会议:SIGIR2020
简介:基于会话的流推荐(SSR)是一项具有挑战性的任务,要求推荐系统在流场景中进行基于会话的推荐(SR)。在本文中,我们为SSR问题提出了一个带有 Wasserstein Reservoir 的全局属性的图神经网络(GAG)模型。一方面,当一个新的会话到来时,一个具有全局属性的会话图,是基于当前会话及其相关用户构建的,因此,GAG可以同时考虑全局属性和当前会话,以学习更全面的会话和用户的表征,从而更好地进行推荐。另一方面,为了符合流会话的设定,我们提出了一个Wasserstein Reservoir,以帮助保存代表性的历史数据。两个真实数据集上的大量实验表明,GAG模型优于最先进的方法。一、介绍:
1.会话推荐
会话(session):通常是指用户打开网站开始一系列交互行为(点击、收藏、搜索)直到退出网站的一段时间。
任务目标:根据user之前的交互行为预测用户下一个交互行为。

2.流推荐
流的设定:在线学习场景。数据以连续、高速、大量的数据流的形式(data stream)不断到达。要求模型不再是静态的,而是根据最新数据在线更新。

3.流会话推荐
流会话推荐是会话推荐和流推荐的交叉方向,也可以说是将会话推荐拓展到流的设定下。主要解决的问题有两点:会话推荐部分,如何离线训练?流推荐部分,如何在线更新?

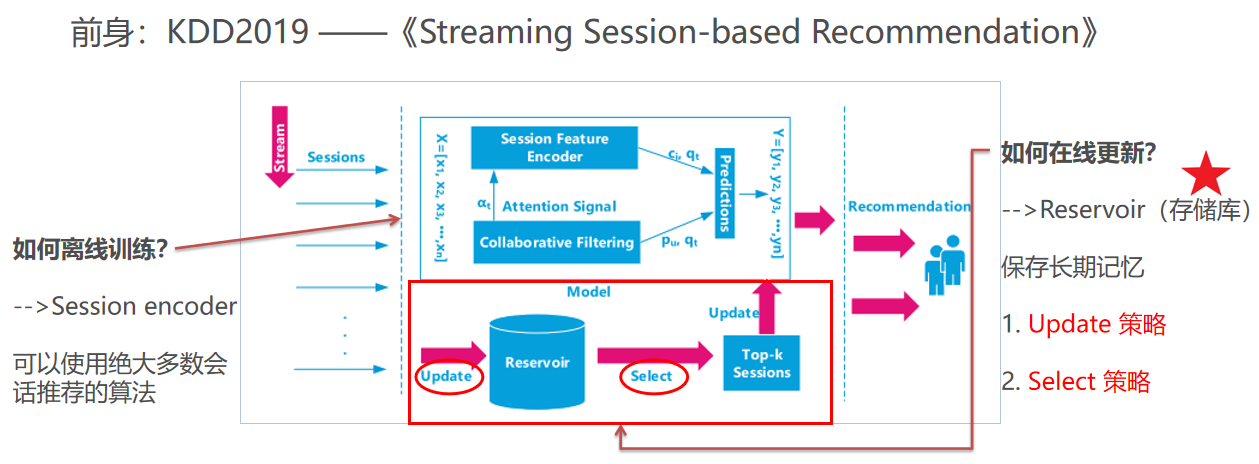
4.与前身:KDD2019 ——《Streaming Session-based Recommendation》
主讲论文的前身是KDD2019的一篇论文,产自同一实验室。整个模型框架如下,很清晰地可以看出分为两大部分,session encoder部分——解决离线训练问题;reservoir部分——解决在线更新问题。而在线更新问题又可以细分成:1)如何选择update策略;2)如何选择select策略。
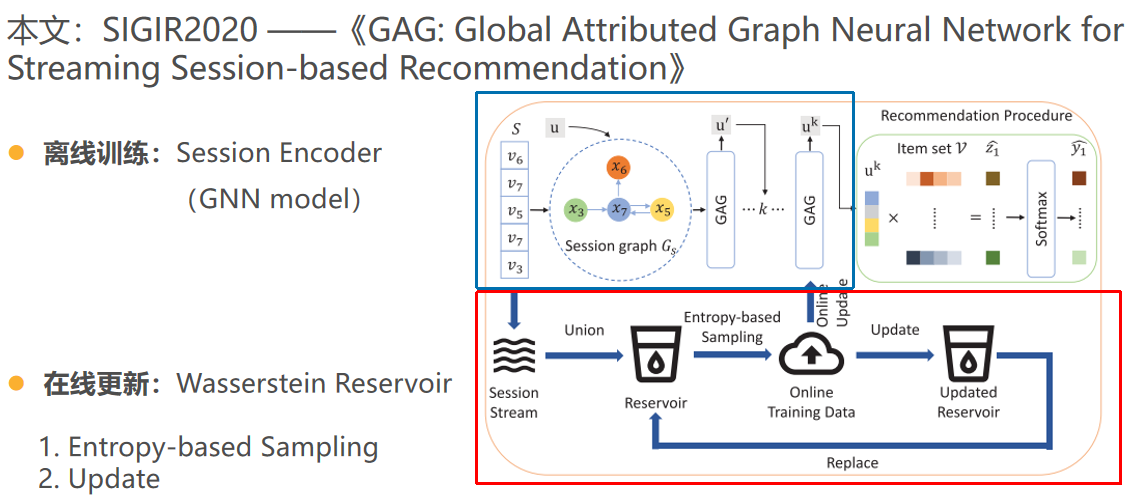
本文的框架与之前非常类似,只不过session encoder采用了GNN model;reservoir部分采用了wasserstein reservoir,采样策略选择了Entropy-based Sampling,更新策略选择了随机采样策略。
二、模型
参数表

