会议:NAACL2019
简介:当回答自然语言问题时,不同的问题组件和KB方面发挥着不同的作用。然而,大多数现有的嵌入式,知识库问题的解决方法KBQA的回答忽略了微妙的相互关系在问题和知识库之间(例如,实体类型,关系路径和上下文)。在这项工作中,我们直接建模相互作用的双向流动问题和知识库通过一个新颖的双向注意力记忆网络,简称BAMnet。不需要外部资源只有非常少的手工制作的功能WebQuestions基准,我们的方法显著优于现有的信息检索基于方法,并与使用(手工制作的)语义解析为基础的方法保持竞争。此外,因为我们使用注意力机制,我们的方法与其他基线相比提供了更好的可解释性。
一、介绍:
1.目前的一些研究缺乏了对问题本身和KB之间的关系研究,这个关系包括entity types , relation paths, context,所以本文提出了BAMnet模型,最终的结果要好于IR模型,模型包含着众多的attention,提供了可解释性。
目前KBQA的主流技术SP和IR,基于语义解析的方法会将q 解析并生成一个中间解析式 lq,执行该解析式以获得问题的答案,基于信息检索 (IR-based) 的方法将会从整个知识图谱中抽取一个子图 GqGq,随后基于子图进行问题的推理,并选取子图中排序较高的实体作为答案。
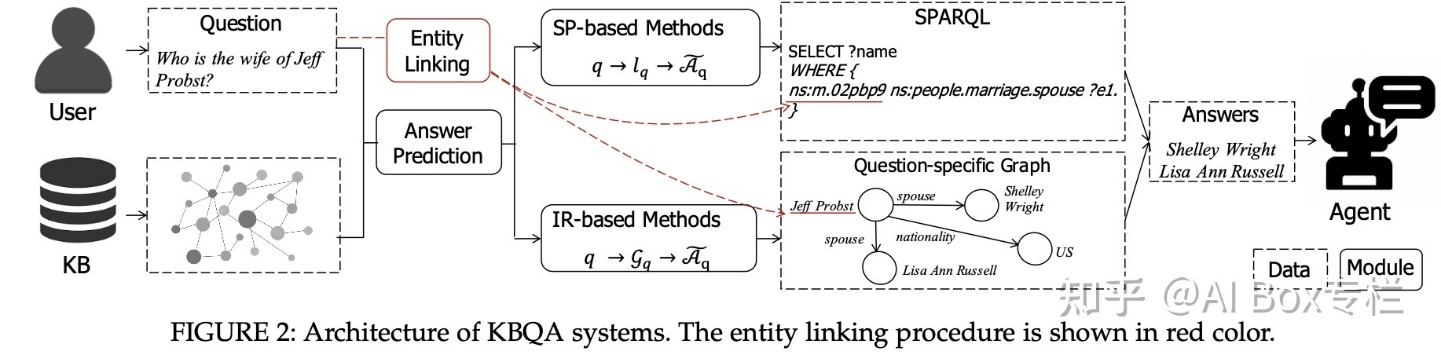
SP技术的简要介绍:

IR技术的简要介绍:

我们所追求的是给定一个自然语言描述的问题,KBQA能够自动地从KBQA的底层找出答案,并且提供一种自然的直接的方式来获取知识库底层资源。
KBQA面临的两个核心挑战,一个是复杂问题理解难:如何更恰当地通过知识图建模并理解用户复杂问题,并增强方法的可解释性;另一个是模型推理能力弱:如何减少对于人工定义模板的依赖,训练具备推理能力、泛化性强的 KBQA 深度模型;所以本文提出了一种双向注意力记忆网络,他能抓住问题和KB之间的多种交互关系,并且把它存储在可寻址的记忆单元中。本文中比较值得一体的特点是一个双层的双向注意网络。主要注意网络的目的是根据知识库关注问题的重要部分,并根据问题关注重要的知识库方面。二次注意网络旨在通过进一步利用双向注意来增强问题和知识库表示。
与本文相似的方式是来自机器阅读理解的方法,MACHINE COMPREHENSION USING MATCH-LSTMAND ANSWER POINTER,这篇文章采用了关注两段文本之间的关系的方法,本文借鉴了这一思想就是对文本和KB进行建模,本文设计了端到端的神经结构。
Ⅰ.BAMnet 模型
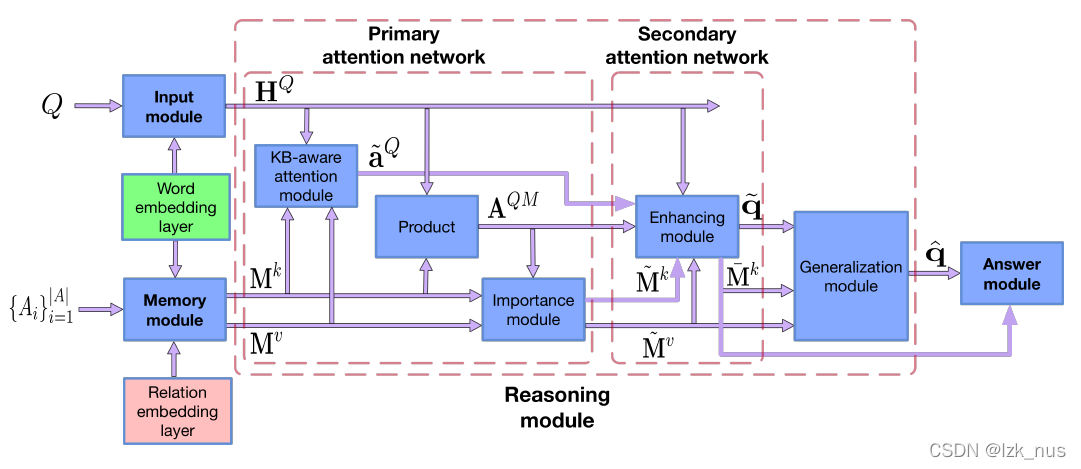
模型共分为四个模块:问题的输入模块Input Module:对问题输入embedding;Memory Module:对KB信息进行embedding;Reasoning Module:推理部分,attention层的主要战场;Answer Module:答案输出模块。
输入模块:首先对问题 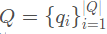 使用BiLSTM进行编码,
使用BiLSTM进行编码,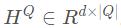 。
。
记忆模块:根据问题的topic word在KB中选择距离 h跳作为候选答案,使用BiLSTM编码,得到候选答案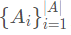 。答案要从三个角度来考虑,分别是type,path,context,并且把他们分别表示成
。答案要从三个角度来考虑,分别是type,path,context,并且把他们分别表示成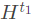 ,
,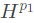
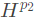 ,
,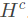 。我们通过f函数进行映射,得到
。我们通过f函数进行映射,得到

