简介:在做文本分类任务时,基本都是利用文本的字或词信息,或者再加一些额外的知识信息,但并没有有效的利用文本中的一些统计信息,如词的频率,词在各个label的分布信息等;根据这样的想法,作者提出Adaptive Gate Network (AGN)模型,能将文本的统计信息与文本的特征信息通过控制门机制很好的融合起来,提高文本分类的效果。
1. 引言
现在流行的大规模预训练模型以及CNN,RNN等的语义信息还不够丰富。曾有学者专门研究,通过加入额外的知识库信息,如加一些特征,情感词典,或一些实体知识库,来增加语义信息。在2013年,2016年,2019年都有。但是这些研究都是很早之前,我大概看了一下,关于LSTM的,没有关于现在主流的预训练模型的。所以作者以此为出发点,想能不能把这种东西加到当今流行的模型中。
为此它做了一些调查,目前已有的最具代表性的把统计信息融合进来的是TFIDF,但是它是词袋模型,原理就是只是提取出来关键词做为词典啊或是什么的,没有考虑到词的位置信息,所以它的特征表达远远不如当下的深度学习的。
作者的创新点是在于两点,和之前的分类模型相比,作者是铜鼓融合自适应机制加入额外的统计信息。和当今附加知识库的分类器相比,作者注意了引入外部信息的重要性和必要性,如果不注意的话,这会导致给分类器加入额外的噪音。
本篇论文的主要贡献是,它是第一个在文本分类中,给深度网络加入语料库的统计信息。并且提出了一个自适应门的网络来以低置信度把统计信息合并到语义信息中。还有作者做了很多实验来证明它提出的网络的鲁棒性。
2. 模型
每个单词都会有一个term-count-of-labels,看这个式子kesi,每个单词都会有一个,c类,看的就是这个每个类里,这个词的数量是多少。词库V是,从训练集里得到的。
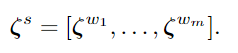
下面这个是给一个句子,句子里有m个词,把每个词的term-count-of-labels向量组合成一个term-count-of-labels矩阵
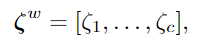
这个统计信息代表的意思是,如果某个词在所有类上都有很高或很低的频率,那说明这个单词对分类任务没啥太大用。如果一个词在某些特定类里出现的频率更多,那就说明这个词是有区别的,是对分类有用的。
