2021年10月15-17日,实验室林鸿飞、杨亮老师以及研究生十余人参加了在青岛召开的第十届自然语言处理和中文计算国际会议(NLPCC2021),此次会议由中国计算机学会自然语言处理专委会主办,山东大学计算机学院承办。
此次会议上实验室共有3篇论文被录用,分别是:
(1)Jiaming Wu, Hongfei Lin, Liang Yang, Bo Xu,MUMOR: A Multimodal Dataset for Humor Detection in Conversations. NLPCC (1) 2021: 619-627
幽默检测因其潜在的应用而在自然语言处理中引起了越来越多的关注。 之前的工作侧重于分析单一的文本数据的幽默,但幽默通常来自说话者之间以多模式方式的互动。 在本文中,我们提出了一个名为 MUMOR 的新数据集,它由英文和中文的多模态对话组成。 它包含来自两部电视情景喜剧的 1,298 段对话共 29,585 条话语。 我们手动注释每个话语的幽默、情感和情感极性。 据我们所知,这是第一个包含用于幽默检测的中文对话语料库。 该数据集可用于幽默检测、幽默生成以及情感和幽默分析的多任务学习的研究。 我们公开发布了这个数据集。

(2)Liang Yang, Jingjie Zeng, Shuqun Li, Zhexu Shen, Yansong Sun, Hongfei Lin,Metaphor Recognition and Analysis via Data Augmentation. NLPCC (1) 2021: 746-757
隐喻表达是一种广泛且常用的情感表达方式。目前的隐喻识别任务仍然缺少足够的样本。因此,本文引入数据增强来辅助动词隐喻的识别。首先我们提出了一种句子重构方法来修剪依存关系树,然后,采用一种基于Seq2Seq模型和重构句子的数据增强策略,最后,利用扩充的数据集对模型进行训练。实验表明,我们的模型取得了SOTA结果。

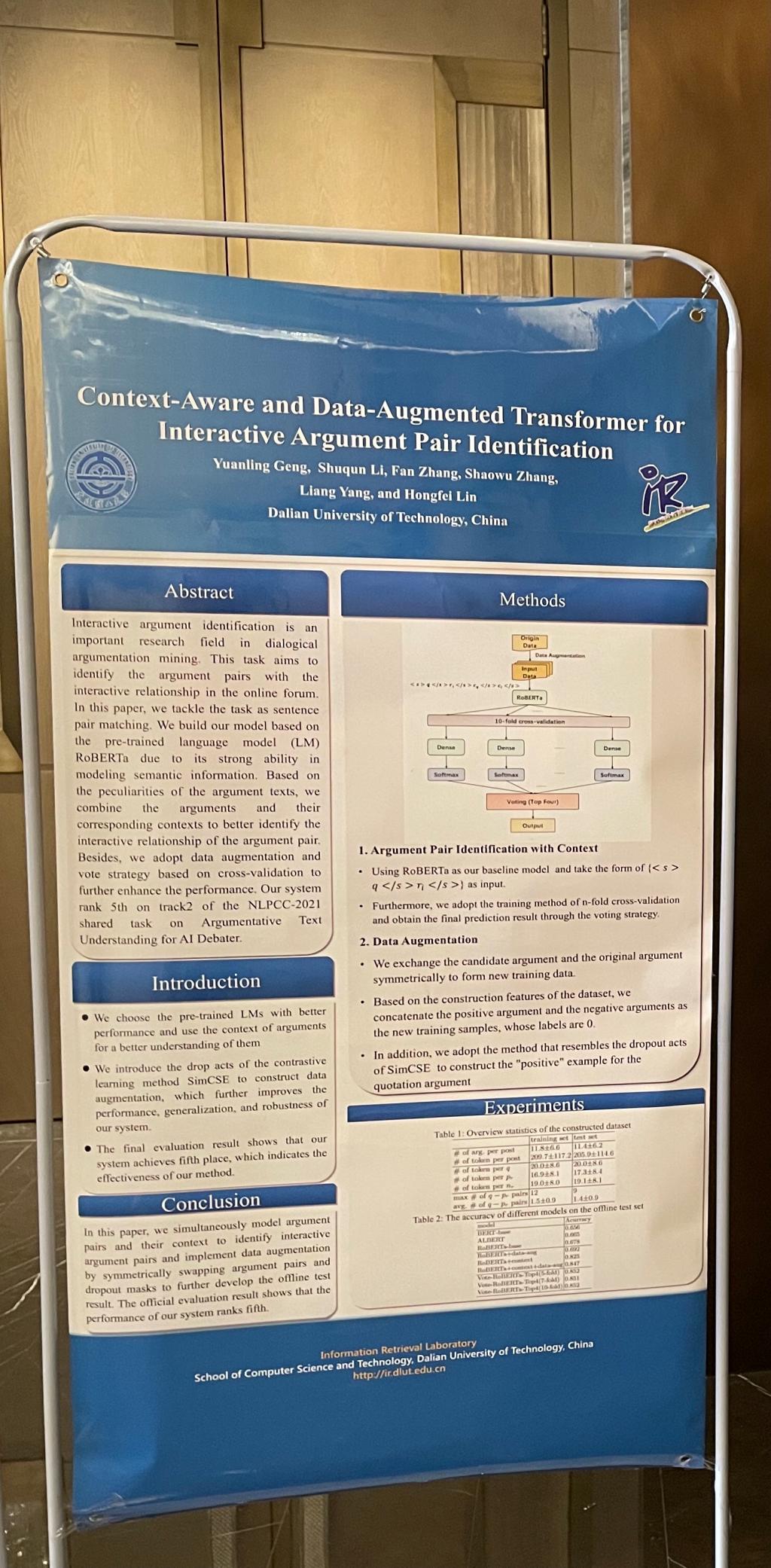
(3)Yuanling Geng, Shuqun Li, Fan Zhang, Shaowu Zhang, Liang Yang, Hongfei Lin,Context-Aware and Data-Augmented Transformer for Interactive Argument Pair Identification. NLPCC (2) 2021: 579-589
交互式论证识别是对话论证挖掘中的一个重要研究领域。此任务旨在识别在线论坛中具有交互关系的论点对。在本文中,我们将任务作为句子对匹配来处理。由于预训练语言模型 (LM) RoBERTa强大的语义信息建模能力,我们基于其构建我们的模型。基于论点文本的特点,我们将论点及其对应的上下文结合起来,以更好地识别论点对的交互关系。此外,我们根据任务数据集的特点构建负例,引入对比学习的方法构建正例以实现数据增强且基于交叉验证的投票策略来进一步提高模型的性能。最终,我们的系统在 NLPCC-2021 人工智能辩论的论证文本理解共享任务的 track2 中排名第 5。
NLPCC(CCF International Conference on Natural Language Processing and Chinese Computing)是中国计算机学会列入推荐会议C类。我们实验室参加迄今为止的所有会议,并且于2017年在大连金融国际会议中心承办了NLPCC2017,林鸿飞老师任CCF自然语言处理专委会常务委员,杨亮老师任专委会委员。
