我主讲的这篇论文是医疗对话生成领域发表在SIGIR 2021的一篇论文。
1. 引言
医疗对话生成任务是为了在问诊场景下帮助医生提供诊断和治疗建议。在医疗对话中,有两个特征与生成回复相关:患者的状态和医生的行为。然而在医疗场景中,由于高成本和隐私要求,很难做到大规模的人工标注。所以目前的医疗对话生成方法通常没有明确地考虑患者的状态和医生的行为,而是仅仅关注于给定对话上下文来生成回复,而这篇论文在生成回复的基础上还进行了患者状态跟踪和医生策略学习,这也是这篇论文的创新点。如图1是一个医疗对话的例子。

图1 一个医疗对话的例子
医疗对话生成面临着一系列的挑战:需要大量人工标注对话状态;现有的方法对领域的语义理解有限,难以生成有知识的回复;需要可解释性来帮助患者和医生理解系统为什么会产生这样的回复,这一点被大多数的研究所忽略。为了解决这些挑战,本文提出了VRBot,对医疗回复生成进行变分推理。VRBot包含一个患者状态跟踪器和一个医生策略网络,将患者状态和医生行为都看作潜在变量进行学习,而不是人工标注的那种可以观察到的变量。医生策略网络包括医生行为分类器,以及上下文推理检测器和图推理检测器,分别通过上下文和医学知识图来推断行为。由于VRBot有患者状态、医生行为和多跳推理的显式序列,所以有着高度的可解释性。
本文还构建了一个知识感知的医疗对话数据集,包含6万多个医疗对话和5682个实体。数据集还带有大规模的外部医疗知识,以三元组的形式存在,是从中文医学知识图谱平台CMeKG爬取的。本文还使用另外两个基准数据集分别是MedDialog和MedDG。MedDialog有数百万个对话,但大多数对话都很短,本文过滤掉了少于三轮的对话。MedDG提供了半自动标注的状态和行为。如表1是数据集的统计信息。An下的对号表示只有MedDG数据集提供标注。
表1 数据集统计信息 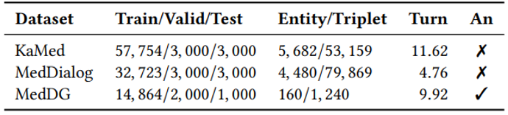
2. 方法
一场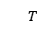 轮的对话表示为
轮的对话表示为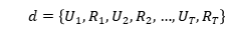 ,
,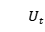 表示患者的话,
表示患者的话,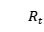 表示医生的回复。
表示医生的回复。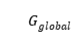 表示全局知识图,通过连接所有有重叠实体的三元组构成。模型的参数为
表示全局知识图,通过连接所有有重叠实体的三元组构成。模型的参数为 。模型的目标是最大化在
。模型的目标是最大化在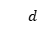 上的概率分布:
上的概率分布:
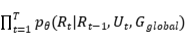 (1)
(1)
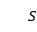 表示状态,
表示状态,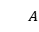 表示医生的行为,用一段文本表示。由于表示状态和行为的文本也可以对回复的生成有帮助,因此本文将医疗对话生成分解为连续的三个步骤,分别是生成状态文本,生成行为文本,生成回复。生成回复是在确定了行为和状态的基础上进行的。如图2是模型在
表示医生的行为,用一段文本表示。由于表示状态和行为的文本也可以对回复的生成有帮助,因此本文将医疗对话生成分解为连续的三个步骤,分别是生成状态文本,生成行为文本,生成回复。生成回复是在确定了行为和状态的基础上进行的。如图2是模型在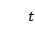 时刻的情况。可以看到,
时刻的情况。可以看到,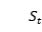 依赖于
依赖于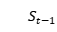 ,
, 和。
和。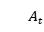 依赖于,,和。
依赖于,,和。