Ⅰ.GAG 模型
本文提出Global attributed graph neural network,主要创新点:在两个阶段把用户信息作为全局属性加入会话图,分别是input阶段和注意力机制阶段。
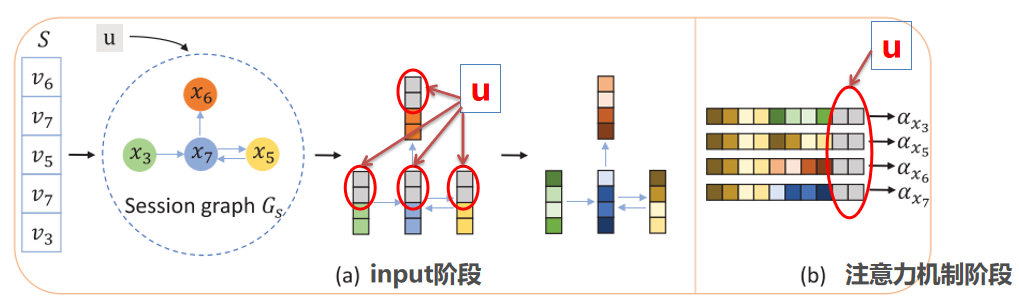
1. 构建会话图
按照序列顺序,依次连接序列中的item构成会话图。其中,图的节点:每个node代表item。图的边边:加权边,权重基于边出现的频率计算。图:一个图代表一个会话。
2. 图中的消息传递
本文提出先逐边再逐点的双向更新方法。
1) 逐边更新
逐边更新,为了得到边的双向表征。因为是有向图,所以在两个方向上都计算,一个节点既作为sender,也作为receiver。边特征在这里指的是边的权值,是固定值,不是dense vector,不会更新。所以边信息只用来更新节点特征和全局特征。
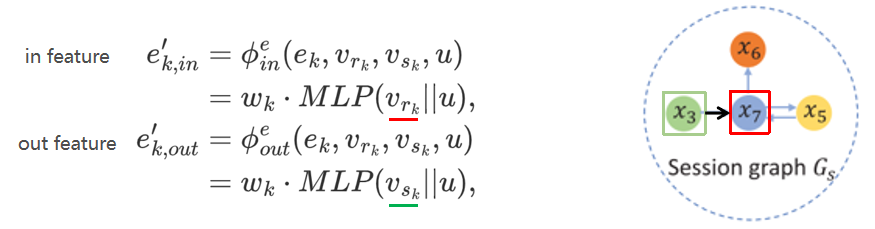
2) 逐点更新
逐点更新,为了得到节点的双向表征。逐点更新是基于逐边更新的结果的。节点的双向特征是由,标准化后的所有相连边的特征之和。
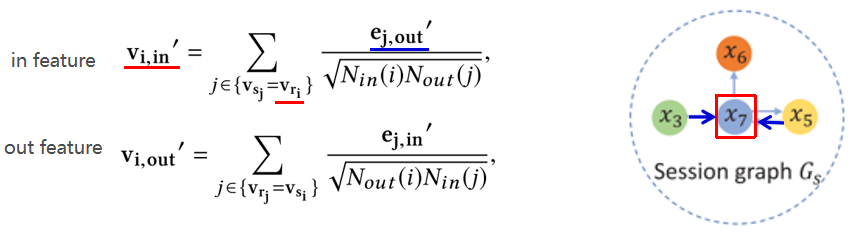
3) 得到节点表征
将节点的双向信息融合,得到节点表征。
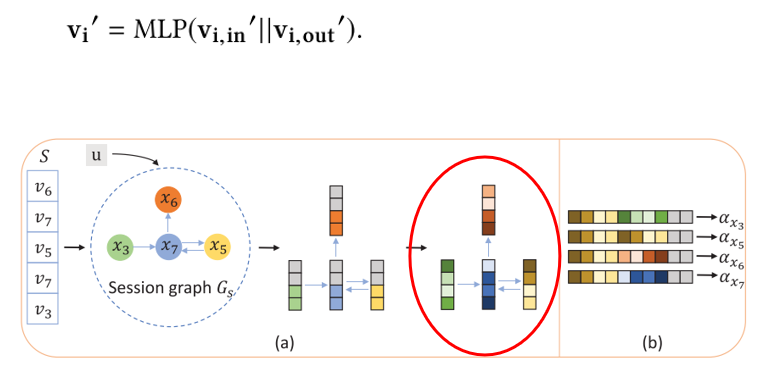
4) 得到会话表征
这里借鉴了会话推荐中的经验:序列中最后一个item,对表示用户当前兴趣很重要。所以用最后一个item与序列中所有item做self-attention操作得到权重,最后再求加权和得到会话表征。

