A Novel Global Feature-Oriented Relational Triple Extraction Model based on Table Filling
1. 引言
目前模型有端到端方法以及填表类型的方法。端到端的方法可以很好的解决实体重叠以及一句话中有多个三元组的问题。填表的方法主要的做法是为每个关系维护一张不同的表,表的行和列分别代表一个token,表中的每个小方格代表一个实体对。方法的目标是尽可能的准确填表。目前的问题是填表的方法都关注于单个的token对并且只关注于一些token对的有限的历史。就是指关注于一些很局部的信息。模型还忽略了一些全局的信息。模型忽略了实体对之间的一些信息,还忽略了关系之间的信息。
2. 创新点
模型通过对不同的关系进行建表,然后再通过selfattention提取关系与关系之间的信息,然后再使用融入句子级表示的attention提取实体对之间的关系。通过反复进行这两步以及前馈层来充分挖掘信息。
3. 问题描述
首先是对关系三元组的描述。所有关系三元组的集合可以看作{π = (h, r, t) | h, t ∈ E, r ∈ R},其中h是头实体,t是尾实体,r是这两个实体之间的关系。然后我们需要对文中的所有句子进行一个定义。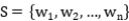 代表一个句子,其中
代表一个句子,其中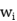 是指第i个词。模型的目标是从句子S中识别出所有存在的三元组π。
是指第i个词。模型的目标是从句子S中识别出所有存在的三元组π。
4. 方法
利用BERT的得到token representation,然后分别经过两个FFN得到subject和object的表征,如此我们有三个feature,分别是最初始的global feature,还有后续得到的sub和obj的。将上述sub和obj的两个隐藏层表征作为输入,建立一个n*n*h的表格。(n代表句子的长度,h为隐藏层维度768)
该模块分三步走:第一步是maxpooling操作将上述TFr转换成subject-related table feature (TFs)和TFo;第二步使用多头注意力机制,将2.2encoder得到的global feature加入进来作为K、V,以此得到全局信息;第三步转换回sub_feature和obj_feature,表现形式如encoder所得。同时,该模块会经过多次迭代,从而进行丰富的交互。(迭代次数自定,随数据集变化,源码量级为3-5次)解码我们的table,给各框打上标签,解码得到三元组。
5. 实验结果
Argue:本文最后的解码模块,是根据头标签找尾标签寻得三元组,但是这样无法解决overlapping问题(可能有冗余的尾标签),对此,作者提出了尾标签重新寻找头标签的方法,但是该种方法,可能影响模型的学习过程(解码形式不一致),影响模型性能。
第二方面是,该方法仅可补救尾标签冗余的问题,对于头标签冗余,本文并未提及也未举例解决方法,这是该方法存在的另一个问题。