该篇论文发表在ACL2020上,使用联合训练为生物领域事件抽取提供了可解释性,该方法还可用于半监督学习,所用语料集来源是BioNLP 2013-ST。作者单位是亚利桑那大学。接下来主要从四个方面介绍这篇论文的相关内容。
一、介绍
首先说明一下选择这篇论文作为主讲的原因主要有四个方面,一是本篇论文涉及可解释性相关内容,人工智能可解释性是目前研究的热点问题,在许多领域都需要人工智能的可解释性,如生物医学领域、法律等领域;二是论文涉及多任务的联合训练,这也是目前研究的主流方法,通过多任务的方法来提升任务本身的性能;三是本篇论文的主要任务是生物医学领域的事件抽取,是我目前正在研究的生物医学任务;四是本篇论文采用的语料集来自BioNLP 2013共享任务中GENIA事件抽取语料集,是我们目前比较熟悉的语料集。
目前人工智能的可解释性是研究的热点问题,众所周知,深度学习网络是个黑匣子,缺少很多合理的解释,导致神经网络在一些领域的应用受到限制,所以增加人工智能的可解释性非常必要的,也是目前研究的一种趋势。从传统的角度分析可解释性人工智能的方法有:1. 基于规则,形式如下
ü IF X∈ D(i) THEN Y= y(i)
ü IF X1∧X2∧X3…∧Xn THEN class C
其中第二种形式表达了决策树的可解释性逻辑;
2. 基于统计,基于统计方法的可解释性模型主要包括线性模型、扩展的线性模型、朴素贝叶斯分类器等;
3. 基于模糊数学;
从深度学习角度分析可解释性人工智能的方法基本上都是基于决策树的方法,要么将训练的神经网络转换成决策树,要么直接训练决策树来预测模型结果,总之就是把统计模型转换成决策树模型。还有一种方法是联合训练统计学习模型得到可解释性输出,本篇论文使用的是这个方法。
本篇论文的任务是事件抽取,什么是事件抽取?从当前比较火的知识图谱入手简单介绍。现有的知识图谱是一个静态知识的存储方式。比如“奥巴马的妻子——米歇尔”中,奥巴马是头实体,关系是配偶,米歇尔是尾实体。但是事件抽取的结果可以组成一个动态的知识图谱,或者以一个事件为中心的事件图谱。对于“奥巴马的配偶是米歇尔”这件事情,如果我们知道结婚时间,就可以确定他的配偶这个静态知识是何时开始的,之前是什么状态。
具体的事件抽取是如何定义的,如图1所示,这里的事件抽取是基于句子级别的,还有篇章级别的事件抽取,由于本篇论文和我们目前关于事件抽取的研究均是基于句子级别的,这里关于篇章级别的事件抽取不做详细介绍。事件抽取是由两大部分组成:触发词 (trigger) 和元素 (argument) 。Trigger是一个事件指称中最能代表事件发生的词,是决定事件类别的重要特征,大多数情况是个动词,也有可能是个词组或者其他词性的词。Argument是指事件中的参与者,是组成事件的核心部分,它与事件触发词构成了事件的整个框架。图1中辞职事件里,触发词是quit,参与角色是辞职人Barry Diller,他辞职的职位、时间和机构都可以抽取出来。只识别事件触发词的过程叫事件检测 (event detection),而事件抽取 (event extraction) 也做参与角色的抽取。
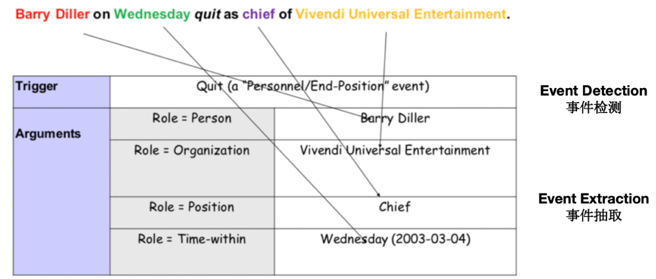
图1 事件抽取定义
事件抽取和关系抽取有一定的相似性,关系抽取是值识别句子中两个实体之间的关系而事件抽取是识别句子中某个事件和某个实体之间的关系。
事件抽取在通用领域比较常用的数据集有如下三个:MUC(message understanding conference)、TDT(topic detection and tracking)、ACE(KBP)(automatic content extraction)。