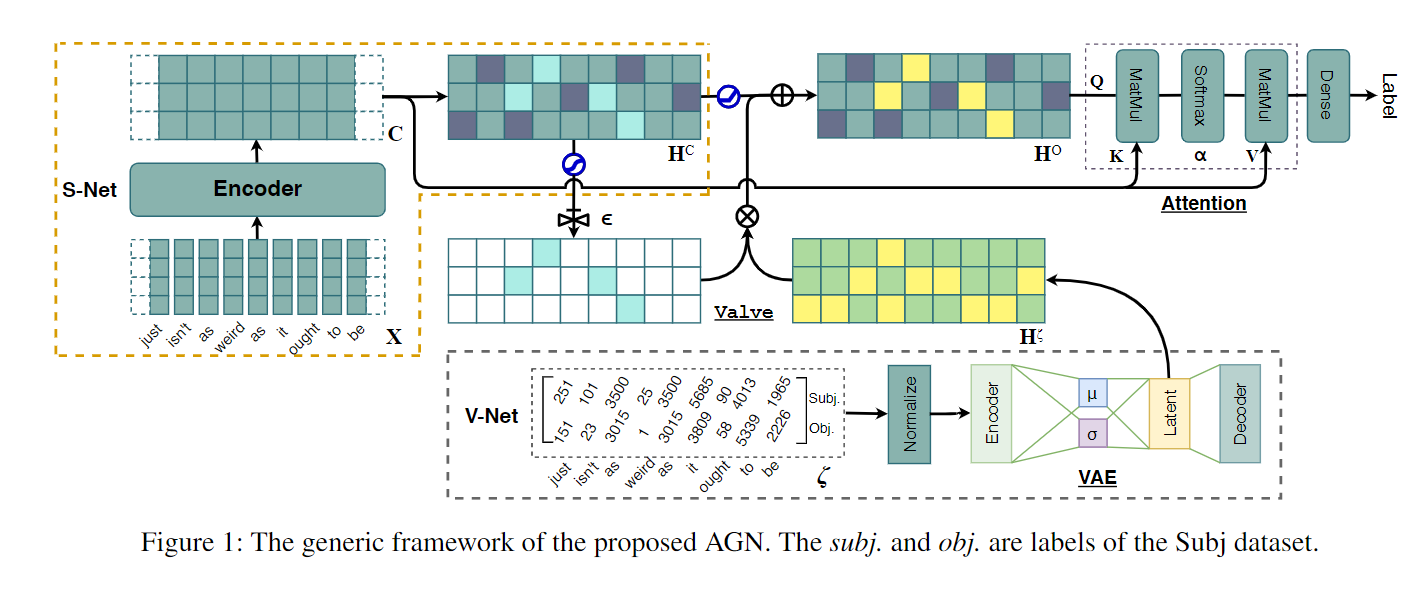
上一个图的TCOL,就是Vnet里的前面,这个模型是V-Net: Variational Encoding Network,和S-Net: Semantic Representation Projection Network和valve component(阀门)。
不同于vanilla autoencoder(三层的自编码器,2006年提出,只有三层网络,即只有一个隐藏层的神经网络。它的输入和输出是相同的,可通过使用Adam优化器和均方误差损失函数,来学习如何重构输入。隐藏层的压缩维度为32,小于输入维度784,因此这个编码器是有损的,通过这个约束,来迫使神经网络来学习数据的压缩表征。)
这个模型的输入,下面那个代表的是数据集里,所有句子的TCOL,term-count-of-labels,是N个独立同分布的,离散的TCol kesi变量。
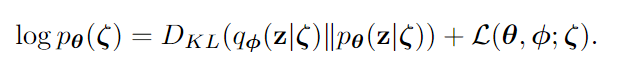

