简介:
利用知识图谱(KG)来丰富新闻文章的语义表示被证明对新闻推荐是有效的。不同的用户对同一篇新闻文章会有不同的兴趣,直接识别与用户兴趣相关的实体并推导出用户表示可以实现更好的新闻推荐和解释。作者提出了一种新的基于知识剪枝的循环图卷积网络(Kopra)来进行新闻推荐。首先从新闻标题和摘要中提取种子实体,形成初始实体图(即兴趣图)。然后,引入一种联合知识剪枝和循环图卷积(RGC)机制,用KG中的相关实体扩充每个种子实体。KG中每个种子实体的邻域中与用户兴趣无关的实体将从扩充中删除。通过这种反复进行的修剪和图形卷积过程,可以根据用户在长时间段和短时间段内的点击历史分别推导出用户的长期和短期表示。最后,我们在长、短期用户表示和候选新闻中的种子实体上引入一个最大池预测器来计算推荐的排名分数。在两种不同语言的两个真实数据集上的实验结果表明,提出的Kopra比一系列最先进的技术替代方案获得了显著更好的性能。此外,Kopra生成的实体图可以更方便地解释推荐。
引言:
任务背景:
利用知识图谱(KG)丰富新闻语义表示,在新闻推荐中取得了巨大的成功。但它们有两个共同的主要局限性,首先,现有的解决方案都忽略了通过知识图进行直接用户兴趣建模。他们通过对用户行为进行学习,来获取用户的兴趣表示。其次,并不是KG提供的所有背景知识都与用户的兴趣相关。
任务定义:
建立了一个循环图卷积网络模型,通过用户行为与知识图谱构建用户的新闻兴趣表示,并对知识图谱进行了剪切,去除了与用户行为无关的实体。
主要贡献:
将用于丰富新闻语义的知识图谱进行了剪切,能够更好的对用户兴趣进行表示
模型总览:
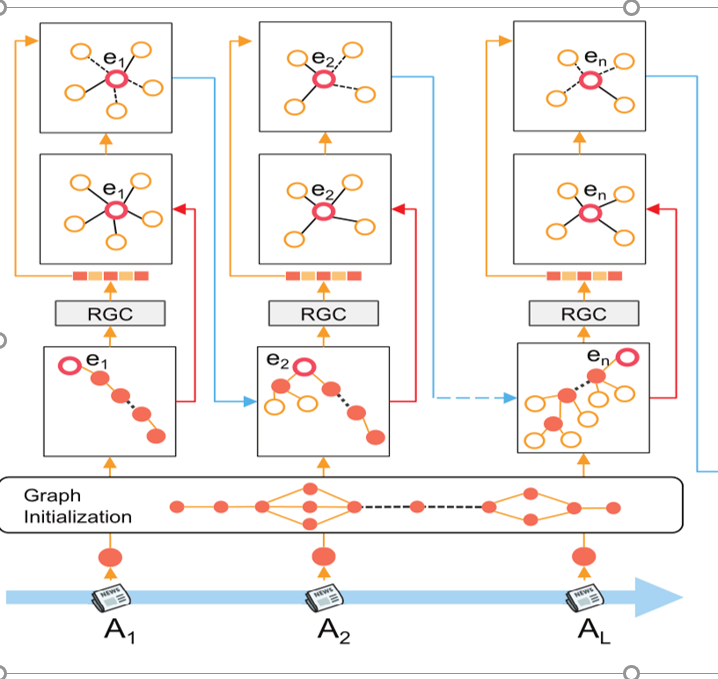
第一部分

用户的浏览历史H_u ,每个新闻中包含的实体集合e_{A_k},每个实体称为种子实体,得到用户的初始兴趣图G_u
第二部分
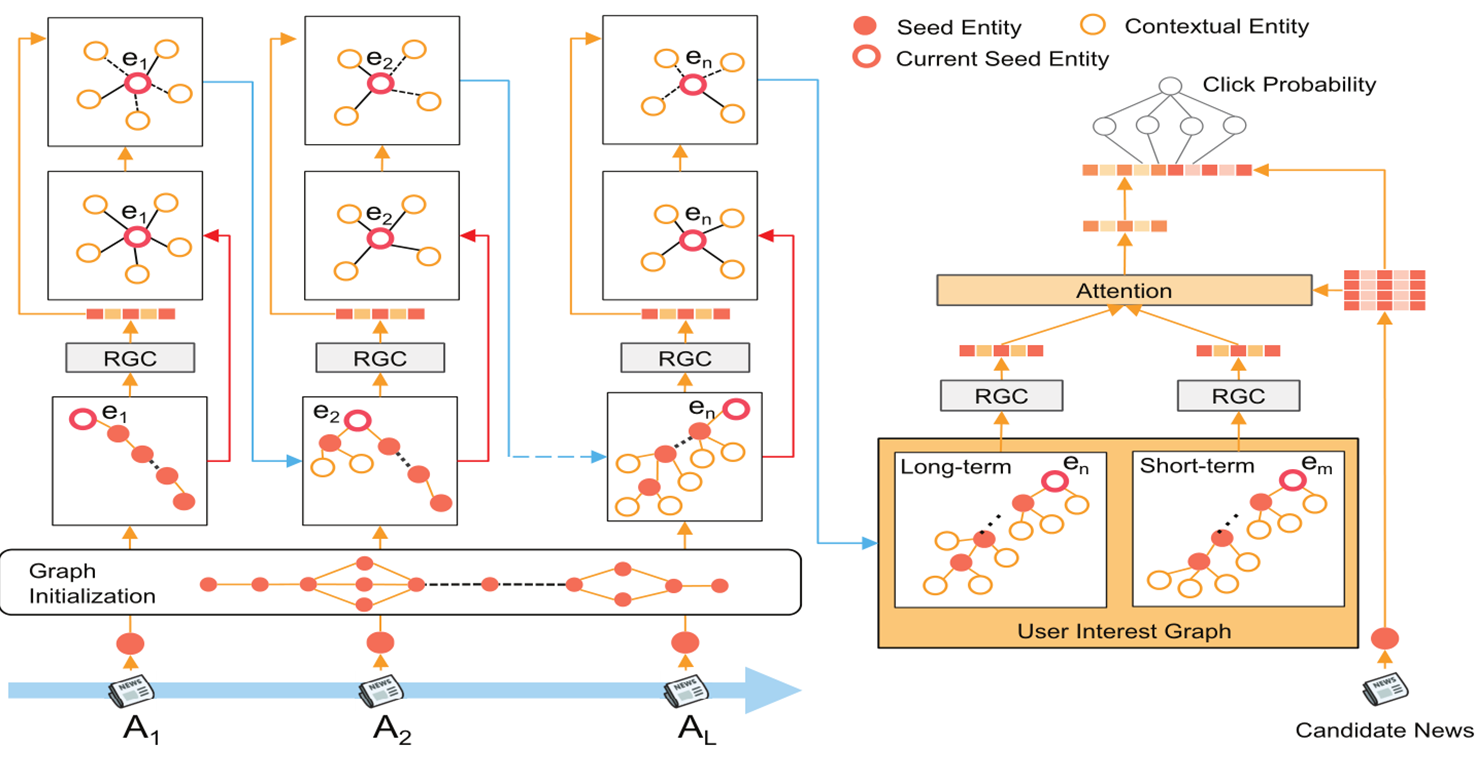
用对每个实体用知识图谱丰富其语义表示,并相应的对知识图谱进行剪切,直到将初始兴趣图中的所有实体都用知识图谱进行语义丰富
首先对每个实体进行RGC的一个网络层, ,然后对用该实体的知识图谱丰富其语义,,表示与种子实体ek相关的上下文实体e的enbedding,大于0,保留该实体。最后可能会因为最后一篇新闻中有若干个实体,为了使最后输出一个结果,在最后加入一个虚拟实体p进行最后一步RGC运算得到用户的兴趣表示