其中MUC语料组织者是DARPA,该语料抽取指定的事件,包括参与这些事件的各个实体、属性和关系。例如:MUC-2是从海军军事情报中抽取事件填入预定义模板中;TDT语料组织者也是DAPRA,该语料将文本切割为不同的新闻报道,监控其中新事件的报道,并且将同一话题下的分散报道按照某种结构有效组织起来。TDT-3有240个topic;ACE语料组织者是NIST,该语料指定的源语言数据中发现特定类型的事件,并且识别出与事件相关的信息填入预设的事件模板中。ACE中共计8大类33个小类的事件。本篇论文使用的语料集是ACE2005。
在生物领域中也有一些数据集的构建,按照时间发展顺序,比较有名的就是如下这四个,PASBio、GENIA、BioNLP、ProcessBank。这里有关于kim等人构建数据集的官方网站介绍[1],和genia这个语料的下载网址[2]。其实这里列出的只是笼统的生物语料构建组织单位,其中可能还包好一些语料构建小分支,例如BioNLP,从2009年最初发布共享任务,一共举行了四届,分别是2009,2011,2013和2016。
图2 句子示例
本篇论文使用的是BioNLP 2013 shared task中关于基因表达的语料,如图3所示,生物医学事件的结构化表示如表格所示,首先是需要知道实体信息(entity)和触发词信息(trigger),触发词决定了事件的类型(event),实体和其他事件为事件的元素,最后构成事件。
本篇论文的贡献主要有如下四点:
1、 使用联合学习抽取事件并解释了决定事件类型的原因。
2、 扩展了BioNLP 2013 GENIA事件抽取语料的一个子集。
3、 可解释性提高了分类器的性能。
4、 该方法可以应用到半监督学习中。
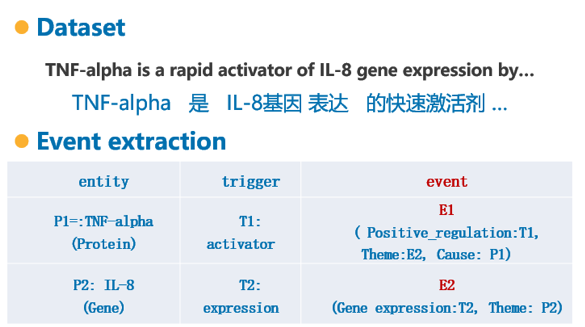
图3 生物医学领域事件抽取
二、方法
该论文使用了一个基于注意力机制的编码器来编码输入文本和给定实体,其中给定实体是指生物医学领域的一些实体,如蛋白质;使用解码器联合训练两个任务,任务一是事件抽取,任务二是规则生成。接下来具体介绍一下这两个任务。
任务一是根据给定的句子和实体,识别出该实体应用在哪个事件上,事件的触发词是什么。是关于事件抽取的二元分类任务,他的输入是:xi = e(wi)○e(pi)○char(wi)。其中e(wi)是通过word2vec训练1亿个pubmed医学文献论文得到的词向量,e(pi)是指位置向量,是随机初始化产生的。Char(wi)是字符向量,也是随机初始化产生。整个任务涉及到的深度学习模型是双向LSTM模型和注意力机制,即输入词向量,将词向量输入到BiLSTM模型中,在将BiLSTM层的输出输入到注意力机制层。在该过程中使用的注意力机制是基于论文《attention is all you need》,其中不同的是向量q,在该网络中只计算单一向量q,不计算整个矩阵Q,其他均与原始论文相同。其中W的维度是200×200,使用的损失函数是二元对数函数。
任务二是解码一个规则,该规则是用odin语言编译的,用来解释事件分类器预测的原因。使用的解码器也是基于LSTM-attention架构,在每个时间步计算如下:
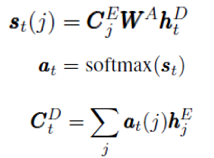
其中W的维度是100×200,C是文本向量,损失函数使用的是交叉熵损失函数。
在这里简要介绍一下odin语言,Odin 是一种快速、简洁、可读且实用的编程语言,其希望用简单、高性能、为现代系统构建这些目标取代 C。他的特性有:内置类型:strings、array、slices、dynamic arrays、maps、128-bit integers 与 endian-specific integers;多返回参数;一致的值声明语法;参数多态性;没有完全编译时执行编译时间条件(when 语句)和状态;context 系统和内存分配器系统;显式过程重载。具体如图4所示。

