近日,EMNLP 2025 公布了录用论文列表,实验室三篇长文被录用,包括一篇主会,两篇 findings。EMNLP 是自然处理领域的顶级会议,在 CCF 推荐列表中认定为 B 类国际学术会议,在学界和业界享有盛誉。
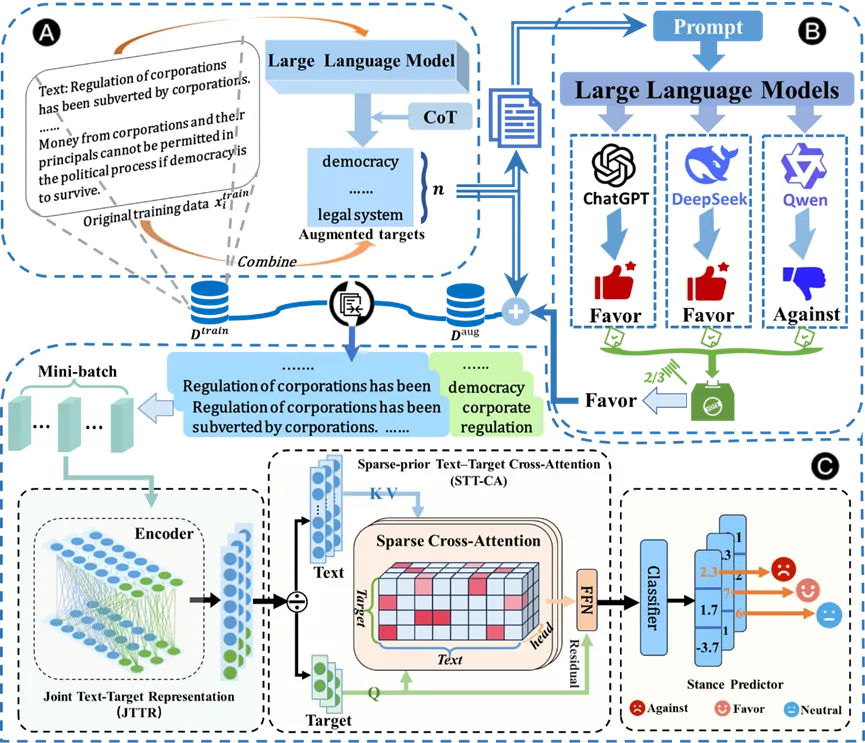
1. 基于大模型的隐式目标增强与细粒度语境建模的零样本与少样本立场检测
标题:LLM-Driven Implicit Target Augmentation and Fine-Grained Contextual Modeling for Zero-Shot and Few-Shot Stance Detection
作者:硕士生季延旭 等
摘要:立场检测旨在识别文本中针对特定目标所表达的立场。近期关于零样本和少样本立场检测的研究主要集中于从显式目标中学习泛化表示。然而,这类方法往往忽视了隐式但语义上重要的目标,并且未能充分利用细粒度的语境线索,从而限制了模型在复杂场景下的表现。为克服这些局限,我们提出了一个新颖的两阶段框架:首先,设计一种名为分层协作式目标增强框架 HCTA, 借助大语言模型,通过思维链提示与多智能体投票来识别并标注隐式目标,从而显著丰富训练数据中的潜在语义关系。其次,我们提出细粒度语境感知的注意力网络 FiCAN,该模型结合联合的文本-目标编码与稀疏交叉注意力机制,能够选择性地捕捉关键的细粒度语境线索。在基准数据集上的实验结果表明,我们的方法取得了最新的先进性能,验证了隐式目标增强与细粒度上下文建模的有效性。
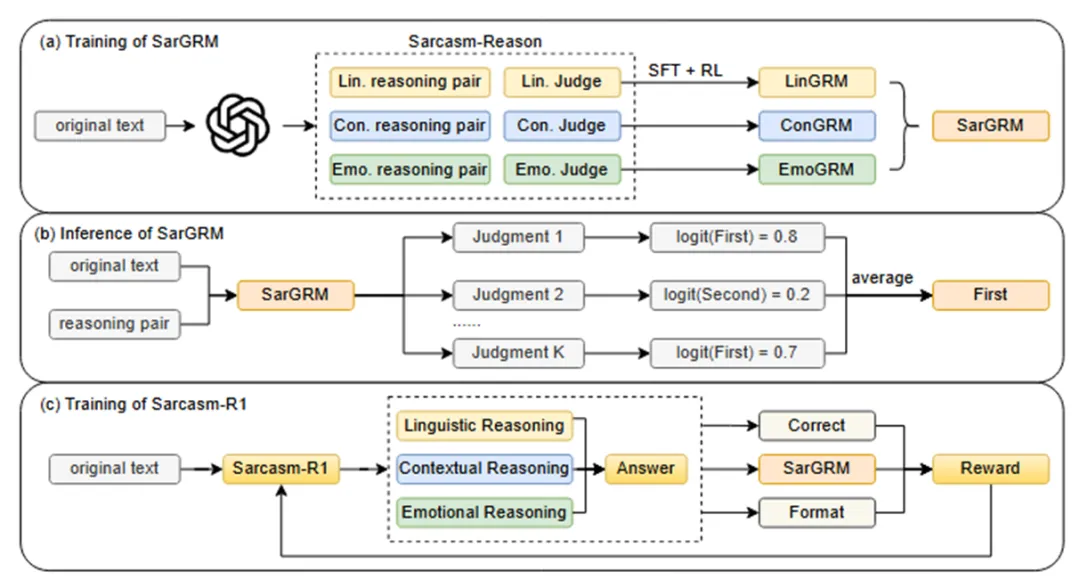
2. Sarcasm-R1:通过聚焦式推理提升反讽检测能力
标题:Sarcasm-R1: Enhancing Sarcasm Detection through Focused Reasoning