然后我们把三个角度的K,V分解拼接在一起得到,
Reasoning 模块:KB-aware attention Module:学习问题中哪些词重要;Importance Module:学习KB中哪些信息重要;Enhancing Module双向的attention进行增强;Generalization Module :一些残差连接和BN层。KB-aware Attention Module是为了探究问题中哪些词重要,
我们首先对问题进行self-attention操作,通过上面的公式得到了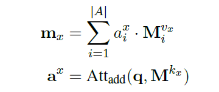
最后得到了向量q,然后我们为向量q和答案矩阵进行相似化操作,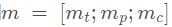
 ,最后使用最大池化,归一化得到权重
,最后使用最大池化,归一化得到权重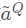 。
。
Importance Module 是为了探究KB中哪些信息重要, ,
,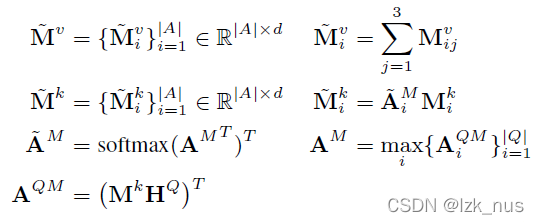 输出了M矩阵里面包含了KB重要信息。
输出了M矩阵里面包含了KB重要信息。
Enhancing moduel,目的是为了加强前面的两个加强模块的输出,我们对双向attention的建模,计算question-to-KB attention和KB-to-question attention来增强问题矩阵和memory矩阵。使用 矩阵,对三个答案特征进行max pooling,,使用softmax,
矩阵,对三个答案特征进行max pooling,,使用softmax,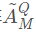 ,
,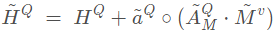
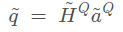 KB-to-question同理,
KB-to-question同理, ,增强效果的小trick,再次更新问题向量
,增强效果的小trick,再次更新问题向量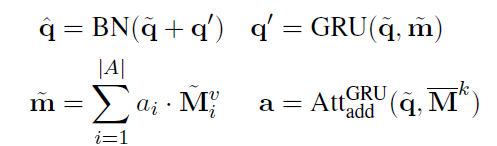 。
。
答案模块:问题向量 KB的memory向量
KB的memory向量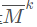 ,点乘计算相似得分
,点乘计算相似得分
按照大小排序。
二、实验
1. 数据集
Freebase KB:It has 41M non-numericentities, 19K properties, and 596M assertions.
WebQuestions:This dataset contains 3,778 training examples and 2,032 test
examples.训练验证比例: 8:2。
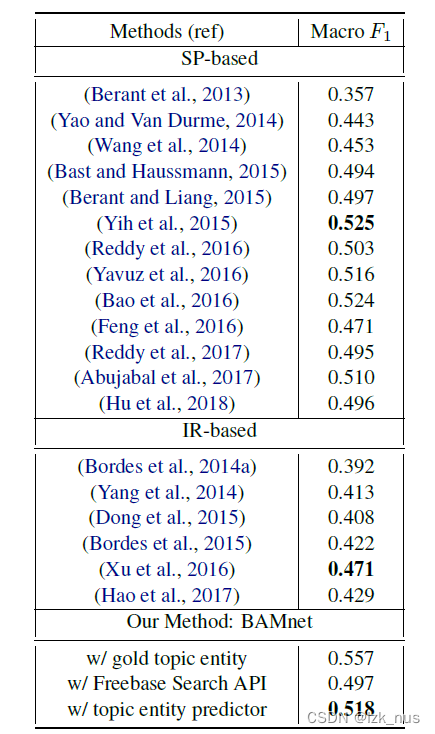

消融实验表明每一块的模块都是有自己的作用的,当然有些模块的作用大,有些模块的作用比较小。

举一个小例子。
错误分析:检查局限性,随机抽样了100个问题,表现很差(每个问题F1得分小于0.6),1. 33%的错误是由于答案的标签问题这包括不完整和错误的标签,以及可选的正确答案。,2.约束是错误的另一个来源(11%),其中时间约束占大多数。3.类型错误(13%),充分利用答案类型信息,会产生比较多的答案。词汇空缺是错误的另一个来源(5%)。4.错误的其他来源(38%)包括主题实体预测错误,问题歧义,不完整的答案和其他杂项错误。
方法明显优于以往的基于IR的方法,
同时与手工制作的基于sp的方法保持竞争力。探索更复杂类型约束建模的有效方法