这篇文章是来IJCAI-2020,针对联合实体关系抽取相关的论文。
1论文的动机:
最近的进展将实体关系提取转换为多回合问答(QA)任务,并基于机器阅读理解(MRC)模型提供了有效的解决方案。但是,他们使用单个问题来描述实体和关系的含义,由于上下文语义的多样性,这在直观上还不够。同时,现有模型枚举所有关系类型以生成问题,这效率低下并且容易导致混淆问题。
针对这两个问题本文解决的思路:
首先,在本文中,通过各种问题解答来改进现有的基于MRC的实体关系提取模型,即引入多样性问答机制来检测实体范围,并设计了两种回答选择策略来集成不同的答案。然后,我们建议预测潜在关系的子集,并过滤掉不相关的子集,以有效地产生问题。最后,实体和关系提取以端到端的方式集成在一起,并通过联合学习进行了优化。
2论文的方法:
本文主要是基于MRC的实体关系提取模型,其主要流程如下图:

1:首先通过使用机器阅读理解模型回答实体特定的问题,从上下文中检测头部实体。
2:然后,通过泛关系集生成一个基于首实体的关系特定问题。
3:最后,通过回答问题获得尾实体。
基于 mrc 的框架的优点如下:
(1) 问题提出了外部优先证据,即实体和关系类型。
(2) (2) MRC 模型通过问题与语境的交互作用,能够更好地捕捉语义信息。
上述两个方面都有助于实体和关系抽取。所以,在本文中,我们也是方法仍然是基于 mrc 的框架的;为了进一步改善提升基于MRC的实体关系抽取方法,我们提出了两点改进:
1:引入多样性问答机制来检测实体范围
2:代替枚举所有可能的关系类别,我们先预测潜在关系的子集,并过滤掉不相关的子集,以有效地产生问题
模型整体框架如图2所示:
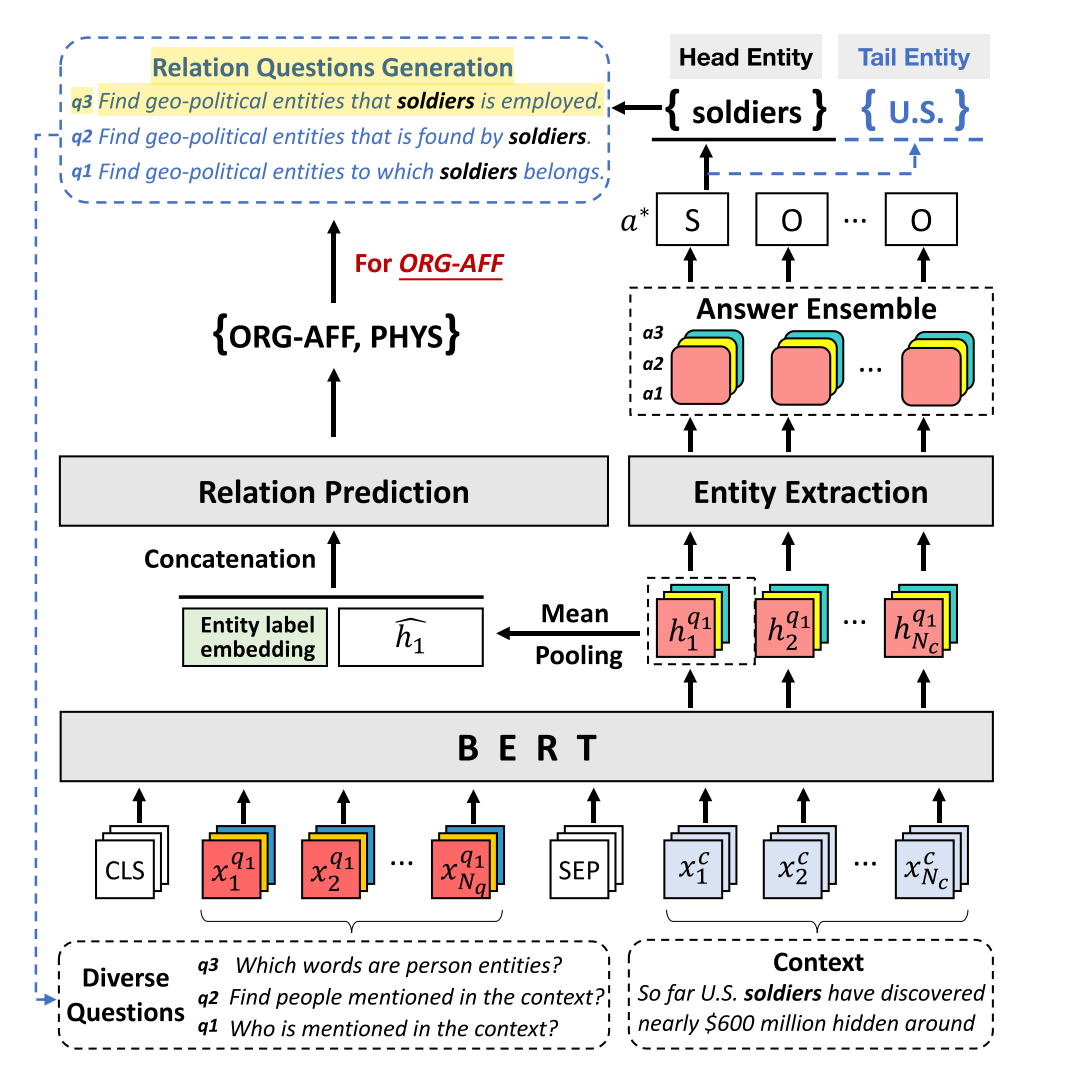
整个模型框架主要包括三个步骤:
1:头实体抽取
具体地,我们首先为每个实体类别生成问题集合;每个问题都与上下文相结合,并依次输入到基于 mrc 的实体提取器中。在得到相应的答案后,根据答案集成策略选择最终的答案。如果没有检测到答案,则表示上下文中没有包含此类实体。
2:关系预测
对于关系预测,我们对每一个提取出来的头实体 ei,过滤出与 ei 无关的低概率的关系,并保留一个潜在的关系子集 Ri。这样,大多数与头实体无关的关系就可以被丢弃。
3:尾实体抽取
给定抽取的头实体,我们生成不同的关系特定的问题,每个关系 rij ∈ Ri。示例如图2的左部分所示。然后,类似于头部实体抽取步骤,将问题与上下文相结合,输入 MRC 模型,提取潜在的尾部实体。因此,基于 mrc 的框架可以有效地修饰实体关系抽取问题.