作者:硕士生杨琦 等
摘要:反讽检测是自然语言处理中一项关键且具有挑战性的任务。现有方法主要依赖于监督学习或提示工程,往往难以捕捉有效反讽检测所需的复杂推理过程。本文提出了一种新颖方法,将反讽检测分解为语言、情境和情感三个基本维度,精细建模反讽推理过程。为提升推理质量,我们采用强化学习算法并为每个维度设计了定制化的奖励模型。我们使用五个广泛采用的反讽检测数据集,并从三个维度标注反讽推理过程以提升奖励模型性能。实验表明,我们的方法在多数情况下优于最先进的基线方法。此外,我们发现了情感对比在反讽检测中的核心作用:情感冲突通过语言和情境线索得以体现,这正是反讽机制的核心特征。本研究通过实证揭示了反讽的形成机制,强调了情感对比的核心地位及其与语言、情境要素的协同作用。
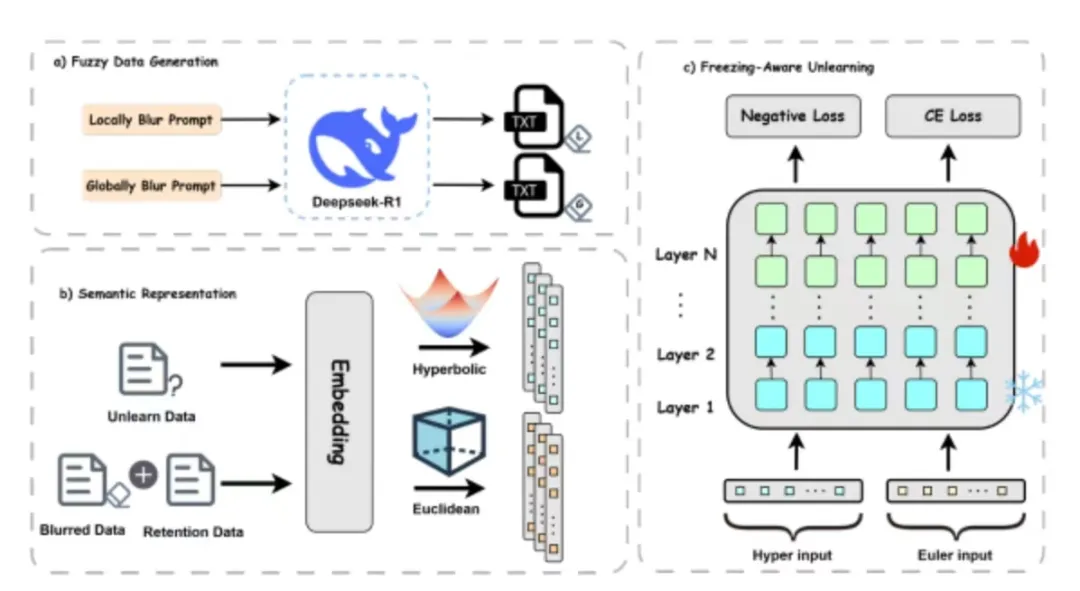
3. 基于人类遗忘模糊的模型遗忘学习:结合双曲表征的局部和全局策略
标题:Human-Inspired Obfuscation for Model Unlearning: Local and Global Strategies with Hyperbolic Representations
作者:硕士生王泽坤 等
摘要:大语言模型(LLM)凭借海量数据训练在各领域展现出卓越性能,但同时也引发了对敏感与隐私信息泄露的日益担忧,这使得机器遗忘技术变得愈发关键。然而,现有方法往往难以平衡有效遗忘与模型效用保持之间的矛盾。本研究提出受人类启发的遗忘框架HyperUnlearn:通过构建局部与全局两类模糊数据模拟遗忘过程,并分别在双曲空间与欧氏空间中进行表征。该框架对早期层冻结的模型执行遗忘操作,以隔离遗忘效应并保留有用知识。实验表明,HyperUnlearn在保持模型语言理解能力、流畅性及基准性能的同时,能有效遗忘敏感内容,为遗忘与能力保存提供了实用化的平衡方案。