Valve Component阀门组件是为了能把经过bert的语义特征和经过VAE的统计特征结合在一起。它首先就是把统计信息过了个dense,经过线性层。
前面就是语义特征过了ReLU,后面是自己定义的一个阀门函数。引入了一个e,它是超参数,作用是调整置信度的阈值。就是当e=0的时候,就是不要所有的统计信息。如果e=0.5的时候,就是应用所有的统计信息。所以这个Valve就是个过滤器,来留下哪些必要的信息。
最后再经过一个注意力机制,来把已经合并的语义信息和原始的过bert得到的语义信息整合在一起。
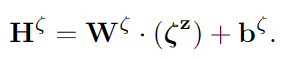
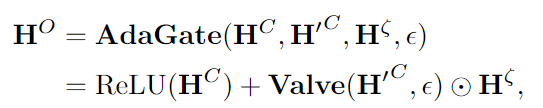

4实验
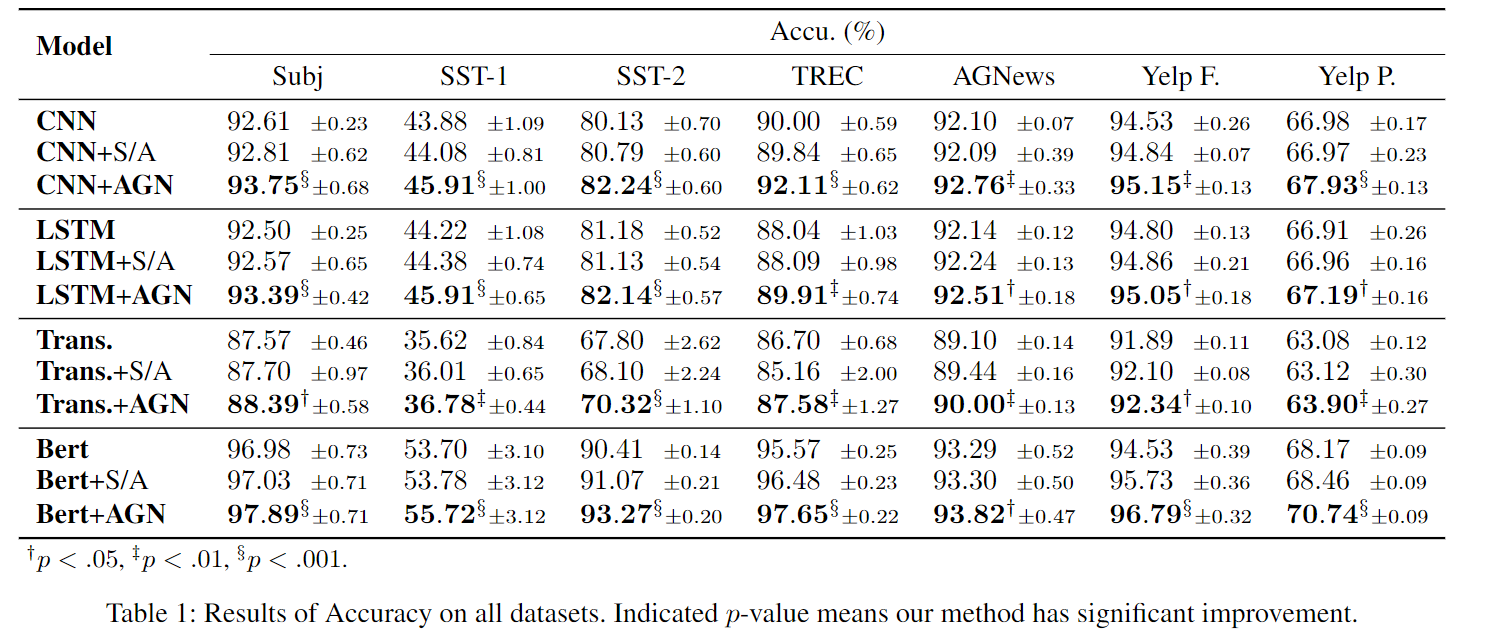
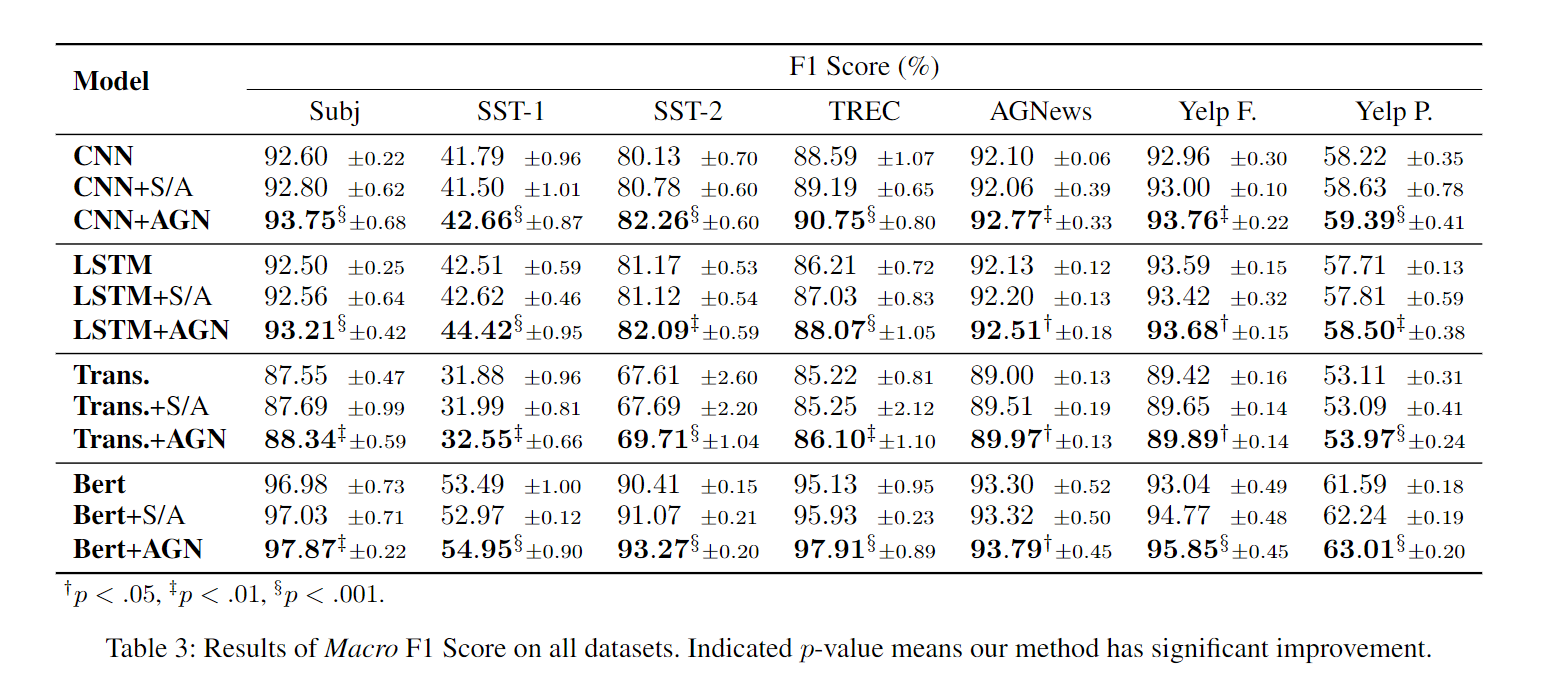
实验上是在七个数据集上,都提升了差不多一个点。第二个是为了平衡这个模块最后加了个attention,所以在各个模型后面也加了attention模块
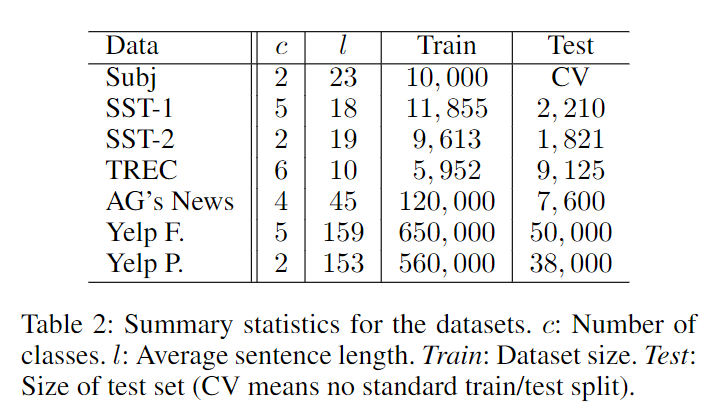