,然后对用该实体的知识图谱丰富其语义,,表示与种子实体ek相关的上下文实体e的enbedding,大于0,保留该实体。最后可能会因为最后一篇新闻中有若干个实体,为了使最后输出一个结果,在最后加入一个虚拟实体p进行最后一步RGC运算得到用户的兴趣表示
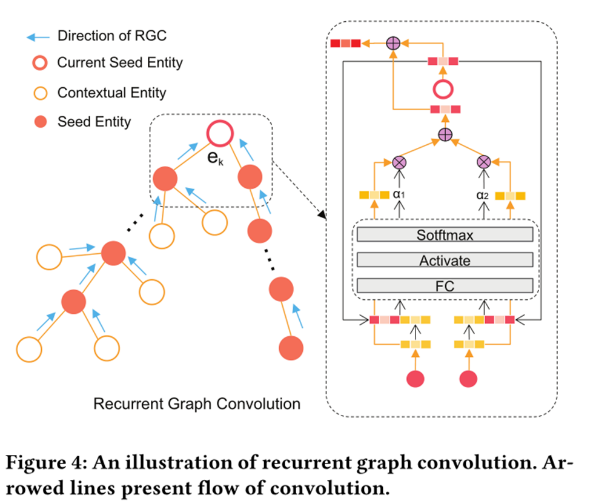
RGC层:采用双向传播的方式对种子实体ek进行编码,种子实体ek的向量组成是该实体ek向量加上双向传播后的向量和。
前向传递的结果是该实体的向量加上参数系数乘以它前一个种子实体ek-1的RGC结果,再加上参数系数乘以前一个种子实体的相关实体的向量表示组成。后向传递的结果是该实体的向量加上参数系数乘以它后一个种子实体ek+1的向量表示,如下
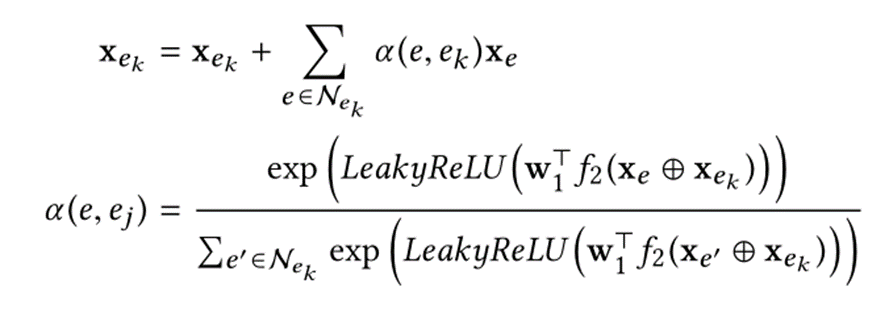
第三部分:
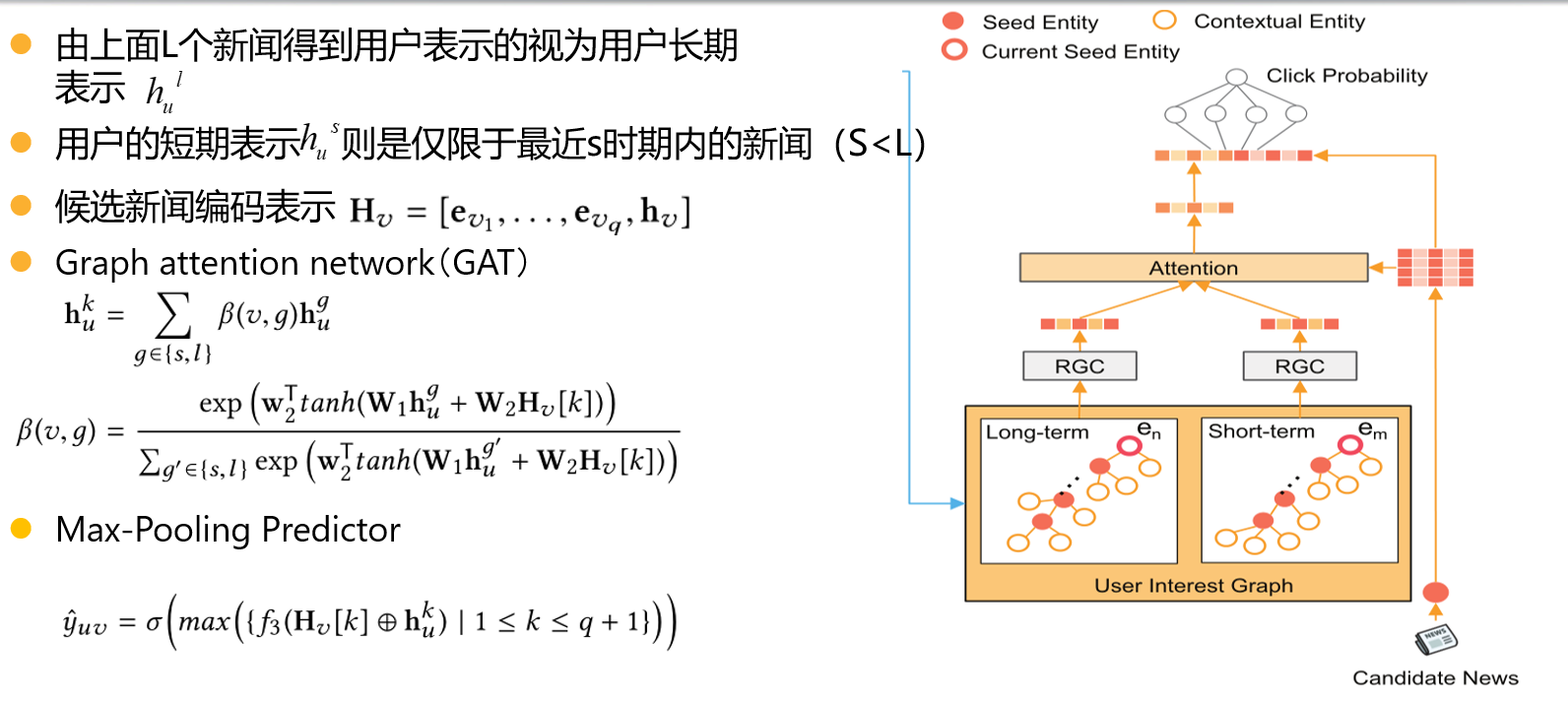
候选新闻编码使用的是该新闻所有的实体向量与这些实体向量和,这样可以对同一新闻的进行不同的表示。最后采用最大池化来对候选新闻进行打分预测。