5) 预测/推荐
用会话表征与所有item计算内积,再过softmax得到推荐得分。

Ⅱ. Wasserstein Reservoir
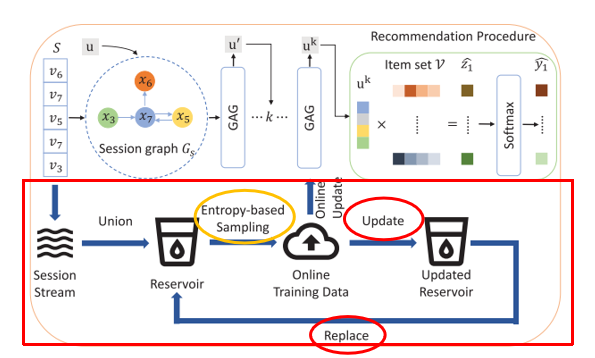
通过3W的形式介绍这一部分。
What?基于随机采样的 reservoir 技术,是流数据库管理系统中非常常见的技术。
Why?将离线模型拓展到流设定下,面对高速、连续、大量的数据流,推荐系统需要有效的技术来保存模型长期记忆,并且适应最新的偏好。
How?怎样选取数据集更新模型?如何更新 Reservoir?这将是讨论的重点。
1. 如何更新 Reservoir
基于随机采样的 reservoir 技术,是流数据库管理系统中非常常见的技术。存储库用 C 表示,始终存储 |C| 条数据,t 代表时间戳,每来一条数据加一。当 t <= |C| 时,数据全部保留;当 t > |C| 时, 概率替换掉存储库中任意一条。
概率替换掉存储库中任意一条。
理论依据:被证明等价于对当前数据集随机采样,并且可以保持模型的long-term memory。