统计了一下,各个数据集的信息。Subj: Subjectivity dataset.URL这个语料的标注为这些观点是否主观
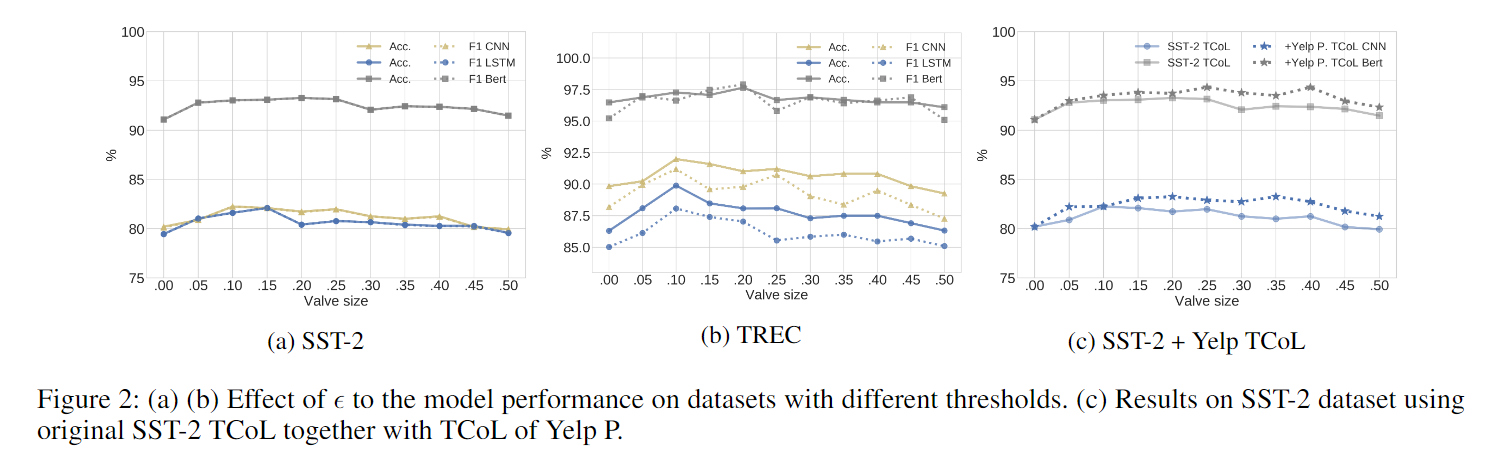
验证加了那个阀门组件的作用。这里面它挑了两个数据集进行实验,发现全加统计特征比不加强,但是不是所有统计特征加进去都是有效的。
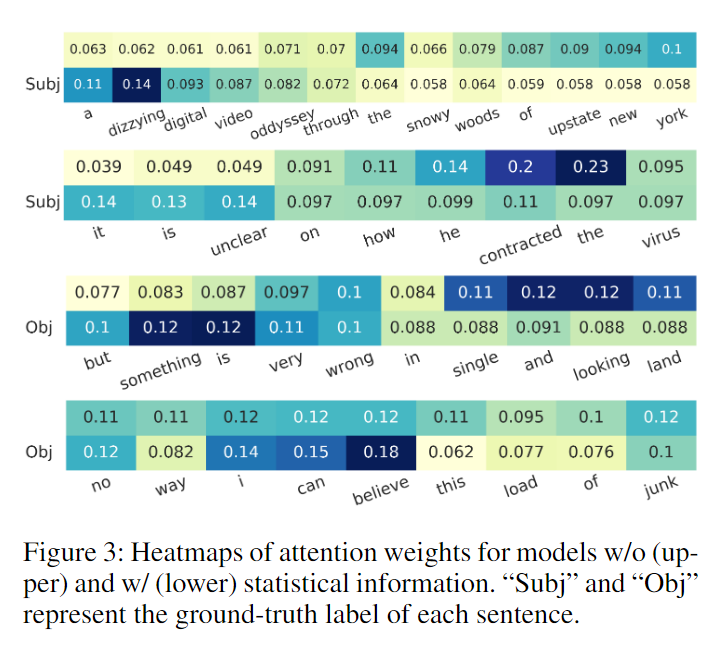
用注意力权重的热图来分析,Subj数据集中,不加统计信息没分类成功的,加了统计信息就能分类成功。
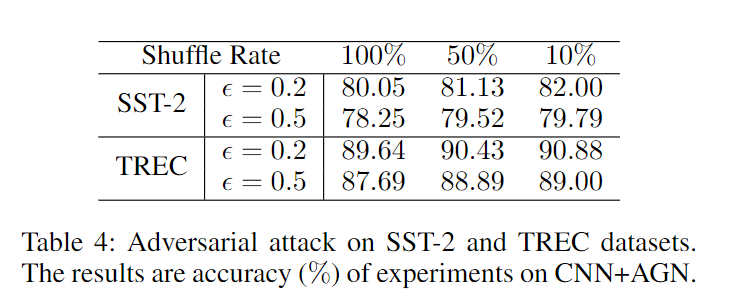
除此之外,为了验证这个AGN的网络的鲁棒性,作者在两个数据集上打乱TCol词典,发现e=0.2的时候,它的抗性比较好。这个实验证明了对统计信息的处理会给分类器带来噪音并影响性能,但是也能证明AGN对此类攻击有足够的鲁棒性。就是在e=0.2的时候,它的结果还是比不加AGN网络好的。
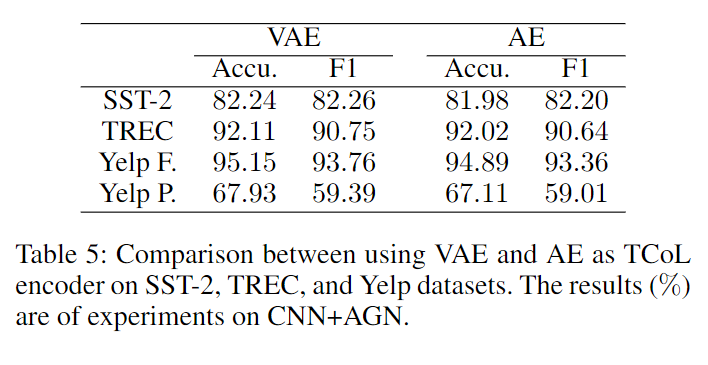
除此之外它还验证了为什么使用VAE而不适用AE