模型优化:
使用交叉熵作为损失函数,作者进行了强化学习,将每次RGC操作后,进行更新的用户兴趣表示作为状态,对该状态进行损失预测,最后采用蒙特卡洛模型算法计算平均值作为损失。作者同时进行了知识图谱的纠正更新,对于未在数据集中出现的实体,使用TransE算法进行建模,损失函数如下图。

数据集:使用了MIND数据集与Adressa数据集
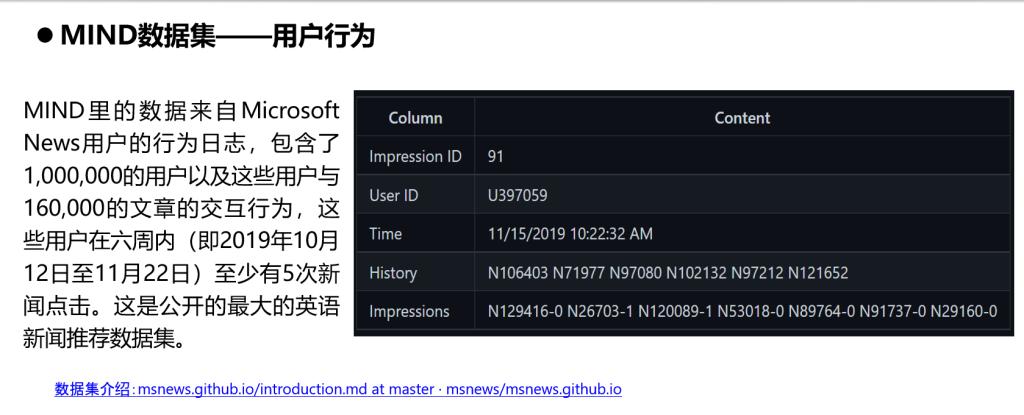
如何构建知识图谱:

实验部分:
分别在MIND数据集与Adressa数据集进行了测试,DKN,RippleNet,TEKGR是三个将知识图谱用于丰富新闻语义的模型,其余四个则是没有采用知识图谱的新闻推荐模型。
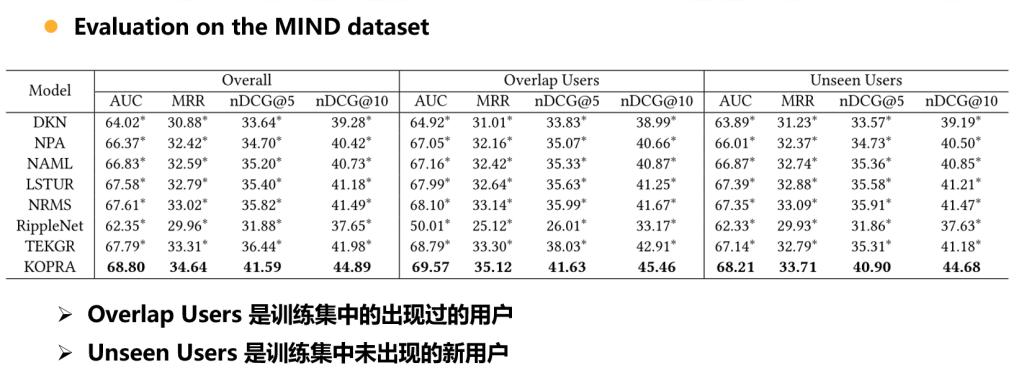

消融实验与短期兴趣实验:
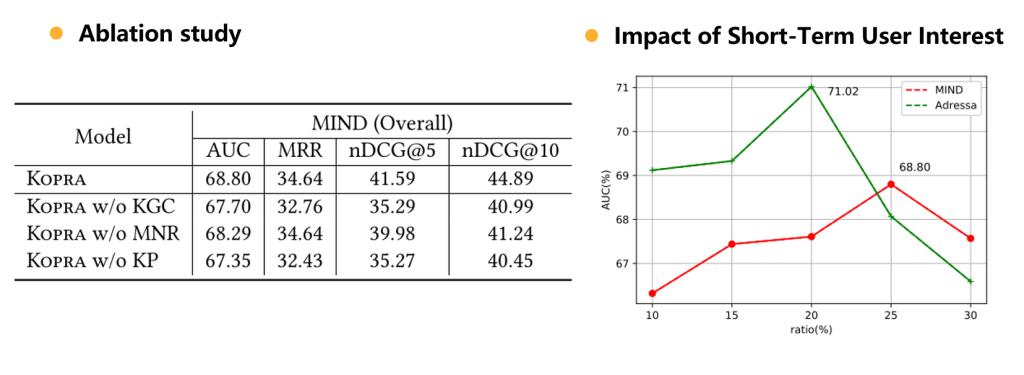
