这篇文章是来EMNLP2019针对序列标注相关的论文。相关的代码链接:
序列标注问题主流的方法有三种主流方法:1)BiLSTM-softmax 2)BiLSTM-CRF 3)Bert-BiLSTM-CRF/Bert-CRF 。而本文提出了一种全新的模型BiLSTM-LAN,接下来我们将对其进行详细介绍。
论文的动机:
对于序列标注任务,BiLSTM-CRF相比与BiLSTM-softmax,并不总是能得到更好的结果,首选是CRF可能会受到其马尔科夫假设的限制,其次是,当标签数量较大时,CRF的计算成本会很高,而当前的序列标注任务很少利用标签信息来更好地解决标签序列任务,所以作者提出了一种分层细化的标签注意力网络,它显示地利用标签嵌入,并通过给每个词提供分层注意力的增量细化标签分布来捕捉潜在的长期标签依赖性。具体的模型框架图如图一所示。
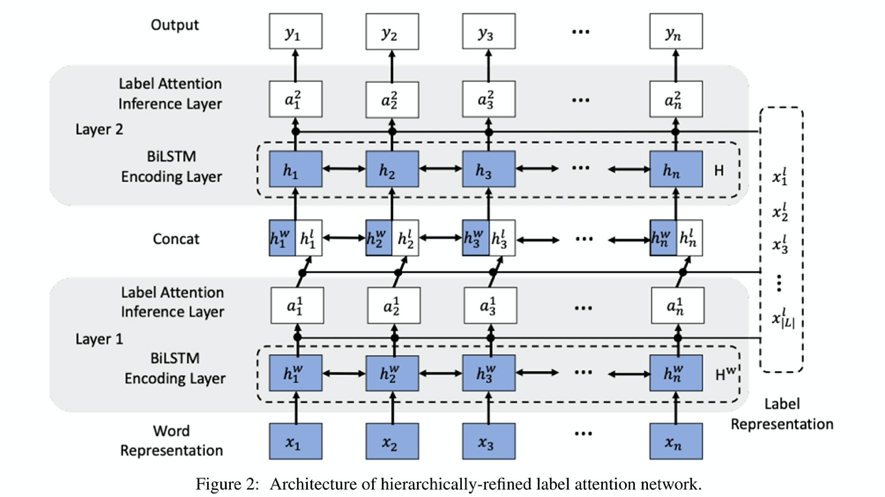
下面主要对模型框架图进行详细介绍下:
Word Representation Layer:
对于词表示层,使用词嵌入和字符表示,而字符表示采用Bi-LSTM编码。
Label Representation Layer:
对于给定的候选输出标签集合L = {L1,L2,,lk,,,Ln}
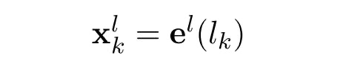
每个标签通过随机初始化的嵌入向量来表示
Sequence Representation Layer:
对于序列编码层,给定一个输入句子X = {X1,X2,···,Xn}被喂给Bi-LSTM
产生序列的前向隐藏状态和后向隐藏状态,从而得到最终的表示表示层。

Label-Attention Inference Sublayer:
对于标签-注意力推理子层,注意力机制产生一个注意力矩阵α,由每个词的潜在标签分布组成。

其中,Q = Hw, K = V = XL
这里作者使用的是多头注意力机制来并行捕捉多个可能的潜在标签分布
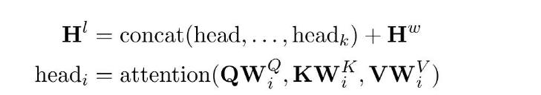
然后将attention的输出权重和lSTM的隐藏状态拼接。在和标签表示层进行一次attention 。
最终的输出:
在最后一层,BiLSTM-LAN根据注意力权重直接预测每个词的标签。
实验部分:
作者在English POS tagging,multilingual POS tagging,NER,CCG supertagging四个任务上进行实验。CCG supertagging任务和上面的三个任务不同之处在于,标签的数量是巨大的,CCGBank的标签数量已超过四百多。
论文的baseline是: BiLSTM-CRF、BiLSTM-softmax。作者的提出的实验方法相比基准方法有所提升,相比当前的一些方法也是有所提升的。同样在其他任务上也是表现较好。实验部分我就不具体展开了,这里直接截图下实验结果:
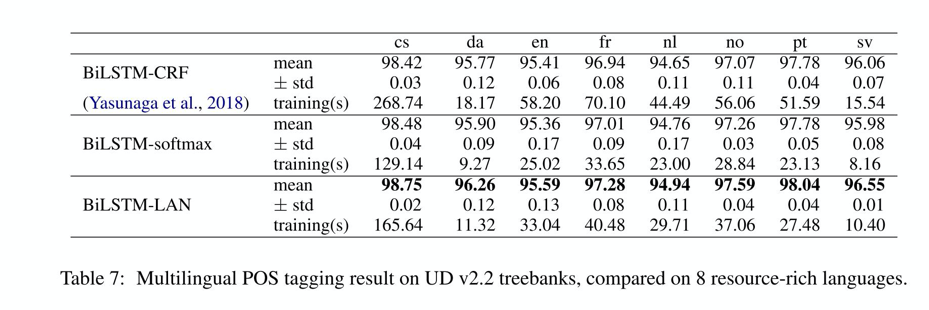
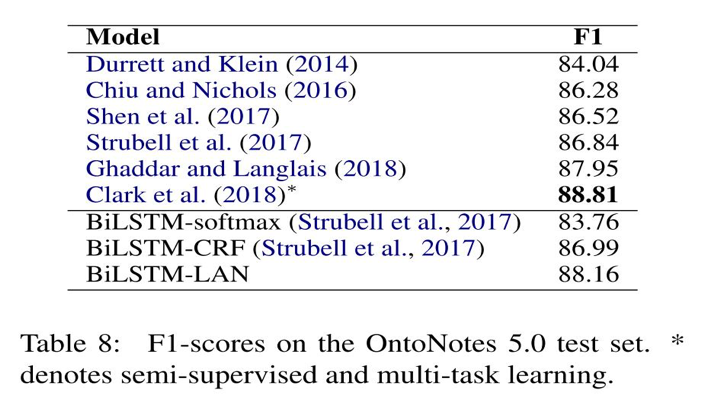
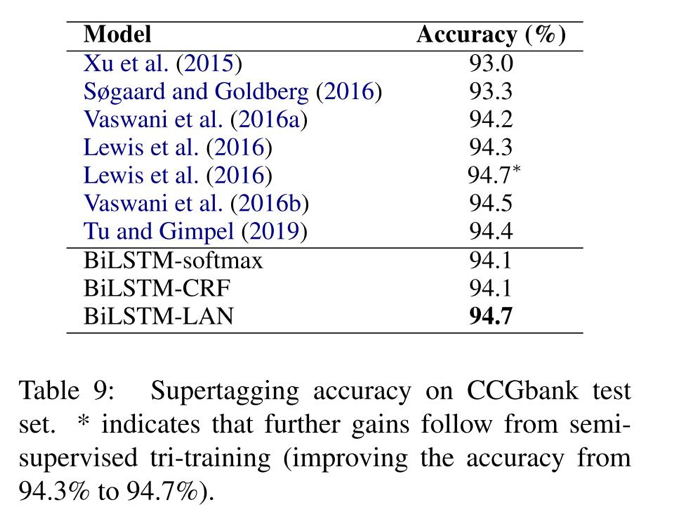
实验部分我觉得最好的不是实验结果,而是实验的详细和完备。这的我们好好借鉴。
首先作者在开发集上探索了超参数岁模型的影响,
其次,作者进行了消融实验,对比了利用attention的标签信息 和未使用的时候(第一层)和基准模型的对比的实验。
其三,作者在实验的推理速度上和基准模型进行对比
其四,作者记性了标签嵌入的可视化(可解释性)
最后,作者进行了案例分析以及模型标签类别复杂度的分析
实验做的很完备,值得借鉴。
但是这篇论文的思路使用的场合我觉的适合在标签数量比较多的时候会有明显的效果。在NER任务上标签的就不是很好,这就是很好的说明。其次,自己也尝试了复现和改进实验,效果提升有限。
最后,我沿着利用标签信息这个思路总结了一些之前看看过的论文。将一系列文章对比着看,回更有启发性。
·Multi-Label Image Recognition with Graph Convolutional Networks
·Learning Tag Dependencies for Sequence Tagging
·Label-guided Learning for Text Classification
·Embeddings of Label Components for Sequence Labeling: A Case Study of Fine-grained Named Entity Recognition
·Joint Embedding ofWords and Labels for Text Classification Guoyin