FedED: Federated Learning via Ensemble Distillation for Medical Relation Extraction
与其他领域不同,医学文本不可避免地伴随着私人信息,因此共享或复制这些文本受到严格限制。然而,训练医学关系抽取模型需要收集这些隐私敏感文本并将它们存储在一台机器上,这与隐私保护存在冲突。本文提出了一种基于联邦学习的保护隐私的医学关系提取模型,该模型能够在不共享或交换单个私有数据的情况下训练一个中心模型。虽然联邦学习在隐私保护方面有明显的优势,但它存在通信瓶颈,这主要是由于需要上传繁琐的局部参数。为了克服这一瓶颈,我们利用了一种基于知识蒸馏的策略。该策略利用集成局部模型上传的预测来训练中心模型,而不需要上传局部参数。在三个公开的医学关系抽取数据集上的实验证明了该方法的有效性。
1. 引言
联邦学习定义,联邦学习是一种机器学习范式,可以在一个中心服务器的协调下让多个客户端互相合作,即便在数据分散在客户端的情况下也可以得到一个完整的机器学习模型。这里的客户端不同的任务中可以指代不同的事物。比如,在手机输入法预测下一个词语的任务中,一般需要使用语言模型来预测下一个词语,这个任务中客户端就是很多部用户的手机;再比如在医疗领域,使用图像识别分割等深度学习技术对病例进行诊断需要大量的数据支持,而这些数据通常涉及大量用户隐私的,因此在这种情况下需要一种安全的方法来协同多个医疗机构的数据进行训练,在这个情况下,客户端就是一家家的医疗机构。
联邦学习是如何保护用户隐私的呢?在联邦学习中,各个客户端通过中心服务器进行协调,在各个客户端和中心服务器彼此信任的情况下(无恶意猜测和攻击)可以达到很理想的隐私保护要求,中心服务器只负责协调、聚合等功能,模型还是根据客户端本地的数据进行训练,允许一定程度上的个性化训练方式。联邦学习的保护隐私是建立在中心模型可信、且没有恶意猜测和攻击、并且数据据传输过程也安全的情况下。
2. 论文方法
(1)关系抽取方法
论文对于生物医学关系抽取模型,采用如下模型结构,文本语义编码部分采用BERT模型,为了突出实体提及,用四个保留词块<e1>、<\e1>、<e2>、<\e2>来扩充序列。
取CLS token对应的向量作为句子表示。实体提及的表示由实体中的每个token的最后一个隐层的表示相加得到。将句子表示和实体表示进行拼接输入到全连接层,进行关系分类。
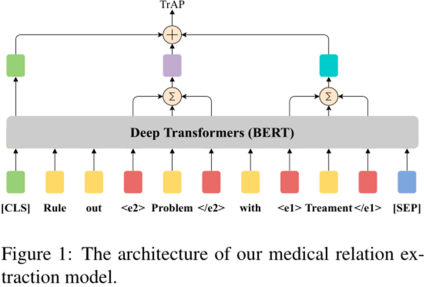
图1 关系抽取模型
(2)联邦学习方法
本文提出了一种基于融合蒸馏(Ensemble Distillation)的联邦学习方案FEDED,解决存在数据隐私要求情形下的医学关系抽取问题。该策略利用上传的集合局部模型预测结果来训练central model,而不需要上传局部模型整体参数。其算法流程如图2所示。
以往联邦学习方法的缺陷:通信瓶颈,本地平台和中央服务器之间需要频繁通信以上传和下载模型参数。本文方法:基于融合蒸馏(Ensemble Distillation)的迁移学习方案,不需要上传局部参数。
local model 与 central model使用相同的网络结构。local model使用本地数据进行训练(这里模拟的场景是各个医院) 。central model 使用验证集Dv进行单独训练(可以理解为在一个可信任的第三方机构进行训练,Dv是一个单独的小体量数据集)。
每个local model 使用本地数据训练之后,在验证集Dv上给出各自的预测结果,这些local model 即为teacher model。基于各个local model的预测结果进行融合,使用central model 进行学习,central model 即为student model。本地模型使用自己的数据集训练,然后访问中央服务器中的数据集Dv,对其进行预测,并将预测的标签分布上传到中央服务器。这种方式的好处就是通信传输的参数量非常少。
损失函数一是蒸馏loss,使用的是teacher model融合预测结果与student model 预测结果的KL散度。二是分类交叉熵,将两个loss累加作为整体的loss。

图2 FEDED算法流程
3. 研究团队与作者介绍
论文的研究团队:National Laboratory of Pattern Recognition, Institute of Automation,
Chinese Academy of Sciences
作者邮箱:
{dianbo.sui, yubo.chen, jzhao}@nlpr.ia.ac.cn,
jamaths.h@163.com {xieyuantao2, sunweijian}@huawei.com
4. 数据集以及评价指标
论文在i2b2、GAD、EU-ADR三个数据集上进行了实验,三个数据集规模、实体数量以及关系数量如图3所示。
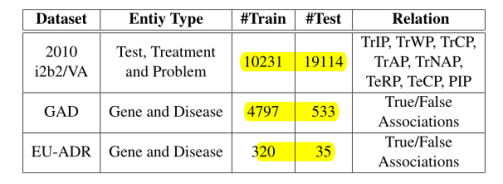
图3 数据集统计情况
实验使用的评价指标为精确率(P),召回率(R),F1值(F1)。实验结果如图4所示。
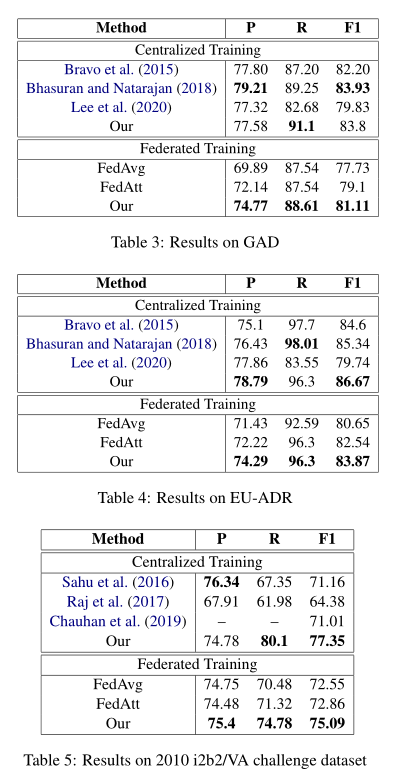
图4 性能对比
实验结果显示,论文所提方法在三个数据集上均取得了目前最好的结果。
参考文献
[1] Zexuan Zhong and Danqi Chen. 2020. A frustratingly easy approach for joint entity and relation extraction.arXiv preprint arXiv:2010.12812.
[2] Jue Wang and Wei Lu. 2020.Two are better than one: Joint entity and relation extraction with table-sequence encoders. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 1706–1721, Online. Association for Computational Linguistics.
[3] Suncong Zheng, Feng Wang, Hongyun Bao, Yuexing Hao, Peng Zhou, and Bo Xu. 2017. Joint extraction of entities and relations based on a novel tagging scheme.arXiv preprint arXiv:1706.05075.