TripPy: A Triple Copy Strategy for Value Independent Neural Dialog State Tracking
面向任务的对话系统依靠对话状态跟踪(DST)在交互过程中监视用户的目标。多域和开放词汇表的设置使任务相当复杂,需要可扩展的解决方案。在本文中,作者提出了一种新的DST方法,它利用各种复制机制来用值填充槽。作者的模型不需要维护候选值的列表。相反,所有值都是动态地从对话框上下文中提取的。一个槽由三种复制机制中的一种来填充:(1)跨度预测可以直接从用户输入中提取值;(2)可以从跟踪系统的通知操作的系统通知存储器复制一个值;(3)一个值可以从已经包含在对话框状态中的不同槽中复制过来,以解决域内和域间的共引用。作者的方法结合了基于跨度的槽填充方法和内存方法的优点,从而避免了使用值选择列表。作者认为,作者的策略简化了DST任务,同时在各种流行的评估集上实现了最先进的性能,包括MultiWOZ 2.1,其中作者实现了超过55%的联合目标准确性。

在本工作中,作者提出了一种新的值独立的多域DST方法:
1. 除了通过跨度预测和复制直接从用户话语中提取值外,作者的模型还实时创建并维护了两个内存,一个用于系统通知槽,另一个用于之前看到的槽。
2. 系统通知内存通过允许复制系统提到的概念来解决隐式选择问题,例如,提供和推荐的值。
3.DS内存允许使用对话状态中已经存在的值来推断新的值,解决了共引用和值共享问题。
作者称这种方法为TripPy,即三重拷贝策略DST。实验结果表明,作者的模型在测试期间能够很好地处理词汇量不足和罕见值,具有良好的泛化能力。在详细的分析中,作者将仔细查看每个模型的组件,以研究它们的特定角色。
TripPy: Triple Copy Strategy for DST
作者的模型期望以下输入格式来执行对话状态跟踪。设X 为长度为T的对话。U是t轮的用户话语, [公式] 是在用户话语之前的系统话语。模型的任务是(1)确定每个回合中N个域槽对S = { [公式] }的表现,(2)预测每个 [公式] 的值,(3)跟踪对话过程中的对话状态 [公式] ,即t∈[1,T]。
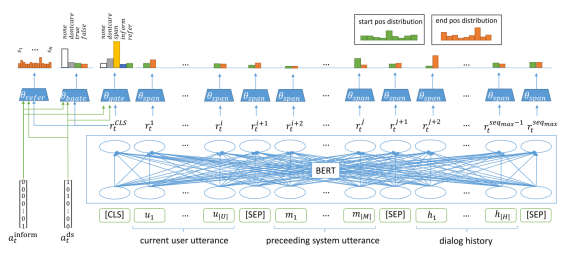
作者采用三份拷贝策略来填补空缺。直观的感觉是,值要么由用户显式地表示,要么由系统表示,并由用户通过确认或拒绝来引用,要么在对话框的前面已经将它们表示为分配给另一个域槽对(共引用)。每一种情况都由三种复制机制中的一种来处理。很明显,插槽不能完全依靠一种特定的复制方法来填充。因此,作者使用槽门,决定在每个回合使用哪一种方法来填补各自的槽。
Slot Gates
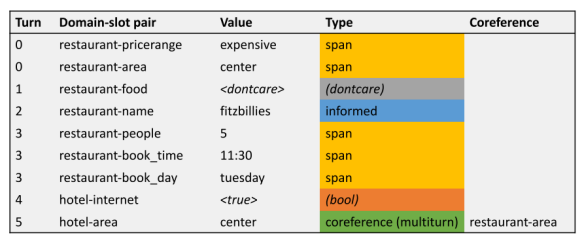
作者的模型为每个域插槽对配备一个插槽门。这确保了多域DST的最大灵活性。在每一回合t,槽门将每个槽 分配给C ={none, dontcare, span, inform, refer}中的一个类,前两个标签表示特殊情况。None表示该槽在此轮中不接受值,而dontcare表示该槽可以接受任何值。剩下的三个标签分别表示模型的一种复制机制。span表示存在一个可以通过span预测提取的值。inform表示用户引用系统在历史中使用过的值. 最后,refer表示用户引用中已经存在的值。
每个槽门是由一个可训练的BERT线性层分类头实现的。布尔槽,即只接受二进制值的槽,是分开处理的。这里,可能的类列表是 C= {none, dontcare, true, false},
