近日ACL2021程序委员会发布论文录用消息,实验室张冬瑜老师的论文“MultiMET: A Multimodal Dataset for Metaphor Understanding”和樊小超博士的论文“Hate Speech Detection Based on Sentiment Knowledge Sharing”被录用为主会的长文。此次ACL会议共收到3350篇有效论文投稿,主会论文和Findings论文录用率分别为21.3%和14.9%,ACL是自然语言处理领域影响力最大的国际学术组织,ACL会议被列为CCF推荐的A类国际会议。
(1)MultiMET: A Multimodal Dataset for Metaphor Understanding(MultiMET:一个面向隐喻理解的多模态数据集)
隐喻是十分普遍的语言认知现象,隐喻计算是自然语言处理中最具挑战性的难题之一。目前隐喻的相关研究多局限于对文本中隐喻现象的识别探索,究其原因是多模态隐喻数据资源的匮乏导致了相关研究受阻。为解决上述问题,本研究将社交媒体和广告等多模态隐喻出现频率较高的平台作为数据的主要来源,规范化多模态隐喻的概念界定及类别划分方式,建立多环节的质量监控机制,利用统计学对数据进行分析验证,提出了第一个大规模、高质量的多模态隐喻数据集——MultiMET。该数据集共计包含10,437个文本图片数据对,同时进行了一系列基线实验,利用多模态数据间的相互作用论证了多模态数据对于隐喻识别任务的重要性。根据多模态隐喻的特性,分别使用ResNet50、BERT和TCN对图像以及文本进行特征提取。并且使用OCR方法和物体识别技术,对图像中的文字和物体进行识别和提取,建立两种跨模态的特征,来帮助模型对不同模态之间的关系进行建模。最后使用层次融合方法,在多个层次上融合来自图像、文本、图像中的文本以及图像属性四个模态的特征向量,进行多模态隐喻识别。

本文探讨了多模态隐喻数据集构建的理论框架,并提出该数据集在多模态隐喻自动识别以及外语教学方面的应用。该研究是计算机科学与认知语言学交叉范畴下的一项前沿探索性研究,旨在提供大量真实、系统、具有推理功能,使用便捷的多模态隐喻数据资源,用以满足多模态隐喻在数据资源建设和应用方面的迫切需求。
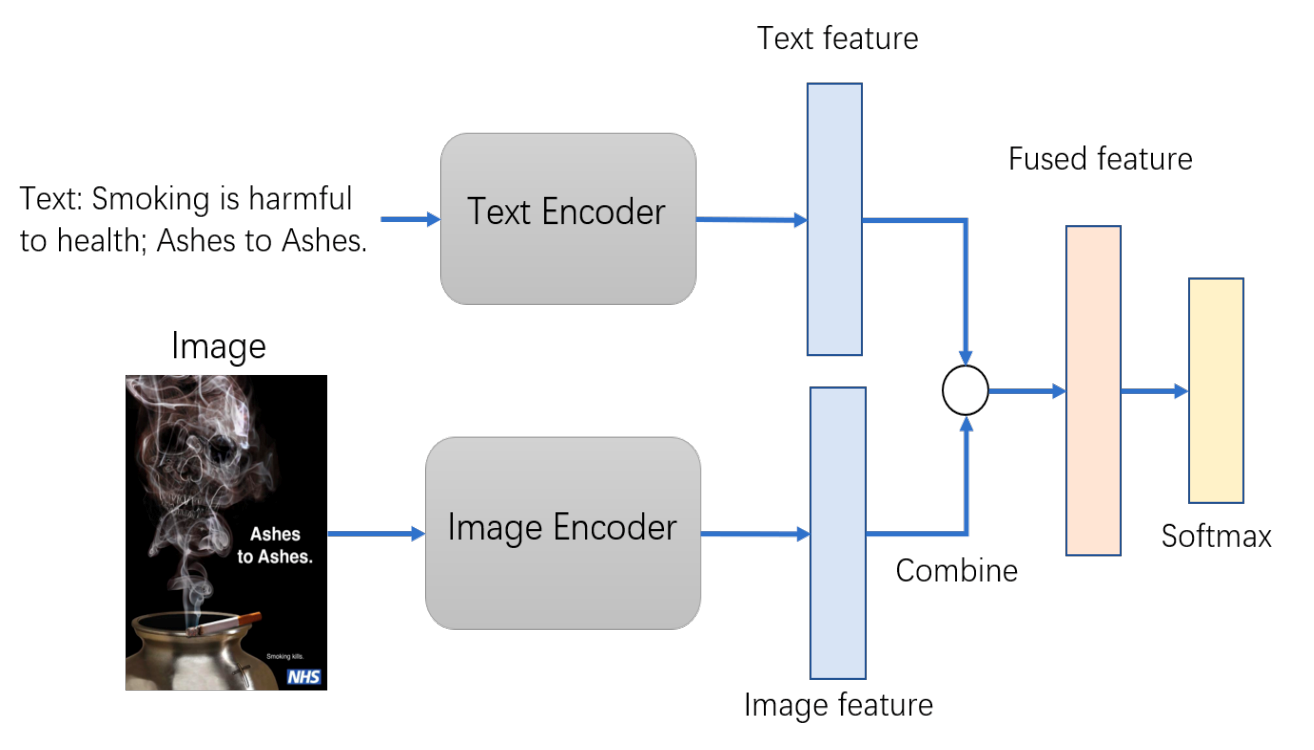