图4 odin语言

图5 事件抽取规则样例
事件抽取规则样例如图5所示,是关于如何用规则构建样例,图中所示是一个磷酸化事件,事件唯一元素(磷酸化的蛋白质)是通过语义和语法约束确定的。语义约束是:它的类型必须是蛋白质。语法约束是它必须通过这种句法依赖模式和触发词联系在一起。图中这个规则是用来抽取PKC(磷酸化作用)这个事件的。
对这两项任务对应的损失进行联合优化。损失函数形式上定义如下:
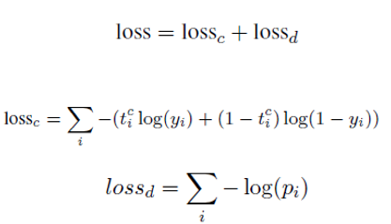
其中第一个loss是任务一事件分类的损失函数,正例时tc取1,负例是tc取0,y是模型预测出的概率值。第二个loss是规则解码器交叉熵损失函数,pi是解码器在i位置解码正确token的概率。
三、实验
数据集有BioNLP 2013 GENIA Events extraction shared task (Kim et al., 2013)
涉及的事件类型主要有三种:Phosphorylation (P), Localization(L), and Gene Expression (GE)
使用PubMed针对上述三种事件生成的正例分别为6592, 6321, and 2056。负例3467, 3532, and 2876。
使用的评价指标有P,R,F1以及BELU。其中BLEU是2002年Kishore Papineni等人发表论文《BLEU: a Method for Automatic Evaluation of Machine Translation》中提出。BLEU全称是Bilingual Evaluation Understudy(双语评估替换),是一个比较候选文本翻译与其他一个或多个参考翻译的评价分数。尽管BLEU一开始是为翻译工作而开发,但它也可以被用于评估文本的质量这种文本是为一套自然语言处理任务而生成的。它可以看成一种对生成语句进行评估的指标。完美匹配的得分为1.0,而完全不匹配则得分为0.0。Python自然语言工具包库(NLTK)提供了BLEU评分的实现,你可以使用它来评估生成的文本,通过与参考文本对比。
文中使用的baseline是基于论文《Marco A. Valenzuela-Esca´rcega, O¨ zgu¨n Babur, GusHahn-Powell, Dane Bell, Thomas Hicks, EnriqueNoriega-Atala, Xia Wang, Mihai Surdeanu, EmekDemir, and Clayton T. Morrison. 2018. Large-scale automated machine reading discovers new cancer driving mechanisms. Database: The Journal of Biological Databases and Curation.
》提出的系统。Baseline结果如图6所示。

图6 baseline结果
如图7所示实验结果说明了生成银语料的有效性,说明该方法可以用于半监督学习中。
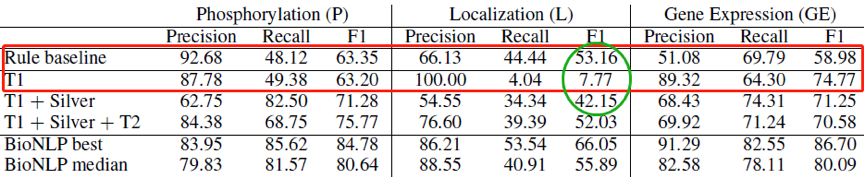
图7 有效性1
如图8所示实验结果说明了联合学习的有效性。

图8 有效性2
如图9所示实验结果说明了该方法适合小语料集,大语料集上效果较差,原因是生成的银语料给金标准语料集造成了噪音,影响了最初的实验效果。

图9 有效性3
从图10的实验结果可以看出生成语料的高质量性。
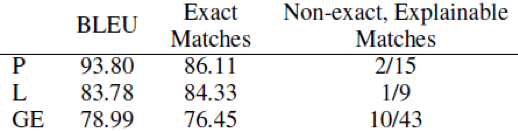
图10 生成语料的有效性
四、结论
这篇论文主要是提供了生物医学领域事件抽取的可解释性,并通过联合学习来优化事件分类器的性能,提高了实验结果,还利用规则可以自动生成标签数据可以应用在半监督学习任务中。
由该篇论文引发了一些自己的思考。
我们针对小语料集是否有独特创新的方法?
我们针对生物语料集是否有针对性解决方法?
基于规则与基于统计的相互联系,能不能进行互补性利用?
如何利用可解释性人工智能发展趋势?
在bert等预训练模型发布后,走结果创新道路还是模型创新道路还是方法创新道路?