Span-based Value Prediction
对于每个要通过跨度预测来填充的槽,一个特定于域槽的跨度预测层接受令牌表示作为整个对话上下文的输入.每个跨度预测器由一个可训练的BERT线性层分类头实现,然后由两个平行的softmax层来预测起始和结束位置。
System Inform Memory for Value Prediction
系统通知内存跟踪对话框第t轮中系统通知的所有槽值。本轮次槽需要由一个 informed value填充,如果用户积极地引用它,但不表示可以使用跨度预测的值。例如,在图1中槽门为域-槽<restaurant,name> 应预测inform。通过将 informed value复制到对话框状态来填充该槽,
DS Memory for Coreference Resolution
对话框越复杂,需要解决共引用的可能性就越大。例如,餐馆的名称很可能是出租车的目的地,但在同一会话中预订出租车时,餐馆可能不会被明确地提及。由于相互参照的形成方式多种多样,同时由于相互参照往往跨越多个回合,因此相互参照的解析具有挑战性。第三种复制机制利用DS作为内存来解析共引用,对于每个槽,一个线性层分类头可以预测包含参考值的槽,或者none表示无参考。
Auxiliary Features
最近一些神经DST的方法利用辅助输入来保存上下文信息。例如,SOM-DST将对话框状态添加到其单回合输入中,作为跨回合保存上下文的一种方法。
通过附加对话历史Ht,作者已经在BERT的输入中包含了上下文信息。除此之外,作者还创建了基于系统通知内存和DS内存的辅助功能。
Experimental Results

Impact of the triple copy mechanism
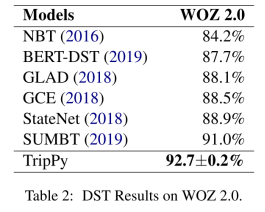
使用作者提出的三重复制机制将性能提高到接近50%,超过TRADE并接近领先的混合方法。特别是槽门的性能受益于此更改。当查看单个类的F1得分时,可以看到span类受益于此区别。需要指出的是,作者的模型处理的所有共引用都不能单独通过跨度预测来解决。这意味着现在可以通过在槽间复制值来避免遗漏,并解决共引用问题。更重要的是,使用对话状态内存来解析共引用有助于在多个回合中检测值,因为在当前回合中被引用的值可能已经被分配给了多轮前的另一槽
Impact of the dialog history
作者发现使用对话历史作为额外的上下文信息对于良好的性能是至关重要的,因为它减少了上下文的不确定性。这清楚地反映在槽门性能的改进上(见图3),这有两个积极的影响。首先,更经常地正确地识别值的存在和类型。特别是特殊值dontcare和布尔槽(接受值true和false)可以从额外的上下文中获益。这只是逻辑上的,因为它们是由槽门使用[CLS]令牌的表示向量预测的。其次,在没有附加上下文信息的情况下,值通常被分配到正确的槽。有了附加的对话历史记录,作者的表现优于DS-DST,并与SOM-DST相匹配,后者达到了先前的最先进的状态。
Conclusion
作者的方法可以处理具有挑战性的DST场景。检测未见值并不会显著影响作者的模型的总体性能。作者提出的模型的信息提取能力植根于基于内存的复制机制,即使在极端情况下也能很好地执行。复制机制不受预定义词汇表的限制,因为内存本身是价值不可知的。进一步改进TripPy,作者希望引入槽独立性,因为目前它的跟踪能力仅限于本体中预定义的槽。