论文将隐喻计算研究从单纯的文本扩展到多模态,利用自然语言处理技术结合认知语言学理论, 制定了多模态隐喻的表示、分类、标注、计算的方法,推动了隐喻计算向多模态的发展,为隐喻识别任务在未来的探索提供了新的方向,对于隐喻研究和发展具有重要的意义。
(2)Hate Speech Detection Based on Sentiment Knowledge Sharing (基于情感知识共享的仇恨性语言检测)
研究意义:仇恨言论在互联网上的肆意传播给社会带来了极大的危害,亟需建立和完善仇恨言语的自动化检测和过滤机制。
研究现状:现有的仇恨言论检测模型主要分为两种:基于特征工程的机器学习方法和基于神经网络的深度学习方法,前者的缺点是人工特征只能反映文本的浅层特征,不能从深层语义特征中理解内容;后者的缺点是深度学习方法往往只使用更深层次的网络来获取语义特征,忽略了目标句子的情感特征,会在训练中对敏感性单词产生刻板印象,因此会受到固有偏见的训练,使得神经网络在仇恨言论检测中的性能不尽如人意。
算法模型:本文提出了一种新的框架SKS,引入外部情感资源获取更多的情感特征,提升模型对仇恨言论的检测性能:在编码层中利用预训练词向量GloVe获取一般的文本表示Word Embedding,之后引入外界词表,融入单词的侮辱性信息Category Embedding;在解码层中,采用多任务学习的方法使模型学习和共享外部情感知识(sentiment knowledge sharing),同时使用多个特征提取单元,每个提取单元使用多头注意机制和前馈神经网络来提取特征,获取文本的潜在的语义信息,最后使用门控注意力融合特征。SKS的模型架构图如下所示:
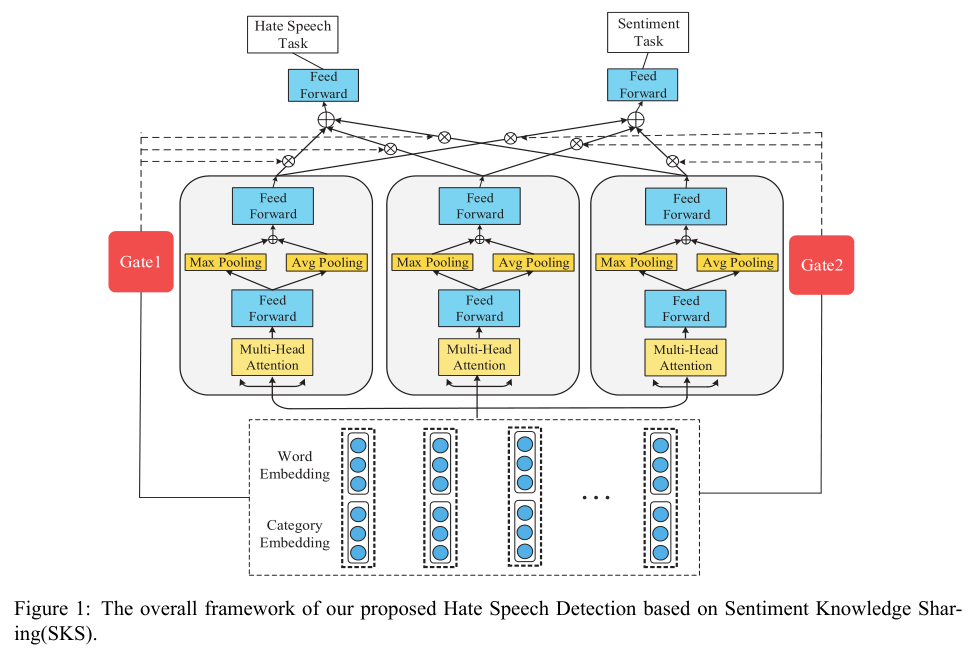
实验结果:实验选择了在文本分类任务中被广泛采用的F1和Acc作为评价指标,SKS模型在两个公共数据集SemEval2019Task5(SE)和Davidson Dataset(DV)上均取得了sota结果。相比于一般的深度学习方法(例如:CNN、LSTM),SKS在SE上的检测性能提升了约10%,在DV上提升了约3%。同时,消融实验的结果表明,文中的共享外部情感知识模块(sentiment knowledge sharing)能够显著提升模型对仇恨言论的检测性能。
未来展望:本文通过多任务学习表现了仇恨言论检测和情感分析这两个下游任务之间的关系,为未来更好的建模和数据选择打下了基础。我们会在之后的工作中,尝试使用不同类型的仇恨言论和情感数据,进一步验证模型的鲁棒性。