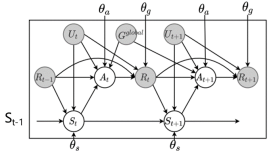
图2 模型在t时刻的情况
于是模型的目标可以改写为:
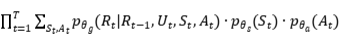 (2)
(2)
其中,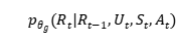 是使用回复生成器得到的,
是使用回复生成器得到的,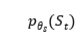 和
和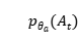 分别是通过患者状态跟踪器和医生策略网络这两个先验网络得到的,以如下方式计算:
分别是通过患者状态跟踪器和医生策略网络这两个先验网络得到的,以如下方式计算:
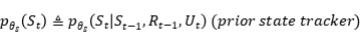
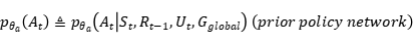 (3)
(3)
本文用后验分布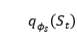 和
和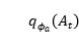 来近似先验分布。这就是变分推理的思想,用简单的分布来近似复杂的分布。后验分布用两个推理网络来表示,分别是推理状态跟踪器和推理策略网络。为了度量分布之间的距离,本文采用KL散度,希望后验分布与先验分布之间的距离越小越好。
来近似先验分布。这就是变分推理的思想,用简单的分布来近似复杂的分布。后验分布用两个推理网络来表示,分别是推理状态跟踪器和推理策略网络。为了度量分布之间的距离,本文采用KL散度,希望后验分布与先验分布之间的距离越小越好。
如图3是VRBot的模型图,包括上下文编码器,患者状态跟踪器,医生策略网络和回复生成器。
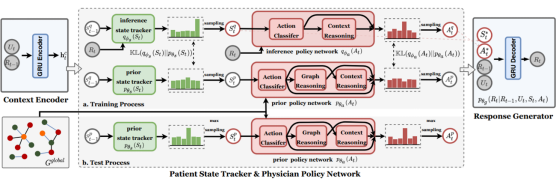
图3 VRBot的模型图
本文提出了一个坍塌推理的训练过程。由于行为网络很容易被状态网络的错误结果误导,所以提出了一个2阶段的训练过程,第一步先优化后验状态跟踪器和先验状态跟踪器的KL散度;第二步优化后验状态跟踪器和先验状态跟踪器的KL散度以及后验策略网络和先验策略网络的KL散度。过程如图4所示。
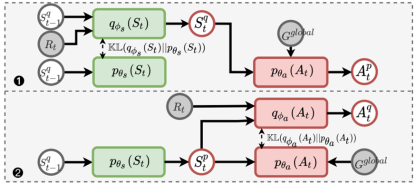
图4 2阶段训练过程
3. 实验
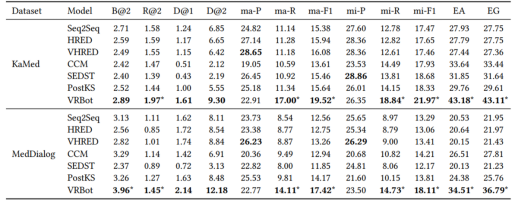
模型在KaMed和MedDialog数据集上的实验结果如表2所示。可以看出,VRBot在大部分评价指标上都明显优于所有baseline。
表2 在KaMed和MedDialog数据集上的实验结果
4. 结论
本文主要研究基于大规模无标记语料库的医疗对话生成问题。本文提出了名为VRBot的生成模型,使用隐变量来模拟潜在的病人状态和医生行为,并提出了一个两阶段的训练技巧。在医疗对话数据集上的大量实验表明,VRBot在无监督和半监督学习上都取得了最先进的性能。
代码和数据集的地址:https://github.com/lddsdu/VRBot
参考文献
[1] Li D, Ren Z, Ren P, et al. Semi-supervised variational reasoning for medical dialogue generation[C]//Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval. 2021: 544-554.
[2] Chen S, Ju Z, Dong X, et al. MedDialog: a large-scale medical dialogue dataset[C]//Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP). 2020: 9241-9250.
[3] Liu W, Tang J, Qin J, et al. MedDG: A large-scale medical consultation dataset for building medical dialogue system[J]. arXiv preprint arXiv:2010.07497, 2020.