2. 怎样选取数据集更新模型
1) 传统在线学习方法:直接用新数据作为训练集。×
不采用的原因: 忽视了模型的长期记忆 。
2) 直接使用随机采样完的 Reservoir 作为训练集。×
不采用的原因: a) 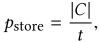 随时间步增加,概率变低,容易忽视最近的数据; b) 存储库中大部分都是long-term数据,模型早就学得很好了,所以用它来训练对模型更新帮助不大。
随时间步增加,概率变低,容易忽视最近的数据; b) 存储库中大部分都是long-term数据,模型早就学得很好了,所以用它来训练对模型更新帮助不大。
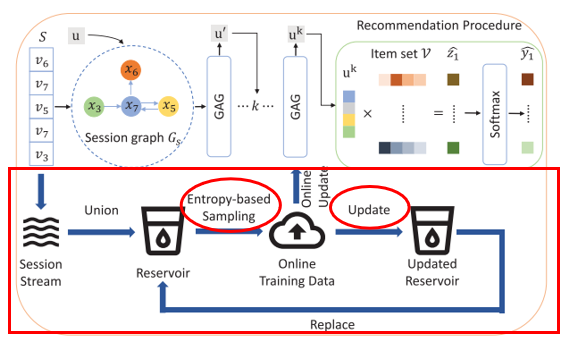
3. 解决方案:√
选择对模型更新帮助最大的数据的来更新模型。对模型更新的帮助 —— 信息量 —— 用Wasserstein距离衡量。
3.1 什么是信息量 informativeness
作者基于这样一个假设:如果当前模型在最新数据上预测结果不好,可能意味着“用户兴趣转移”or“遇到了当前模型无法捕捉的转换模式”。这样的数据称之为“有信息量的数据”,对模型更新意义更大。而一条会话的信息量定义为:数据真实标签 与模型预测分布
与模型预测分布 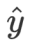 之间的距离。
之间的距离。
3.2 度量分布之间距离的算法

在推荐任务中,真实分布是one-hot向量,只有真实标签处为1。
KL散度,也称交叉熵、相对熵。不选择KL散度的原因是:在推荐任务中,公式简化为: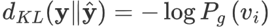 ,实际上只衡量了真实标签处的差异,没有考虑整个分布之间的差异。而且KL散度本身就是非对称性函数:
,实际上只衡量了真实标签处的差异,没有考虑整个分布之间的差异。而且KL散度本身就是非对称性函数: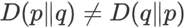 ,用它作为一个真正的距离度量可能不是很合适。
,用它作为一个真正的距离度量可能不是很合适。
不选择全变分距离的原因是:在推荐任务中,公式简化为: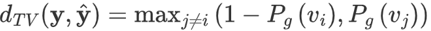 ,这个结果要么只衡量了真实标签以外的差异,要么只衡量了真实标签。
,这个结果要么只衡量了真实标签以外的差异,要么只衡量了真实标签。
而 Wasserstein 距离可以衡量两个分布之间的差异。
3.3 Wasserstein距离
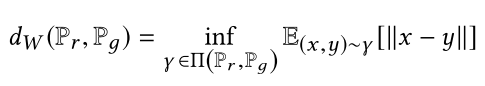
简单解释一下这个公式的含义,首先Wasserstein 距离是人为定义的对于两个分布 Pr 和 Pg 间差异的度量。
∏(Pr, Pg)代表对于 (x,y) 的边缘分布为 Pr 和 Pg 的联合分布的集合。
我们从这个集合里面任选一个联合分布 r ,对应这个 r 联合分布,求出 (x,y) 服从 r 这个分布时,x,y两个点对于 ||x-y|| 的期望值。
对于联合分布集合里面所有的联合分布,我们都能求出这样一个期望值,其中最小的那个期望值就是我们要求的wasserstein距离了。
直观地说,某条数据的预测分布和真实标签分布的Wasserstein距离越大,其包含越多信息。
因此,越应该选择它们来更新模型。最后采样的概率为: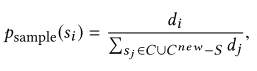
三、实验
1. 数据集
为了模拟流数据,数据集的划分方法如下:

2. 对比实验结果

四、总结
作者将SSRM的encoder部分换成了图神经网络模型,并且沿用了NARM、SRGNN等采用的注意力机制,将用户信息作为全局信息融入GNN模型中,解决了保存用户长期兴趣的问题;改进了reservior的采样策略:计算推荐结果和真实交互的Wasserstein距离作为信息量指标,从而计算采样概率,改进采样策略。这个交叉方向可以深入研究。