具体的每个部分:
2.1:BERT-based MRC model for Entity Extraction:
假设给定的问题q = {q1, q2, . . . , qNq}和文本c = {c1, c2, . . . , cNc }我们将其输入到bert编码层中;获取文本的特征表示h = {h1, h2, . . . , hNc}
对于每个输入 xi,候选 bios 标签的概率可以通过softmax进行计算
2.2:Diverse Question Answering
直观地说,从不同的角度解释一个问题可以使问题更加清晰。作为启发,我们根据预定义的问题模板为每个实体和关系类型生成一组问题。一个小组中的问题具有相同的意思,但表达方式不同。
例如,对于PER实体类别,我们可以从不同的角度提出问题
• q1: Who is mentioned in the context?
• q2: Find people mentioned in the context?
• q3: Which words are person entities?
对于每个问题我们获取一个对应的答案,最后我们通过答案集成策略获取最终的答案表示;
2.3:Relation Prediction
关系预测的目的是为每个提取的头实体识别 ei最可能关系类型集 Ri;
具体地说,将 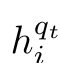 表示为头实体ei的开始token的BERT 上下文表示, qt 表示第t个问题,xli相应的实体标签嵌入.具体计算如下公式:
表示为头实体ei的开始token的BERT 上下文表示, qt 表示第t个问题,xli相应的实体标签嵌入.具体计算如下公式:
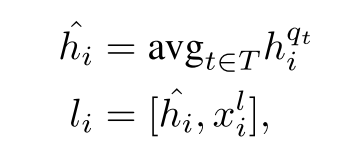
最后,我们通过sigmoid函数保留和头实体相关的关系类别,进一步地,我们生成实体关系问题作为第二轮的问题输入;
3论文的实验:
3.1实验数据集:
ACE05和CoNLL04数据集;
3.2实验结果:

通过实验结果我们可以发现三点:
1:多样化的问题回答和关系预测,明显地促进了基于 mrc 的实体关系抽取的形成
2:基于 mrc 的模型的性能明显优于基于非 mrc 的基线
4总结:
1:因为问题可以作为潜在的先验知识,所以阅读理解的模型框架本身具有一定的优势,
2:提出问题的方式和角度能够促进实体关系的抽取;