的总结比较直观,具有统计严谨性。
算法的参数化过程是通过在每个折叠/数据集的训练数据下使用网格搜索和折叠交叉验证搜索最佳超参数来完成的。 表 3 总结了每个表示的分析参数的值范围及其各自的分类算法。神经网络方法具有大量必须调整的超参数,因此无法对所有超参数使用网格搜索。如果方法最初是在特定数据集上分析的,则保留原始论文中为该数据集报告的相同参数值。 对于需要调整的其他参数,首先通过试错过程选择对方法影响最小的最佳参数,然后通过在训练集中使用嵌套交叉验证进行微调选择其余参数的最佳值。表 4 包含 E2E 方法的所有测试和最终(粗体)参数选择。
论文评估了两台机器上的训练时间成本:基于 CPU 和基于 GPU 的机器。利用加速器的方法都在 GPU 服务器上执行,例如 XLNet、MetaFea-tures、BERT、VDCNN、SWEM、LSTM、HAN 和 CNN,否则使用传统的 CPU 服务器,例如 TFIDF 、FastText、PTE、Text GCN及其各自的分类器。因此,每种方法都使用了最有利的计算平台,使用加速的方法和使用传统服务器的方法具有相同的计算能力。我们估计单个 CPU/GPU 服务器需要几个月的时间(所有数据集和方法的所有折叠需要不间断跑约 112 天)。
Experiments
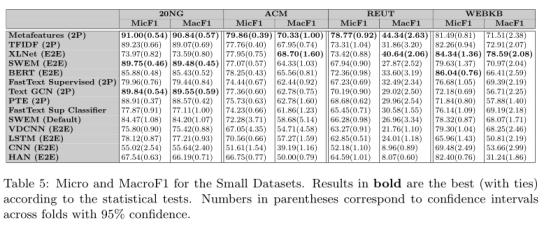
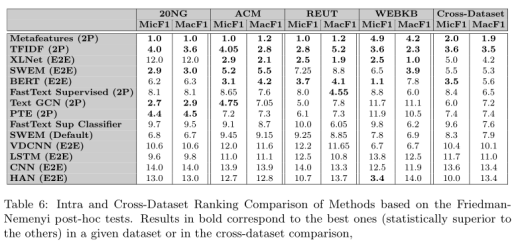
我们从四个较小的数据集开始分析:WebKB、REUT、20NG 和 ACM。 表 5 显示了 14 种对比方法中每种方法的 Micro F1 和 Macro F1 的结果。粗体的结果(具有统计关系)对应于特定指标(MicF1 或 MacF1)的每个给定数据集中的最佳结果。括号中的数字对应于具有 95% 置信度的折叠的置信区间。在表 5 中,这些较小数据集中的最佳整体方法是 MetaFeatures (MF)。 MF 唯一不擅长的数据集是 WebKB,在 WebKB 中:BERT 和 XLNet 在 MicF1 中并列,而 XLNet 在 Macf1 中表现出色。 这在表 6 中的跨数据集比较中得到证实,MF 的平均排名位置为 1.9。表 6 是基于 Friedman-Nemenyi 检验的方法的内部和跨数据集排名比较,考虑了每种方法在相应数据集中的 10 折交叉验证过程的所有折中的平均排名位置。最后两列是每个方法在 Friedman-Nemenyi 过程之后的跨数据集比较排名位置。粗体结果对应于给定数据集或跨数据集比较中的最佳结果(统计上优于其他结果)。
论文实验分析强调了TFIDF 的结果,它在大多数数据集中始终保持第 2-5 位,这使其在整体跨数据集比较中获得第二名。TFIDF 在除了REUT 之外的三个数据集中比最好的神经网络方法 BERT 和 XLNET 更好或一样好。在跨数据集比较中可以更好地看到这一点。根据 Friedman-Nemenyi 事后检验,MF 和 TFIDF 在 MacF1 方面在统计上优于所有其他方法,在 MicF1 中仅与 BERT 并列。作者说这些似乎表明在最近发表的许多作品中使用了较弱或调整不当的baseline,因为比较的数据集广泛被大家使用。
对于小数据及的实验关于NN模型,在 宏平均MacF1 中最好的方法是 XLNet,在 MicF1 中是BERT,与所有其他神经架构(CNN、VDCNN、LSTM 和 HAN)相比具有巨大优势。 这证实了transformer在大多数 NLP 任务(包括 ATC)中优于其他 NN 架构。 最后,关于 2P 与 E2E 架构,如果我们采用 8 个(在 14 个中)排名最高的方法,5 个是 2P 方法 - MF、TFIDF、FastTextSup、TextGCN 和 PTE - 3 个是 E2E 方法(XLNet、BERT 和 SWEM(E2E). 换句话说, 2P方法有一点优势. 提醒一下, 2P方法通常首先构建一个丰富的表示, 它捕获任务的一些重要特征。这证明了在缺乏训练数据的情况下数据工程处理任务的价值。
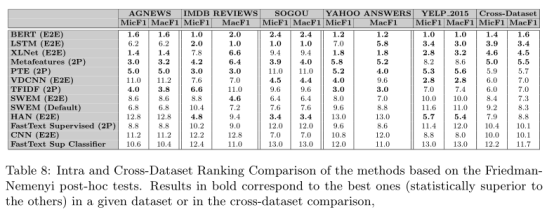
论文在五个大数据集中做了相同的实验,与小数据集不同,E2E 神经方法在大数据集中优于2P方法。 这主要是由于可用于拟合这些架构的所有参数的数据量很大。总体而言,transformer架构获得了最佳效果, BERT 是所有数据集(具有统计联系)中的总体最佳方法,其次是 XLNet 和 LSTM。在大数据集中最好的 2P 方法是还是MF,在大多数数据集中它始终是表现良好的。BERT(最好的 E2E 神经方法)在每个数据集中优于最好的 2P 非神经替代方案的收益,虽然在统计上显着,但在其中一些数据集中可能并不具有表现力 . 例如,(i) BERT 在 AGNews 中的表现仅比 MF 在 Mic 和 MacF1 中高出 1.5%; (ii) 它在搜狗中也与 MF 有联系; (iii) BERT 在雅虎(在 Mic 和 Mac 中)仅以 3.6% 的优势战胜了简单的 TFIDF。 只有在 IMDB 和 Yelp 中,收益实际上是可观的:分别比 PTE(两个数据集中最好的 2P 方法)分别提高了 8.7% 和 11.4%。 并非巧合的是,这是训练信息量最大的两个数据集:Yelp 是第二大数据集,而 IMDB 除了大之外,具有第二高的密度(即每个文档的平均单词数),这些结果在基于 Friedman-Nemenyi 检验的跨数据集排名比较中得到了更好的总结。 最好的方法依次是:BERT、LSTM、XLNet、MF 和 PTE。 事实上,根据 Friedman-Nemenyi 检验,四种排名靠前的方法之间存在统计联系。
CONCLUSION:
论文对最近提出的用于自动文本分类的神经和非神经 2-pass 和端到端方法的成本效益权衡进行了彻底而严格的比较研究。由于 2P 和 E2E 在不同场景下各有优势,我们认为将它们结合起来是推进该领域的绝佳方式。