KG校旨在将每次迭代中更新的实体的表示更改传播到KG中的其他相关实体。通过与KG中提供的背景信息对齐,Kopra可以很好地避免模型过度拟合问题。例如,新闻标题可以包含“唐纳德·特朗普”而不是“美国总统”。但这两个实体在KG中有很强的相关性(即(“唐纳德·特朗普”,担任“美国总统”)的职位)。如果没有KG修正,实体“美国总统”的代表性可能不太可能更新,这可能会在删减和测试过程中产生负面影响。如果不进行KG校正,nDCG@5和nDCG@10性能降低的幅度将分别达到15.1%和8.7%。对于多个新闻表示,这种设计选择可以很好地模拟新闻文章的离散和多样语义。通过应用最大池,Kopra可以很好地了解点和联盟的利益。如果没有多个新闻陈述,科普拉的业绩将分别下降3.9%和8.1%nDCG@5和nDCG@10分别地最后,3)显然,知识剪枝在很大程度上提高了推荐性能。在不使用它的情况下,nDCG@5和nDCG@10性能降低高达15.2%和9.9%。
通过改变Kopra的{10%,15%,20%,25%,30%}之间的短期历史规模与长期历史规模的比率来绘制性能模式。一般来说,这两个数据集都没有完美的比值。最佳值由每个数据集中用户行为的特征决定。MIND数据集25%的值可以带来最好的性能,而Adressa的值是20%。